AWS 기술 블로그
화장품 스마트팩토리 솔루션 전문기업 이젬코와 Amazon QuickSuite로 구현한 AI 기반 품질 데이터 분석 플랫폼

개요
이젬코 소개
이젬코는 제조 DX(디지털 트랜스포메이션) 분야에서 혁신적인 기술과 솔루션을 제공하는 소프트웨어 전문기업입니다. 산업별 제조업의 다양한 공정 구조와 규제 요구사항을 바탕으로, 연구개발부터 생산·품질·물류·수출까지 이어지는 전 제조 과정을 디지털화하는 “업종별 스마트 제조 특화 솔루션”을 자체 개발해 운영하고 있습니다.
그중에서도 화장품 산업을 중점 분야로 삼아 솔루션과 기능을 고도화해 왔으며, 이를 기반으로 식품, 건강기능식품, 자동차, 일반 제조 산업 등으로 적용 범위를 확장하면서 각 산업의 특성에 맞는 디지털 혁신을 구현하고 있습니다. 또한, 스마트팩토리·ICT 솔루션·설비 인터페이스·AI 분석·보안 DX 등 폭넓은 기술 역량을 갖추어 기업의 전사적 디지털 전환을 종합적으로 지원하고 있습니다.
이젬코의 업종별 스마트 제조 특화 솔루션은 GMP·ISO 등 산업별 규제 사항을 시스템에 통합한 제조 DX 플랫폼으로, OEM/ODM 기업이 법적 기준에 맞춰 공정을 디지털 환경에서 안정적으로 운영할 수 있도록 설계된 윈도우 기반 설치형 시스템입니다.
처방·칭량(계량)·제조·충포장·품질시험·물류·출고 등 전 공정의 제조 데이터를 단일 플랫폼에서 통합 관리하며, 실시간 데이터 기반의 공정 관리가 가능하도록 설비·센서·저울·키오스크 등 다양한 현장 장비로부터 데이터를 자동 수집하여 제조기업이 안정적이고 일관된 데이터 기반 의사결정을 수행할 수 있도록 지원합니다.
이젬코는 이러한 제조 데이터의 활용 범위를 한 단계 확장하기 위해 AWS와 협업하여 클라우드 기반 제조 데이터 분석 아키텍처를 새롭게 구축하는 것을 목표로 작업을 진행하였으며, 본 글에서는 AWS Glue·Amazon Athena·Amazon QuickSight·Amazon QuickSuite 등 AWS 서비스를 활용해 AI 데이터 분석 환경을 구현하기 위한 과정과 기술적 배경을 소개합니다.
이젬코의 고민
화장품 공장에서는 원·부자재 입하 단계부터 완제품 생산과 출하에 이르기까지 각 공정이 유기적으로 연결되어 있습니다. 특히 OEM/ODM 방식의 화장품 제조는 공정별 변수가 다양해 각 단계에서 발생하는 품질 검사 이력을 신속하게 수집하고, 이를 로트별로 정확하게 추적/분석할 수 있는 플랫폼이 필수적이었습니다. 이러한 배경에서 고객사는 생산 전 과정의 데이터를 안정적으로 관리하고, 공정 간 품질 이슈를 실시간으로 파악할 수 있는 환경을 요구했습니다.
1. 공정 간 불량률 및 로트 기반 품질 추적의 어려움
현장에서는 원료, 부자재, 내용물, 완제품을 아우르는 다양한 품목에 대해 실시간 품질 검사가 진행되고 있으며 데이터 또한 지속적으로 축적되고 있습니다. 하지만 공정 간 불량률을 분석하고 로트별 품질 편차를 추적하는 과정에서 고객이 즉시 확인하기 어려운 구간이 존재했습니다. 그 결과 특정 공정에서 발생한 불량 원인 분석이 지연되거나 불량률 상승에 대한 선제 대응이 늦어지는 문제가 반복적으로 발생했습니다. 고객사는 이러한 병목을 해소하기 위해 모든 공정·로트 데이터를 투명하고 즉각적으로 확인할 수 있는 품질 관리 환경을 필요로 했습니다.
2. 기존 BI 환경의 한계
기존에는 고객사의 요청이 있을 때마다 신규 대시보드를 별도로 개발해야 했고 이는 개발 리소스 증가, 운영 비용 확대, 분석 리드타임 지연이라는 비효율을 초래했습니다. 특히 대시보드 형태의 고정된 분석 구조는 실무자가 원하는 방식으로 데이터를 유연하게 조회/분석하는 데 제약이 컸습니다. 고객사는 이러한 문제를 해결하기 위해 생성형 AI 기반 자연어 질의만으로도 공정 간 품질 데이터를 분석하고 즉시 인사이트를 얻을 수 있는 환경이 필요했습니다. 즉, 원하는 품질 지표나 특정 로트의 불량 현황을 “대화하듯” 질의하고 즉각적으로 분석 결과를 얻는 방식의 새로운 품질 관리 기능을 구축하는 것이 목표였습니다.
Partner-led Datalab 프로그램
AWS Partner-led Data Lab은 고객사의 데이터 혁신을 가속화하기 위해 AWS 파트너가 제공하는 전문 기술 협업 프로그램입니다. AWS 파트너 전문가들과 함께 고객의 실제 비즈니스 과제를 해결하는데 중점을 두며, 특히 데이터 분석, AI/ML, 데이터베이스 설계 등의 분야에서 실질적인 결과물을 도출할 수 있도록 돕습니다. 직접 설계하고 구축하는 과정을 통해 기술 내재화가 가능하며, 빠른 시간 내에 프로토타입을 완성할 수 있다는 것이 큰 장점입니다.
이젬코는 AWS 파트너인 NDS와 함께 Partner-led Data Lab을 진행하였습니다. 고객의 비즈니스 요구사항을 정확히 파악하는 것을 시작으로, 초기 1일 동안 프로젝트의 방향을 설정하고 필요한 AWS 서비스를 검토했으며, 이어지는 3일 동안 실제 구현 단계를 진행했습니다. NDS의 전문가들과 함께 고객의 실제 환경에 맞는 아키텍처를 설계하고 구축했으며, 이후에도 AWS 팀과 협력하여 안정적인 운영을 지원받고 있습니다. 이러한 과정을 통해 이젬코는 데이터 인프라를 현대화하고 새로운 비즈니스 가치를 창출할 수 있게 되었습니다.
품질 데이터 분석 플랫폼 아키텍처
품질 데이터 분석 플랫폼 워크로드 및 사용한 AWS서비스
이젬코는 NDS와 함께 기존 운영 환경의 데이터 부하를 최소화하면서도 안정적이고 확장성이 높은 데이터 분석 아키텍처를 구축하기 위해 AWS의 완전관리형 서비스를 중심으로 구성하였습니다. 특히 운영 DB에서 직접 분석 쿼리를 수행할 경우 발생할 수 있는 성능 저하 문제를 해결하고, 일별 배치 기반의 안정적인 데이터 적재 및 BI 분석 환경을 구축하는 데 초점을 맞추었습니다.
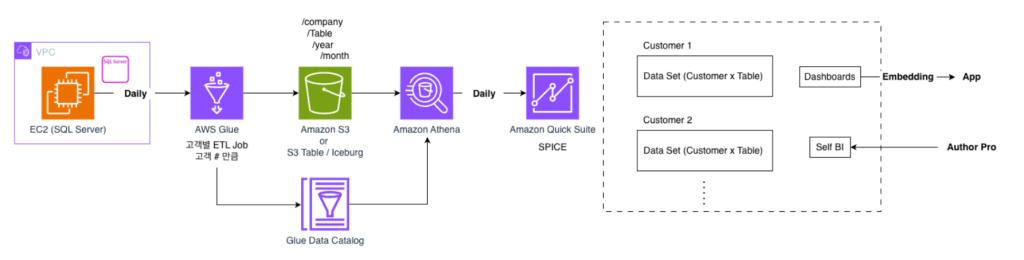
- DB에서 AWS Glue를 활용하여 Daily 배치로 S3에 저장
- S3에 저장된 데이터는 Athena를 통해 Daily Batch로 Quick Suite의 SPICE에 적재
- 가장 많은 수요를 가진 시각화 대시보드의 경우 미리 구성된 대시보드로 제공
- 데이터에 대해 질의하고자 하는 고객들의 경우 대시보드 기반으로 데이터 질의
AWS Glue
제조·품질 데이터를 보유하고 있는 운영 DB(EC2 환경의 SQL Server)로부터 데이터를 안정적으로 가져오기 위해 AWS Glue를 활용하였습니다. Glue는 JDBC 연결을 통해 운영 DB 데이터를 읽고, 스키마를 표준화한 후 S3 데이터 레이크로 적재하는 ETL 작업을 수행하였습니다. 이 과정은 일 단위 배치로 자동 실행되며, Glue Data Catalog에 테이블 메타데이터가 등록되어 이후 분석 서비스가 데이터를 쉽게 참조할 수 있도록 구성하였습니다.
S3 & Amazon Athena
S3에 적재된 데이터는 Amazon Athena를 통해 서버리스 방식으로 분석 가능하도록 구성하였습니다. Athena를 사용함으로써 별도의 서버 운영이 필요하지 않으며, 필요할 때마다 쿼리를 수행할 수 있는 유연한 분석 환경을 마련하였습니다. 또한 데이터 정합성 확보 및 품질 지표 산출을 위해 Athena를 활용한 추가 가공 작업도 함께 수행하였습니다.
Amazon QuickSight
정제된 분석 데이터는 Amazon QuickSight의 SPICE 엔진으로 일별로 적재되었습니다. SPICE는 대규모 데이터를 인메모리 기반으로 빠르게 조회할 수 있도록 최적화된 저장소로, 사용자들이 대시보드를 조회할 때 운영 DB나 Athena에 직접 부하를 주지 않고도 고성능 분석이 가능하도록 지원하였습니다. 이를 통해 품질팀과 운영팀은 다양한 시각화 분석, 지표 모니터링, 생성형 AI 기반 자연어 질의를 활용한 품질 데이터 분석 업무를 원활하게 수행할 수 있게 되었습니다.
이와 같이 EC2 기반 운영 DB, AWS Glue, Amazon S3, Amazon Athena, Amazon QuickSight를 조합하여 안정적이고 관리 부담이 적은 분석 워크로드 환경을 구현하였습니다.
Amazon QuickSuite Chat Agent
또한 이번 프로젝트의 핵심 요구사항 중 하나였던 생성형 AI 기반 자연어 질의 기능은 Amazon QuickSuite의 Chat Agent를 활용하여 구현하였습니다. QuickSuite는 SPICE에 적재된 데이터를 기반으로 사용자가 SQL을 작성하지 않아도 자연어로 질문을 입력하면 바로 분석 결과를 제공할 수 있습니다. 이를 위해 품질 분석에 특화된 에이전트(Persona)를 구성하고, 실제 품질 데이터에 기반하여 답변하도록 프롬프트를 설계하였습니다. 사용자는 “2023년 검사 불량률을 알려주세요”, “검사항목별 불량 TOP5를 분석해 줘”, “거래처별 불량을 비교해 줘”와 같은 자연어 질의를 통해 즉시 분석 결과를 확인할 수 있습니다.
Quicksuite의 권한 관리 기능을 활용하여 실사용자 그룹(고객단위)별로 접근 가능한 Space를 구분하고, 각 Space 내에서 Chat Agent가 사용할 수 있는 데이터 범위를 세밀하게 제어할 수 있도록 구성하였습니다. 이를 통해 분석 결과의 보안성을 확보하는 동시에, 고객별로 필요한 인사이트 중심의 “맞춤 AI 분석 환경”을 구성할 수 있었습니다. 이를 통해 사용자는 Space에 구성된 전체 데이터를 선택하거나 원하는 데이터 소스를 선택하여 자연어 질의를 통해 필요한 집계·필터링·정렬에 대한 시각화 결과를 제공합니다.
마지막으로, 해당 기능이 아직 서울 리전(ap-northeast-2)에서 공식적으로 제공되지 않았기 때문에 본 프로젝트는 미국 동부 버지니아 리전(us-east-1)에서 Quicksuite 환경을 구축하였습니다. 향후 서울 리전 지원 시 이전할 수 있도록 이관 시 고려해야 할 요소들을 사전에 정리해 두어 향후 단계적 확장이 용이하도록 준비해 두었습니다.
품질 데이터 분석 플랫폼 구현 상세
1. 데이터 전처리 및 ETL 구축 (AWS Glue 기반)
운영 중인 EC2 기반 SQL Server의 제조·품질 데이터를 AWS Glue를 활용하여 자동 수집하였습니다. JDBC 드라이버를 통해 연동된 Glue Job은 일 단위 스케줄로 실행되며, SQL Server의 테이블을 읽어 Amazon S3로 Parquet 포맷으로 저장하도록 구성하였습니다.
아래는 실제 Glue Job에서 활용된 ETL 코드의 예시입니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsgluedq.transforms import EvaluateDataQuality
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])sc = SparkContext()glueContext = GlueContext(sc)spark = glueContext.spark_session
job = Job(glueContext)job.init(args['JOB_NAME'], args)
# DB 연결 정보
jdbc_url = ""
table = ""
user = ""
password = ""
s3_location = ""
connection_properties = {
"user": user,
"password": password,
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
# SQL Server에서 데이터 읽기
df = spark.read.jdbc(
url=jdbc_url,
table=table,
properties=connection_properties
)
# S3 버킷 설정 및 overwrite 설정
df.write.mode("overwrite").parquet(s3_location)
job.commit()이 과정을 통해 운영 DB에 분석 쿼리를 직접 실행하지 않게 해 DB에 부하를 줄이며, 안정적이고 반복 가능한 데이터 파이프라인을 확보할 수 있었습니다.
2. Athena 기반 분석 계층 정립 (View 생성 및 데이터 재정의)
S3에 저장된 원본 데이터는 Amazon Athena를 통해 분석 가능한 상태로 재가공하였습니다. Athena에서는 각 품질 데이터의 관계를 명확하게 정의하기 위해 다양한 SQL View를 생성하였으며, 다음과 같은 구조적 개선 작업을 수행했습니다.
- 원료·부자재·내용물·완제품을 공정 단위로 연결하는 조인 구조 설계
- 검사 결과, 불량 기록, 거래처 정보 간 Key 매핑 재설정
- 불량 유형별 집계 로직 표준화
아래는 실제 Athena에서 생성한 DDL문과 View Table 코드 예시입니다.
```
CREATE OR REPLACE VIEW "view_table" AS
SELECT
columns
FROM
table t
INNER JOIN table_i ti ON t.key1 = ti.key1
INNER JOIN table_cd tcd ON t.key2 = tcd.key2;
```이를 통해 분산되어 있던 품질 데이터 간의 상관관계를 일관성 있게 정리하고, QuickSight 및 Quicksuite Chat Agent가 즉시 활용할 수 있는 분석 전용 데이터 계층(Analytical Layer)을 구축하였습니다.
해당 View 및 데이터셋은 현재 Quicksuite와의 연계 목적을 위해 미국 동부 버지니아(us-east-1) 리전에 구성하였습니다.
3. QuickSight 기반 대시보드 구성 (시각화 구현)
Athena에서 정제된 데이터를 기반으로 Amazon QuickSight SPICE에 데이터를 적재하였습니다. SPICE 적재는 일 단위 배치로 자동 갱신되며, 불량률·검사항목·거래처·기간 등 다양한 필터 조건을 반영하는 대시보드를 구축했습니다.
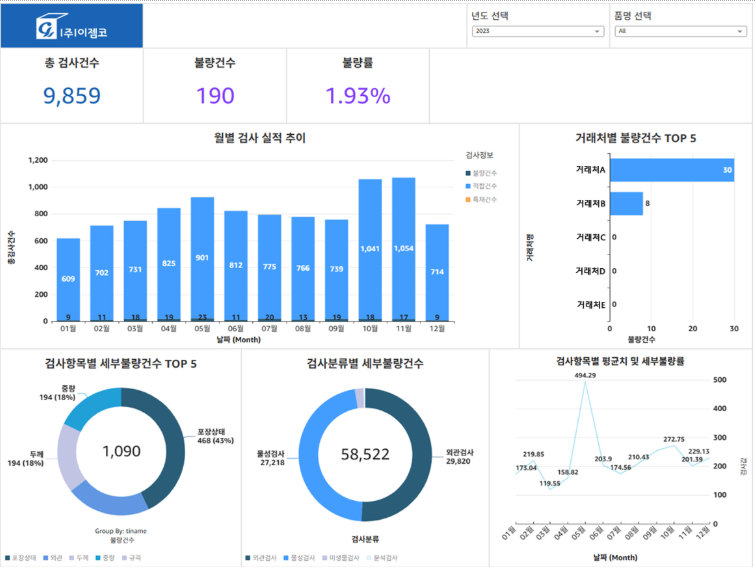
구현한 주요 대시보드는 다음과 같습니다.
- 월별 검사 실적 추이
- 전체 불량률 및 항목별 세부 불량률
- 검사항목별 TOP5 불량건수 분석
- 거래처별 불량 TOP5
- 검사분류별 품질 현황 및 트렌드 분석
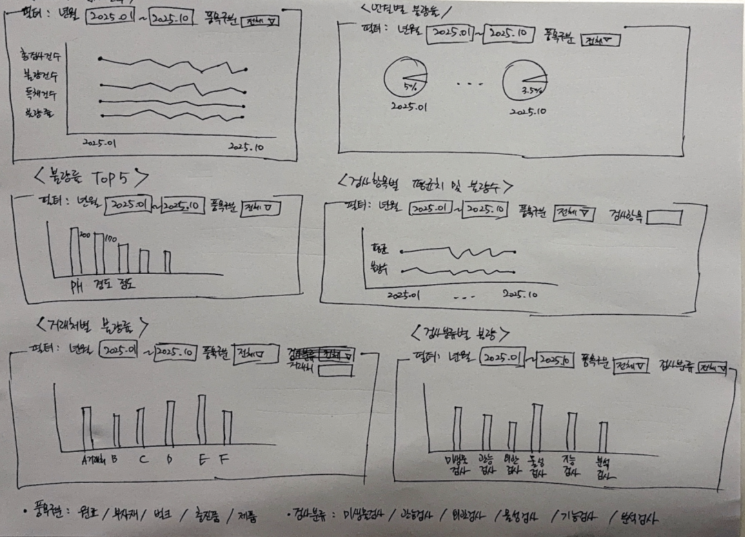
이 대시보드는 현업 품질팀이 손쉽게 조회할 수 있도록 구성되어 있으며, PLDL 과정에서 작성된 손그림 스케치를 기반으로 실제 UI로 구현되었습니다.
4. Amazon QuickSuite Chat Agent를 통한 생성형 AI 분석 기능 구현
생성형 AI 기반 분석은 이번 프로젝트의 핵심 목표 중 하나였습니다. 이를 위해 Amazon QuickSuite Chat Agent를 활용하여 품질 데이터 분석 전용 AI 에이전트를 구성하였습니다. 해당 기능은 현재 미국 동부 버지니아 리전(us-east-1)에서 사용할 수 있어 해당 리전에서 구축하였습니다.
AI 에이전트는 분석 결과를 요약 텍스트, 표, 그래프 형태로 즉시 생성하며, 이는 대시보드와 함께 사용될 때 강력한 의사결정 도구로 활용됩니다. 에이전트 구성 시 다음과 같은 작업을 수행했습니다.
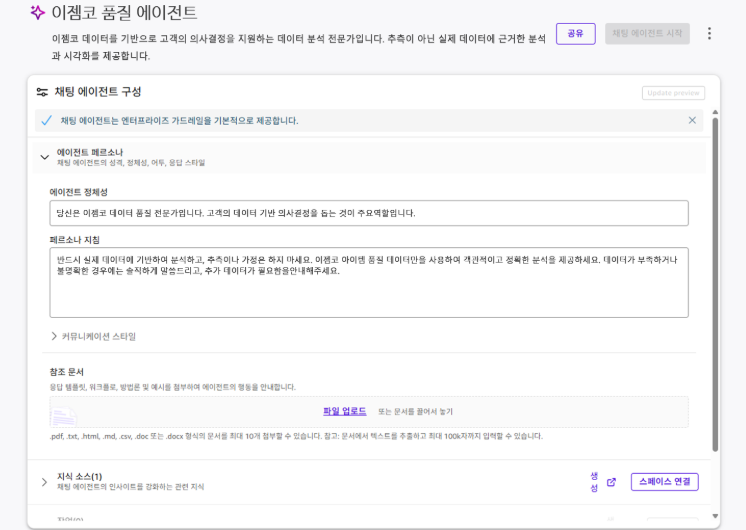
- 품질 분석 전문가 역할(Persona) 정의
- “추측 금지·실데이터 기반 답변” 등 정확성을 강화하는 시스템 프롬프트 설계
- 데이터가 부족하거나 불명확할 경우 추가 데이터가 필요함을 명확하게 요구
사용자는 다음과 같은 자연어 명령만으로 분석 결과를 확인할 수 있습니다.
- “아이템 품질 데이터 분석해줘”
- “2023년 기준 전체 불량률을 분석해 줘.”
- “불량 항목 TOP5를 그래프로 보여 줘.”
- “최근 불량률이 증가한 검사 항목이 있는지 알려줘.”
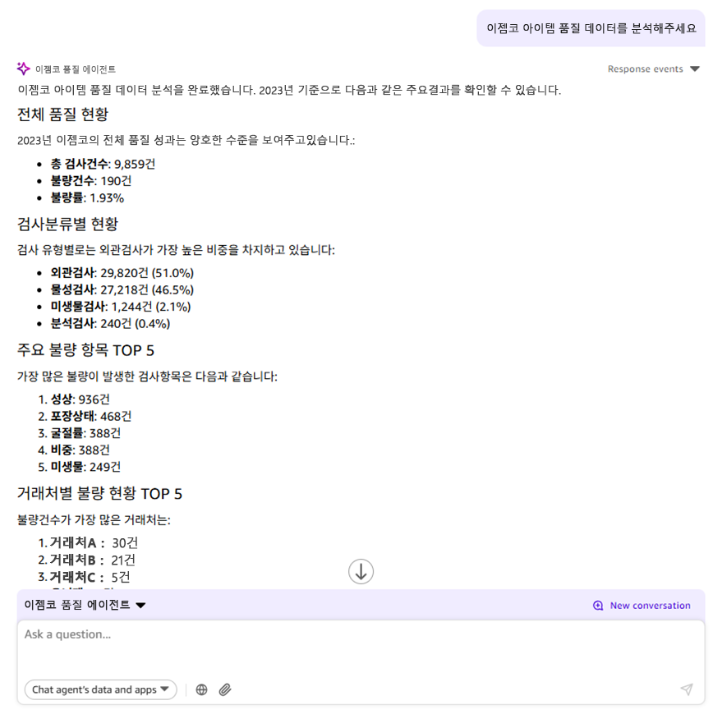
프로젝트 결과
이번 프로젝트를 통해 이젬코는 화장품 제조 품질 데이터 분석 플랫폼을 성공적으로 구축하였으며, 기존에 직면했던 두 가지 핵심 과제를 해결하였습니다.
(1) 공정 간 불량률 및 로트 기반 품질 추적의 어려움 해소: 서버리스 기반 일별 배치 ETL 파이프라인을 구축하여 운영 DB에 부하를 주지 않으면서도 안정적으로 데이터를 수집할 수 있게 되었습니다. 월별 검사 실적 추이, 불량률 분석, 검사항목별 TOP5 분석, 거래처별 품질 현황 등 다양한 대시보드를 통해 품질팀과 운영팀은 로트별 품질 편차와 공정 간 불량률을 즉시 확인할 수 있게 되었습니다. 이를 통해 특정 공정에서 발생한 불량 원인 분석 지연과 불량률 상승에 대한 대응 지연 문제를 해결하고 선제적 품질 관리가 가능해졌습니다.
(2) 기존 BI 환경의 한계 극복: 생성형 AI 기반 자연어 질의 기능을 구현하여 SQL 작성 없이도 품질 데이터를 분석할 수 있는 혁신적인 환경을 마련하였습니다. 고객사의 분석 요청이 있을 때마다 신규 대시보드를 개발해야 했던 기존 방식에서 벗어나, 실무자가 직접 원하는 방식으로 데이터를 조회하고 분석할 수 있게 되어 개발 리소스 투입을 최소화하고 분석 리드타임을 대폭 단축하였습니다. 서버리스 기반 아키텍처를 통해 향후 데이터 규모 증가에도 유연하게 대응할 수 있는 확장 가능한 플랫폼을 확보하였으며, 클라우드 기반 데이터 분석 기술을 내재화함으로써 화장품 제조 산업의 품질 관리를 디지털화하고 고객사에게 혁신적인 스마트 제조 솔루션을 제공할 수 있는 기반을 마련하였습니다.
마치며
NDS와 이젬코는 이번 MVP 구축을 통해 서비스 기반을 마련했으며, 2026년 정식 서비스 런칭을 목표로 기능 안정화와 개선 작업을 이어갈 예정입니다. 앞으로는 생산·제조 수율 관리, 구매·반품, 매출 추이, 원가율 분석 등으로 영역을 확장해 제조 현장의 주요 지표를 한눈에 파악할 수 있는 통합 플랫폼으로 고도화할 계획입니다. 또한 국가 AI 사업 참여를 통해 AI 기반 제조 지능화 기능을 강화하고, 고객사에 맞춤형 AI 솔루션을 제공할 예정이다. BI 대시보드 임베딩, CDC 기반 데이터 처리, 그리고 향후 QuickSuite 한국 리전 출시 시 리전 마이그레이션도 함께 추진해 운영 효율과 안정성을 높일 계획입니다.