Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases를 사용하여 회사의 프라이빗 데이터 소스의 컨텍스트 정보를 파운데이션 모델과 에이전트에 제공하여 연관성 높고 정확한 맞춤형 응답 제공
엔드 투 엔드 RAG 워크플로에 대한 완전관리형 지원
파운데이션 모델(FM)에 최신 독점 정보를 제공하기 위해 조직에서는 회사 데이터 소스에서 데이터를 가져와 프롬프트를 보강하여 보다 관련성이 높고 정확한 응답을 제공하는 기술인 검색 증강 생성(RAG)을 사용합니다. Amazon Bedrock Knowledge Bases는 세션 컨텍스트 관리 및 소스 속성 기능이 내장된 완전관리형 기능으로, 데이터 소스에 대한 맞춤형 통합을 구축하고 데이터 흐름을 관리하지 않고도 수집에서 검색 및 프롬프트 증강까지 전체 RAG 워크플로를 구현하도록 돕습니다. 또한 벡터 데이터베이스를 설정하지 않고도 단일 문서에서 질문을 하고 데이터를 요약할 수 있습니다. 데이터에 정형 소스가 포함된 경우 Amazon Bedrock Knowledge Bases는 데이터를 다른 저장소로 이동할 필요 없이 데이터를 검색하는 쿼리 명령을 생성할 수 있도록 정형 쿼리 언어 솔루션에 내장된 관리형 자연어를 제공합니다.
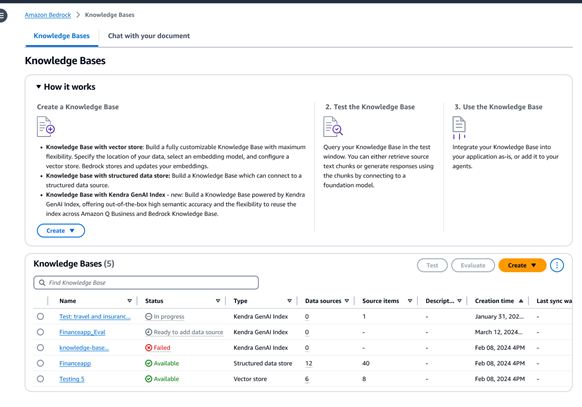
FM 및 에이전트를 데이터 소스에 안전하게 연결
비정형 데이터 소스가 있는 경우 Amazon Bedrock Knowledge Bases는 Amazon Simple Storage Service(Amazon S3), Confluence(평가판), Salesforce(평가판), SharePoint(평가판) 또는 웹 크롤러(평가판)와 같은 소스에서 데이터를 자동으로 가져옵니다. 또한 고객이 지원되지 않는 소스의 데이터 또는 스트리밍 데이터를 수집할 수 있도록 프로그래밍 방식의 문서 수집 기능도 제공됩니다. 콘텐츠가 수집되면 Amazon Bedrock Knowledge Bases는 콘텐츠를 텍스트 블록으로 변환하고, 텍스트를 임베딩으로 변환하며, 임베딩을 벡터 데이터베이스에 저장합니다. Amazon Aurora, Amazon Opensearch Serverless, Amazon Neptune Analytics, MongoDB, Pinecone, Redis Enterprise Cloud 등 지원되는 여러 벡터 저장소 중에서 선택할 수 있습니다. 관리형 검색을 위해 Amazon Kendra 하이브리드 검색 인덱스에 연결하도록 선택할 수도 있습니다.
Amazon Bedrock Knowledge Bases를 사용하면 정형 데이터 저장소에 연결하여 그라운딩된 응답을 생성할 수도 있습니다. 이 기능은 데이터 웨어하우스 및 데이터 레이크에 저장된 트랜잭션 세부 정보와 같은 소스 자료가 있을 때 특히 유용할 수 있습니다. Amazon Bedrock Knowledge Bases는 자연어를 SQL에 사용하여 쿼리를 SQL 명령으로 변환하고 명령을 실행하여 소스에서 데이터를 이동할 필요 없이 데이터를 검색합니다.
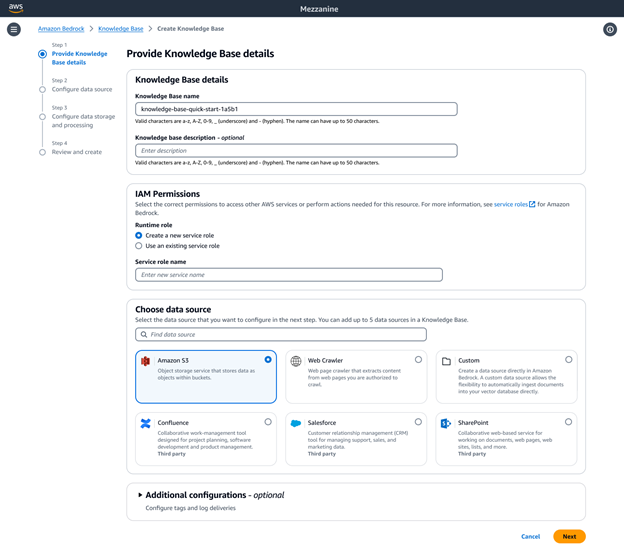
Amazon Bedrock Knowledge Bases를 사용자 지정하여 런타임에 정확한 응답 제공
Amazon Bedrock Knowledge Bases를 완전관리형 RAG 솔루션으로 사용하면 검색을 유연하게 사용자 지정하고 검색 정확도를 개선할 수 있습니다. 레이아웃이 복잡한 이미지, 시각적으로 풍부한 문서(예: 표, 그림, 차트 및 다이어그램이 포함된 문서) 등의 멀티모달 데이터를 포함하는 비정형 데이터 소스의 경우 기술 자료를 구성하여 의미 있는 인사이트를 구문 분석, 분석 및 추출할 수 있습니다. Bedrock Data Automation 또는 파운데이션 모델을 파서로 선택할 수 있습니다. 이렇게 하면 복잡한 멀티모달 데이터를 원활하게 처리할 수 있으므로 매우 정확한 생성형 AI 애플리케이션을 빌드할 수 있습니다.
Amazon Bedrock Knowledge Bases는 의미 체계, 계층 및 고정 크기 청크를 비롯하여 다양한 고급 데이터 청킹 옵션을 제공합니다. 완전한 제어를 위해 자체 청킹 코드를 Lambda 함수로 작성하고 LangChain, LlamaIndex 등 프레임워크의 상용 구성 요소를 사용할 수도 있습니다. Amazon Neptune Analytics를 벡터 저장소로 선택하면 Amazon Bedrock Knowledge Bases가 데이터 소스 전반에서 관련 콘텐츠를 연결하는 임베딩 및 그래프를 자동으로 생성합니다. Bedrock Knowledge Bases는 GraphRAG와의 이러한 콘텐츠 관계를 활용하여 검색의 정확도를 개선함으로써 최종 사용자에게 보다 포괄적이고 관련성이 높으며 설명 가능한 응답을 제공합니다.
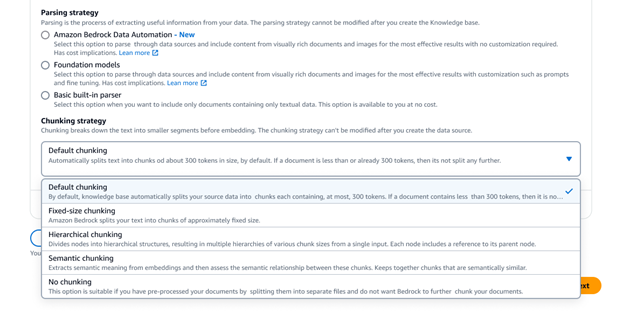
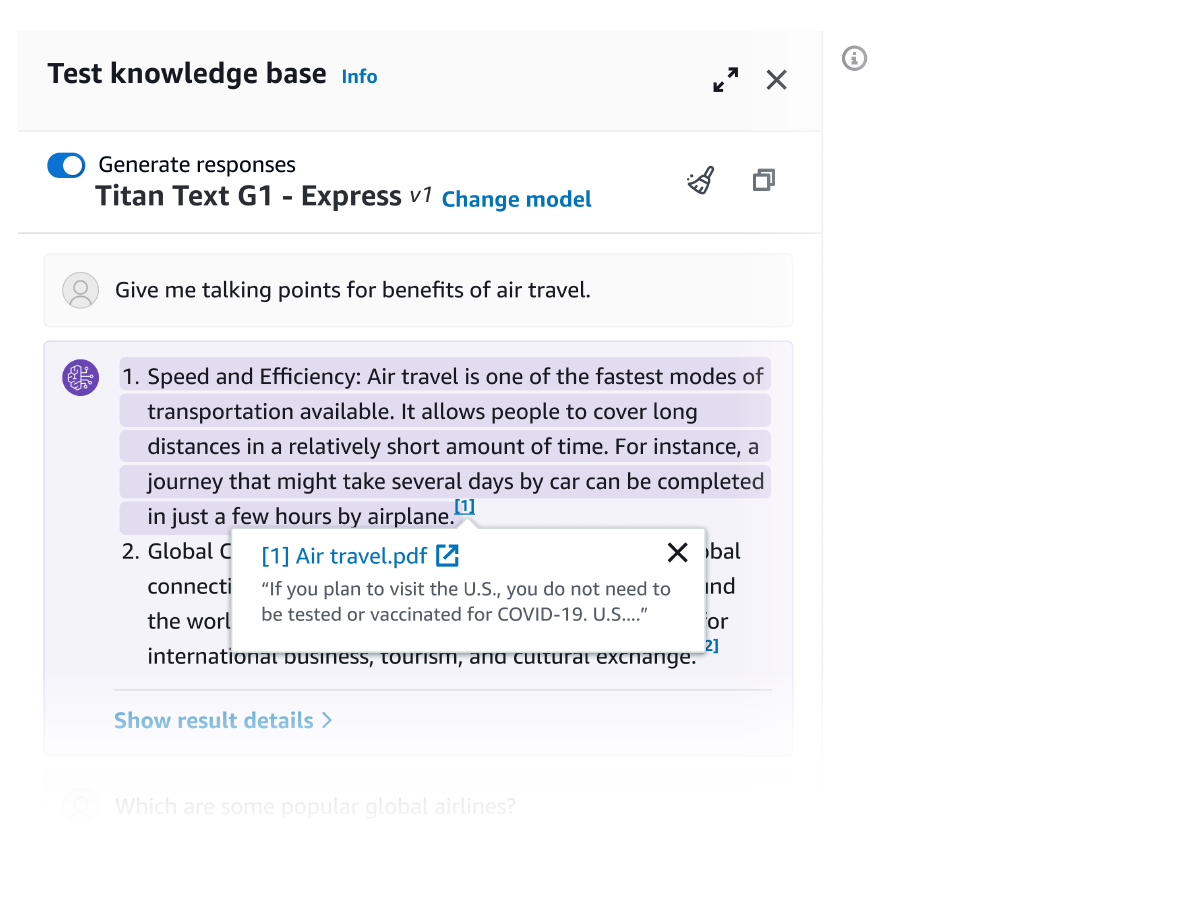
데이터 검색 및 프롬프트 보강
Retrieve API를 사용하면 이미지, 다이어그램, 차트, 표, 오디오 및 비디오 콘텐츠 등의 시각적 요소나 데이터베이스의 정형 데이터(해당하는 경우)를 비롯하여 지식 기반에서 사용자 쿼리와 관련된 결과를 가져올 수 있습니다. 한 단계 더 발전한 RetrieveAndGenerate API는 검색된 멀티모달 결과를 직접 사용하여 FM 프롬프트를 보강하고 응답을 반환합니다. 필터를 제공하거나 FM을 사용하여 관련 콘텐츠로만 반환되는 결과를 제한하는 암시적 필터를 생성할 수도 있습니다. Amazon Bedrock 지식 베이스는 텍스트, 시각적, 멀티미디어 콘텐츠 전반에서 검색된 문서 청크의 관련성을 향상시키기 위해 재순위 지정 모델을 제공합니다.
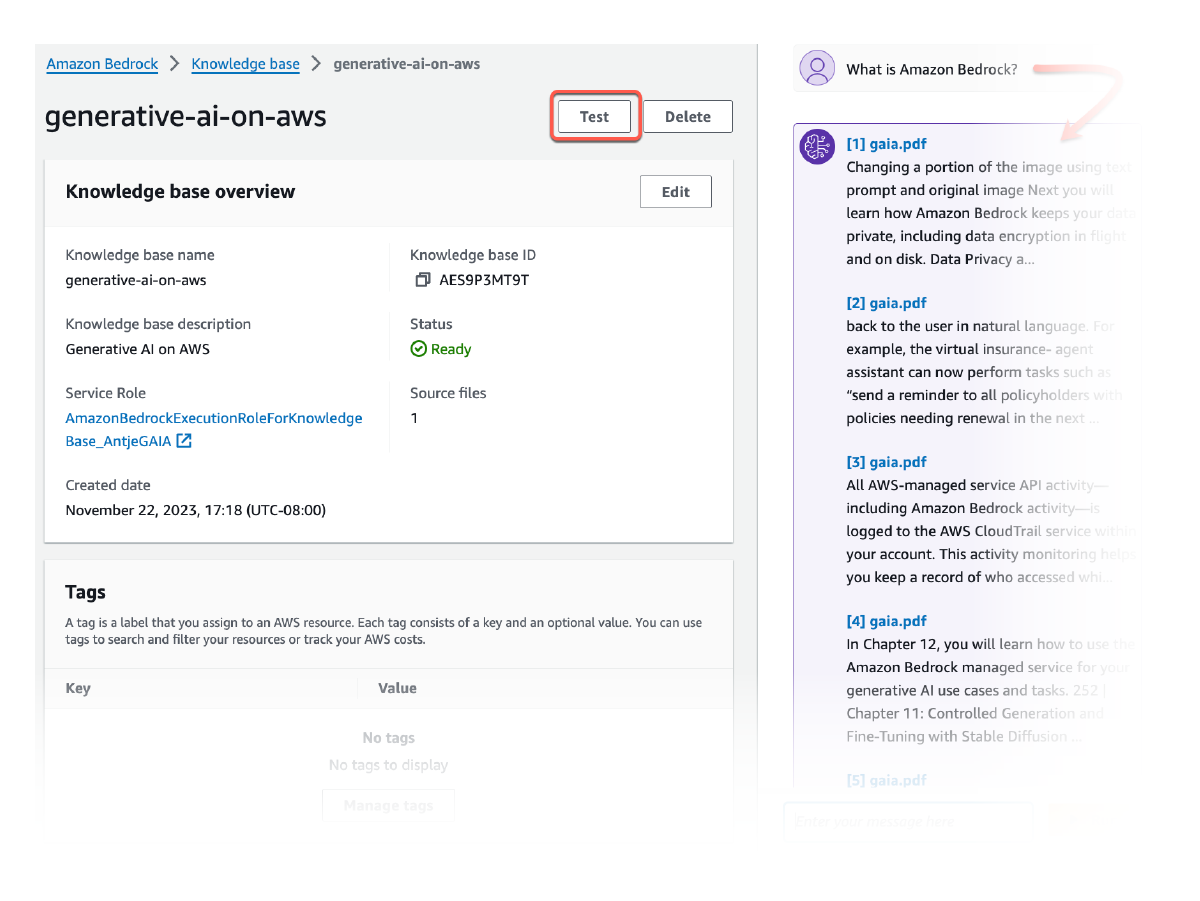
소스 저작자 표시
Amazon Bedrock Knowledge Bases의 모든 정보는 투명성을 높이고 할루시네이션을 최소화하기 위해 참고 문헌(시각적 자료도 포함)과 함께 제공됩니다.
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내주세요.