AWS 기술 블로그
Amazon EKS에서 NVIDIA OSMO 기반 Physical AI 워크플로 운영하기
Physical AI를 위한 모델 개발 과정은 일반적으로 데이터 수집, 시뮬레이션, 정책 학습, 엣지 배포가 반복되는 긴 라이프사이클을 갖습니다. 또한, 각 단계는 서로 다른 컴퓨팅, 스토리지, 모니터링에 대한 요구사항을 갖습니다. PoC 단계에서는 단일 GPU 인스턴스에서 학습을 실행하는 것만으로도 충분할 수 있지만, 여러 데이터셋과 모델 버전으로 같은 워크플로를 반복 실행하려면 실행 환경, 아티팩트 보존, 관찰 가능성, 보안, 버전 호환성을 일관된 방식으로 관리할 필요가 있습니다.
특히 최근 로보틱스 영역에서는 NVIDIA Isaac GR00T, NVIDIA Cosmos 등의 모델과 NVIDIA Isaac Lab 시뮬레이션 스택이 많이 사용되며, 반복적인 워크플로에 대한 오케스트레이션을 위해 NVIDIA OSMO 와 같은 프레임워크도 등장하고 있습니다.
이 글에서는 Physical AI 워크로드를 Amazon Elastic Kubernetes Service(Amazon EKS) 위에서 운영하려는 인프라/MLOps 엔지니어를 대상으로 NVIDIA OSMO를 안전하고 효율적으로 운영하기 위한 레퍼런스 아키텍처를 소개합니다.
이 아키텍처는 NVIDIA OSMO를 외부 의존성으로 유지하고, Karpenter 기반 Amazon EC2 G family GPU 인스턴스(ex, G6, G6e, G7e) 용량 관리, KAI Scheduler, NVIDIA GPU Operator, AWS 관리형 백엔드 서비스, Amazon Managed Service for Prometheus(AMP) 및 Amazon Managed Grafana(AMG), Elastic Fabric Adapter(EFA) 등으로 구성됩니다.
이를 통해 GPU 스케줄링, 워크플로 아티팩트 보존, 관찰 가능성, 보안, 환경 구성을 하나의 반복 가능한 운영 패턴으로 다룰 수 있게 됩니다.
아키텍처 개요
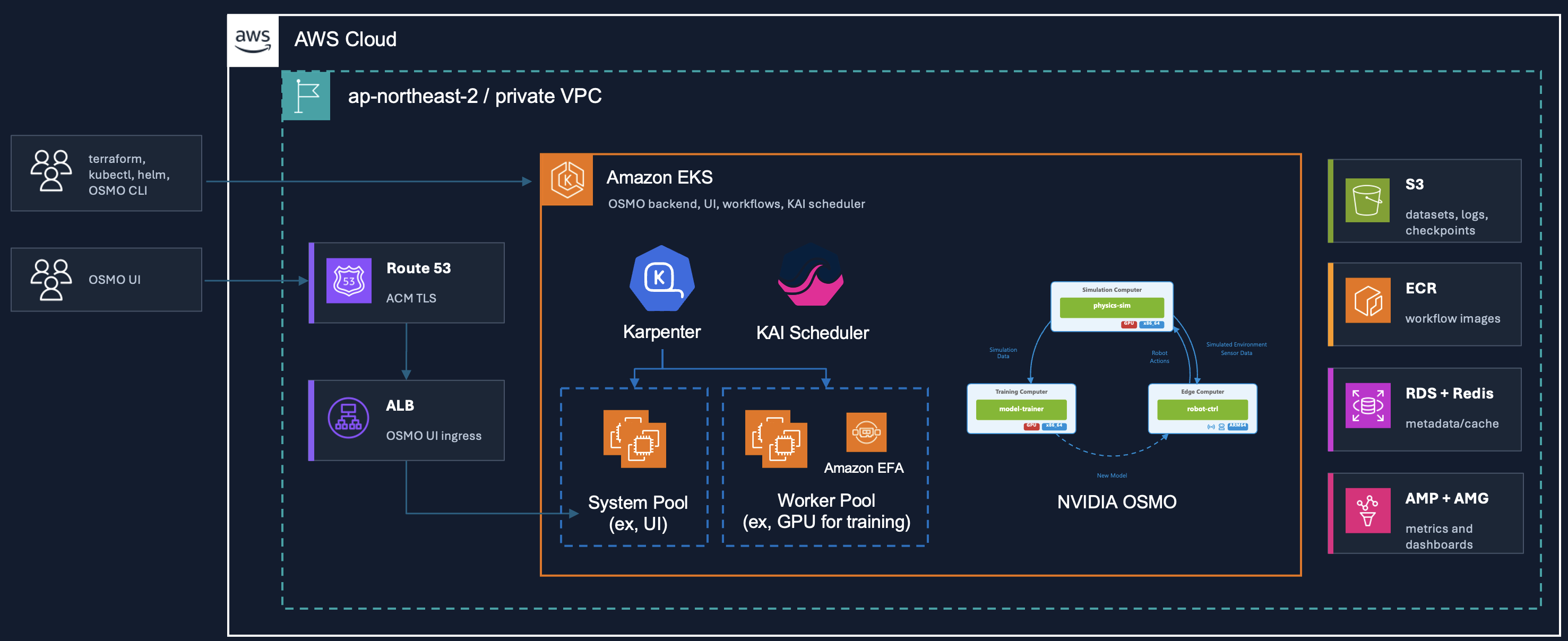
<그림 1. 레퍼런스 아키텍처>
Day 2 운영에서는 인프라, GPU 실행 환경, 스케줄링, 워크플로 오케스트레이션, 아티팩트 저장, 관찰 가능성이 서로 다른 주기로 변경됩니다. 레퍼런스 아키텍처는 각 구성 요소의 역할을 명확히 구분해, 변경이 발생했을 때 어떤 경로를 검증해야 하는지 명확히 하는 것을 목표로 합니다.
주요 구성 요소는 다음과 같습니다.
기반 인프라:
- Amazon EKS: 관리형 Kubernetes 컨트롤 플레인을 제공하며, NVIDIA OSMO와 워크플로 파드는 EC2 워커 노드에서 실행됩니다.
- AWS 관리형 백엔드 서비스: Amazon RDS, Amazon ElastiCache, Amazon S3, Amazon ECR, AWS KMS, AWS Secrets Manager를 사용해 메타데이터, 아티팩트, 이미지, 시크릿을 저장하고 보존합니다.
- Amazon Managed Service for Prometheus 및 Amazon Managed Grafana: 워크플로, 클러스터, GPU 메트릭을 수집하고 시각화합니다.
GPU 실행 환경:
- Karpenter: 워크플로가 요청한 GPU capacity에 맞춰 Amazon EC2 GPU 노드를 생성하고, 사용이 끝난 노드를 회수합니다.
- NVIDIA GPU Operator: Kubernetes에 GPU 리소스를 노출하고 DCGM 기반 GPU 텔레메트리를 제공합니다. 드라이버와 컨테이너 툴킷은 EKS NVIDIA AMI에 포함되어 있으므로 GPU Operator에서는 비활성화합니다.
- Elastic Fabric Adapter(EFA): 지원되는 G family 인스턴스에서 분산 학습과 통신 중심 워크로드를 위한 네트워크 가속을 제공합니다.
워크플로 실행 경로:
- KAI Scheduler: NVIDIA OSMO 워크플로가 사용하는 Kubernetes 스케줄링 경로를 담당합니다. PodGroup CRD와 gang scheduling 동작을 처리합니다.
- NVIDIA OSMO: 워크플로 오케스트레이션, 메타데이터 관리, 사용자 인터페이스를 담당합니다. 본 구성에서는 업스트림 의존성으로 유지하고 버전을 고정합니다.
전체 아키텍처 배포를 위해서는 Terraform으로 AWS 인프라를 생성하고, Helm과 kubectl로 Kubernetes 구성 요소를 단계적으로 설치합니다. 코어 인프라, Karpenter, NVIDIA GPU Operator, EFA 디바이스 플러그인, KAI Scheduler, NVIDIA OSMO 배포 단계를 분리하여 특정 구성 요소를 변경한 뒤 필요한 검증만 반복할 수 있습니다. 예를 들어 NVIDIA GPU Operator 차트를 업그레이드할 때는 GPU 리소스 노출, DCGM 메트릭, GPU smoke test를 중심으로 검증하고, NVIDIA OSMO 버전을 변경할 때는 워크플로 제출, 스케줄링, 아티팩트 저장, UI/API 동작을 중심으로 검증합니다.
기본 구성은 AWS 관리형 백엔드 서비스, private networking, 암호화를 활용합니다. NVIDIA OSMO는 차트 내부 PostgreSQL과 Redis 대신 Amazon RDS와 Amazon ElastiCache를 사용하고, 워크플로 아티팩트는 Amazon S3에 저장하며, 시크릿은 AWS Secrets Manager와 Kubernetes Secret을 통해 주입합니다. 보안 강화를 위해 Amazon EKS API 엔드포인트와 노드는 프라이빗 네트워크에 두고, Amazon RDS와 Amazon ElastiCache는 퍼블릭 액세스를 허용하지 않으며, Amazon S3는 퍼블릭 액세스 차단을 적용합니다. 또한 Amazon S3, Amazon RDS, Amazon ElastiCache, Amazon ECR, AWS Secrets Manager, 노드 루트 볼륨은 암호화하고, EC2 노드는 IMDSv2를 사용하도록 구성합니다. 외부 인그레스는 기본값에서 비활성화하고, 필요한 환경에서만 별도 인그레스 구성을 추가합니다.
OSMO 워크플로 개요
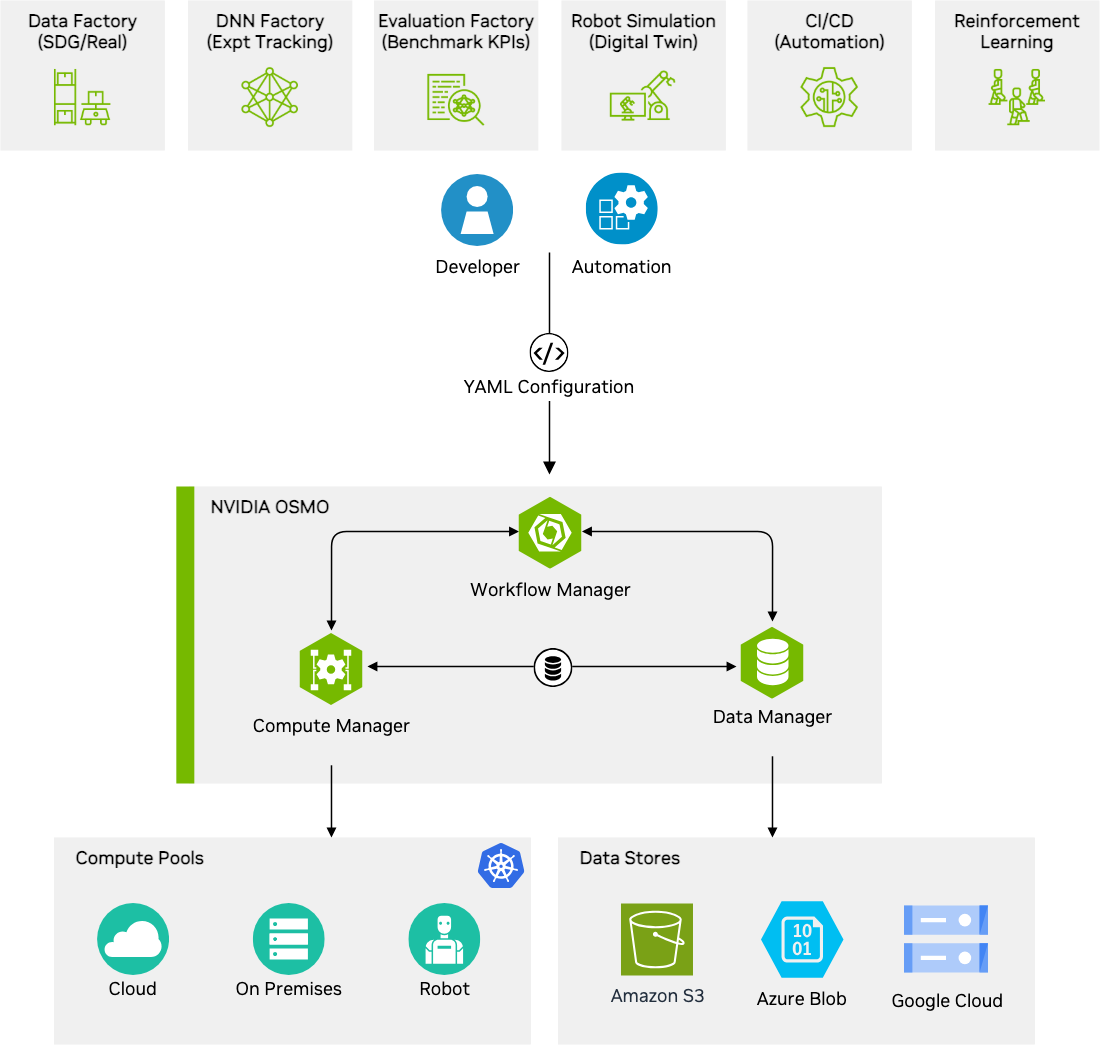
<그림 2. NVIDIA OSMO 개요 (출처: NVIDIA OSMO User Guide)>
{kind=link}
NVIDIA OSMO는 Physical AI 개발 과정에서 반복되는 워크플로를 YAML로 정의하고 실행하는 오케스트레이션 프레임워크입니다. 원격 GPU 노드에서의 인터랙티브 개발, Isaac Sim 기반 합성 데이터 생성, 분산 GPU 클러스터에서의 모델 학습 (ex, 강화학습), 시뮬레이션 및 hardware-in-the-loop 검증, 데이터 변환과 후처리, 실제 로봇 하드웨어 테스트처럼 서로 다른 유형의 작업을 하나의 워크플로 모델로 다룰 수 있습니다.
이 구조의 장점은 다양한 Physical AI 작업을 같은 방식으로 정의하면서도, 컴퓨팅 리소스와 데이터 저장소를 분리해 관리할 수 있다는 점입니다. 개발자는 YAML에서 작업 순서, 리소스 요구사항, 입력과 출력을 정의하고, OSMO는 이를 compute pool과 data store에 연결해 실행합니다. 이 글의 레퍼런스 아키텍처에서는 compute pool을 Amazon EKS와 Karpenter 기반 G family GPU 노드로, data store를 Amazon S3 기반 아티팩트 저장소로 매핑합니다. 따라서 같은 워크플로를 다른 GPU platform에서 실행하거나, 특정 단계의 출력 데이터셋을 다음 단계와 다음 실행에서 재사용하는 방식으로 Physical AI 실험을 반복 가능한 워크플로 형태로 관리할 수 있습니다.
OSMO CLI와 워크플로 YAML
OSMO에서 운영자가 주로 다루는 인터페이스는 두 가지입니다. 하나는 워크플로를 제출하고 상태와 로그를 확인하는 OSMO CLI이고, 다른 하나는 워크플로 구조를 정의하는 YAML 파일입니다. YAML에는 실행할 컨테이너 이미지, 필요한 CPU·GPU·메모리·스토리지, 작업 간 의존성, 출력 데이터셋이 정의됩니다. 실행마다 달라지는 학습 스텝 수, 모델 경로, 출력 데이터셋 이름은 제출 시점에 오버라이드할 수 있으므로, 같은 워크플로 정의를 여러 실험에 재사용할 수 있습니다.
아래는 단일 GPU fine-tuning 워크플로를 단순화한 예입니다. 실제 예제는 리포지토리의 examples/ 디렉터리에 포함되어 있습니다.
리소스 풀과 플랫폼 매핑
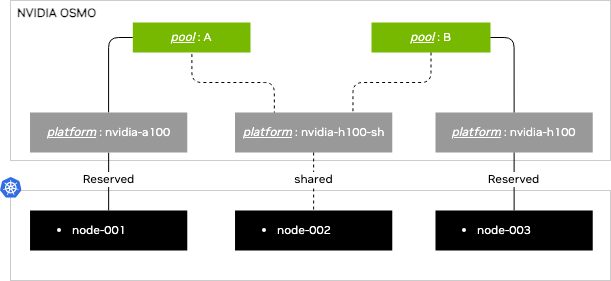
<그림 3. OSMO 리소스 풀과 플랫폼의 계층 구조. 출처: NVIDIA OSMO User Guide>
OSMO에서 워크플로가 사용할 실행 리소스는 pool과 platform으로 구분됩니다. pool은 여러 사용자가 공유하는 리소스 그룹이자 워크플로 제출 대상이고, platform은 그 pool 안에서 특정 하드웨어 유형을 나타내는 실행 환경입니다. 따라서 osmo workflow submit workflow.yaml --pool default로 워크플로를 제출하면 OSMO는 default pool 안에서 워크플로의 resources.platform 값에 해당하는 platform을 찾고, 해당 platform의 접근 정책과 pod template을 기준으로 Kubernetes pod를 생성합니다.
운영 관점에서는 워크플로 YAML의 resources.platform 값을 통해 워크플로를 어느 G family GPU 인스턴스 풀에서 실행할지 제어합니다. 이 레퍼런스에서는 배포 단계에서 OSMO config API를 사용해 default pool에 g7e-rtx-pro-6000, g6e-l40s, g6e-l40s-efa 같은 platform을 등록합니다. 각 platform은 필요에 따라 override_pod_template으로 OSMO Pod Template을 참조할 수 있으며, 이 경우 해당 template에 정의된 Kubernetes pod 설정이 워크플로 pod 생성 시 함께 적용됩니다. 예를 들어 g6e-l40s-efa는 EFA를 사용하는 G6e L40S 실행 환경을 정의하며, 그 안에 정의된 OSMO Pod Template에는 Karpenter G6e NodePool을 선택하기 위한 nodeSelector, GPU/EFA toleration, vpc.amazonaws.com/efa 리소스 요청, /dev/shm 볼륨, 멀티 노드 rank를 서로 다른 노드에 배치하기 위한 pod anti-affinity가 포함됩니다
위 예시는 g6e-l40s-efa라는 platform에 커스텀 OSMO Pod Template을 연결하는 방식을 단순화해 보여줍니다. 이와 같이 platform을 설정한 후 작업 제출자가 워크플로 YAML에서 platform: g6e-l40s-efa를 지정하면, OSMO는 pool 설정의 override_pod_template을 통해 aws-g6e-l40s-efa Pod Template을 적용합니다. 그 결과 workflow pod에는 G6e EFA 노드 배치를 위한 nodeSelector, GPU/EFA toleration, EFA 리소스 요청, pod anti-affinity 같은 Kubernetes 설정이 함께 반영됩니다.
GPU 워크플로 실행 경로
<그림 4. OSMO UI Workflows 화면 예시>
GPU 워크플로가 제출되면 OSMO backend는 각 task를 Kubernetes pod로 생성하고, KAI Scheduler는 PodGroup CRD와 gang scheduling을 처리합니다. 앞서 설명한 platform과 Pod Template 설정에 따라 workflow pod에는 GPU NodePool 선택, GPU taint에 대응되는 toleration, karpenter.sh/do-not-disrupt=true annotation, /dev/shm 볼륨 같은 Kubernetes 설정이 적용됩니다. 이를 통해 GPU 워크플로는 시스템 노드가 아니라 대상 GPU NodePool에 배치되고, 장시간 실행되는 학습 pod가 Karpenter의 voluntary disruption으로 중단되지 않도록 보호할 수 있습니다.
스케줄링 가능한 pending pod가 생성되면 Karpenter는 조건에 맞는 Amazon EC2 G family 인스턴스를 생성합니다. 노드가 클러스터에 조인하면 NVIDIA GPU Operator가 nvidia.com/gpu 리소스와 DCGM 기반 GPU 텔레메트리를 제공합니다. 이 레퍼런스에서는 드라이버와 컨테이너 툴킷 설치를 GPU Operator에서 비활성화하고, EKS NVIDIA AMI에 포함된 드라이버와 툴킷을 사용합니다. 워크플로가 완료되면 task pod가 종료되고, Karpenter는 빈 GPU 노드를 회수합니다.
단, OSMO는 workflow 제출 시점에 pool/platform의 가용 리소스를 검증하므로, GPU 노드가 scale-to-zero 상태인 환경에서는 Karpenter가 노드를 생성하기 전에 제출이 거부될 수 있습니다. 이 레퍼런스에서는 GPU workflow 제출 전에 짧은 prewarm pod를 실행해 대상 platform capacity를 OSMO에 먼저 노출하는 방식을 사용합니다.
응용 패턴 및 운영 고려사항
OSMO 워크플로는 단일 작업 실행뿐 아니라 여러 작업을 연결하는 파이프라인으로 사용할 수 있습니다. 이 레퍼런스에서는 크게 두 가지 패턴을 사용합니다. 하나는 작업을 순서대로 연결하는 순차 실행 패턴이고, 다른 하나는 여러 작업을 동시에 실행하는 병렬 실행 패턴입니다. 두 패턴 모두 각 작업의 리소스와 platform을 명시하고, 작업 간 입력과 출력을 OSMO 데이터셋으로 연결합니다.
순차 실행 패턴
순차 실행 패턴은 데이터 생성, 변환, 증강, 학습처럼 단계가 명확히 이어지는 워크플로에 적합합니다. nut-pouring 파이프라인 예제는 이 패턴의 대표 사례입니다. 이 워크플로는 MimicGen, HDF5 to MP4 변환, Cosmos Transfer 증강, MP4 to HDF5 변환, LeRobot 변환, GR00T fine-tuning 단계로 이어집니다. 각 단계의 출력은 OSMO 데이터셋으로 등록되고 다음 단계의 입력으로 사용됩니다.
아래는 nut-pouring 파이프라인 중 LeRobot 변환 단계가 앞 단계의 HDF5 데이터셋을 입력으로 받아 다음 GR00T 학습 단계에서 사용할 데이터셋을 생성하는 흐름을 단순화한 예입니다.
이어지는 GR00T fine-tuning 단계는 변환된 LeRobot 데이터셋을 입력으로 사용하고, 학습 결과를 다시 OSMO 데이터셋으로 등록합니다.
이 구조를 사용하면 데이터 변환과 학습 결과가 각각 명시적인 OSMO 데이터셋으로 남습니다. 특정 단계만 다시 실행하거나, 다른 증강 데이터셋으로 같은 GR00T fine-tuning 단계를 반복하는 운영 방식도 가능합니다.
병렬 실행 패턴
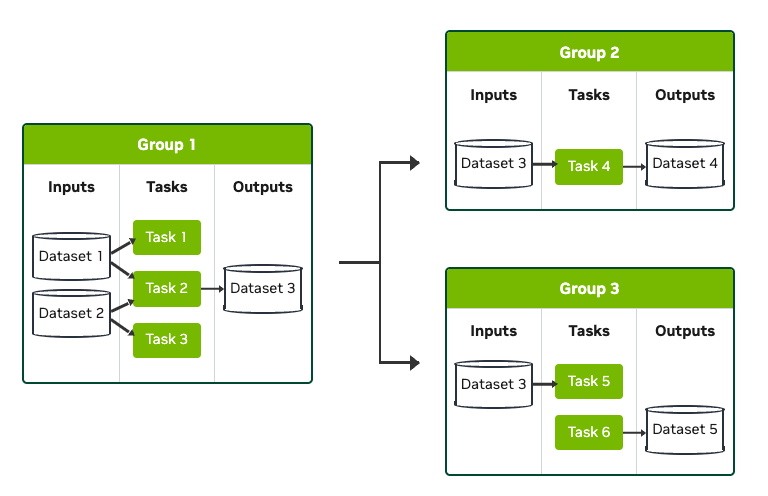
<그림 5. OSMO group 기반 병렬 실행 패턴 예시. 출처: NVIDIA OSMO User Guide>
병렬 실행 패턴은 여러 task가 동시에 실행되어야 하는 워크플로에 사용합니다. OSMO의 groups는 여러 task를 하나의 실행 단위로 묶고, KAI Scheduler는 이를 PodGroup 기반으로 처리합니다. 예를들어, GR00T SO100 EFA multi-node fine-tuning 예제에서는 하나의 OSMO group 안에 master와 worker task를 두고, 두 task를 EFA-capable G6e 노드에 배치합니다.
아래는 실제 multi-node 워크플로의 핵심 구조입니다.
이 방식은 OSMO 워크플로 안에서 torchrun --nnodes=2 --nproc_per_node=1 형태의 GR00T 학습을 실행합니다. master task는 lead: true로 지정되고, worker는 MASTER_ADDR: "{{host:master}}"를 사용해 master task로 rendezvous합니다. 두 task 모두 앞서 설명한 g6e-l40s-efa platform을 사용하여, EFA Pod Template을 사용해 각 rank를 EFA-capable G6e 노드에 배치됩니다. 따라서 각 task는 GPU 1개와 EFA-capable 노드 배치를 전제로 실행됩니다. 이때 OSMO는 group 단위 실행, task 간 host 참조, rank-0 artifact upload를 처리하고, KAI Scheduler와 Karpenter는 스케줄링과 GPU 노드 프로비저닝을 담당합니다.
운영 고려사항
실제 운영 환경에서는 모니터링, 비용, 캐퍼시티를 함께 고려해야 합니다. 이 레퍼런스는 Amazon Managed Service for Prometheus와 Amazon Managed Grafana를 사용해 NVIDIA OSMO 서비스, 워크플로 pod, GPU 메트릭을 수집하고 시각화합니다. GPU 메트릭은 NVIDIA DCGM exporter를 통해 수집하며, 대시보드는 실제 워크플로 pod의 GPU utilization, memory, power, temperature를 확인할 수 있도록 구성합니다.
GPU 비용 관리를 위해 Karpenter는 워크플로가 요청할 때 GPU 노드를 생성하고, 워크플로 완료 후 빈 노드를 회수합니다. 반복 가능한 멀티 노드 실행이나 데모가 필요한 경우에는 EC2 Capacity Reservation 또는 Capacity Blocks를 사용해 필요한 GPU 인스턴스를 사전에 확보하는 방식을 고려할 수 있습니다. 만약 멀티 노드 분산 학습에서 EFA를 사용한다면 참여 노드가 동일 Availability Zone에 배치되어야 하며, 지연 시간에 민감한 NCCL 또는 MPI 워크로드는 cluster placement group을 함께 고려해야 합니다. 그리고 환경을 정리할 때는 Amazon S3, Amazon ECR, AWS Secrets Manager, 로그, OSMO 데이터셋의 보존 설정을 함께 확인하는 것이 좋습니다.
결론
Physical AI 워크플로를 PoC에서 반복 가능한 운영 모델로 확장하려면 단일 GPU 인스턴스를 넘어 워크플로 오케스트레이션, 스케줄링, 아티팩트 보존, 관찰 가능성, 보안, 비용 관리를 함께 고려해야 합니다. 이 글에서는 Amazon EKS 위에서 NVIDIA OSMO를 실행하고, Karpenter, KAI Scheduler, NVIDIA GPU Operator, AWS 관리형 서비스, AMP, AMG, EFA를 조합해 Physical AI 워크플로를 운영하는 레퍼런스 아키텍처를 소개했습니다. 보다 자세한 내용은 아래 참고자료에서 확인할 수 있습니다.
이제 직접 실습을 위해서는 샘플 코드를 클론해 레퍼런스 아키텍처를 배포하고 smoke 워크플로 기본 예제를 실행해 보세요. 이후에는 단일 GPU fine-tuning, 순차 파이프라인, 병렬 실행, 멀티 노드 EFA 학습 예제로 손쉽게 확장할 수 있습니다. 운영 환경에 적용할 때는 사용할 G family 인스턴스, OSMO platform 이름, artifact 저장 위치, 관찰 가능성 구성을 먼저 정하고, 각 워크플로의 리소스 요청과 출력 데이터셋 경로를 팀의 실험 관리 방식에 맞게 조정하는 것을 권장합니다.