AWS 기술 블로그
Amazon RDS for PostgreSQL에서 테이블 파티셔닝을 통한 시계열 데이터 수집 속도 향상
이 글은 AWS Database Blog에 게시된 Speed up time series data ingestion by partitioning tables on Amazon RDS for PostgreSQL by Vinicius Schmidt and Andy Katz을 한국어 번역 및 편집하였습니다.
지난 포스트 (Amazon RDS for PostgreSQL에서 고성능 시계열 데이터 테이블 설계)에서는 시계열 데이터를 처리할 때 성능을 향상시키는 전략으로 파티션된 테이블(partitioned tables)을 사용하는 방법을 설명했습니다. 이번 포스트에서는 데이터 수집(data ingestion)에 초점을 맞춰 파티션된 테이블이 데이터 수집에 어떻게 도움이 되는지 살펴보겠습니다.
PostgreSQL은 이미 오래전부터 테이블 파티셔닝 기능을 제공해왔습니다. PostgreSQL 10 이전에는 트리거와 테이블 상속을 사용하여 파티션을 생성할 수 있었으며, 이를 통해 파티션 작동 방식을 사용자 정의할 수 있었습니다. 하지만 이 방법은 복잡하고 유지 관리가 어려웠습니다. PostgreSQL 10에서는 선언적 파티션(declarative partitions)이 도입되었습니다. 선언적 파티션(네이티브 파티션)은 테이블 스캔 중에 옵티마이저가 불필요한 파티션을 제외하도록 하는 체크 제약 조건(check constraints) 정의하는 번거로움을 없애주었습니다. 이를 파티션 프루닝(partition pruning)이라고도 합니다. 선언적 파티셔닝은 각 파티션으로 쓰기를 리디렉션하기 위해 부모 테이블에 트리거를 배치할 필요가 없습니다.
2017년 PostgreSQL 10이 출시된 이후, PostgreSQL 커뮤니티에 의해 많은 개선사항이 만들어졌고 계속해서 개선되고 있습니다. 이러한 개선사항에는 성능 향상, foreign data wrapper와 같은 다른 엔진 구성 요소와의 향상된 통합, 논리적 복제(logical replication) 지원 등 다양한 기능이 포함됩니다.
파티셔닝의 아이디어는 데이터베이스 엔진이 단일 대형 테이블을 처리하는 것과 비교하여 작은 데이터 청크(객체 또는 파티션)를 처리할 때 더 나은 성능을 발휘한다는 것입니다. 이는 테이블을 읽어야 할 때뿐만 아니라 새로운 데이터 행을 수집할 때도 마찬가지입니다. 이 포스트는 파티션된 테이블이 데이터 수집에 도움이 되는 이유에 초점을 맞춥니다.첫 번째 포스트를 읽지 않으셨다면, 이 글을 더 잘 이해하는 데 도움이 될 것이므로 먼저 읽어보시기를 강력히 권장합니다.
성능 요인
테이블에 행을 삽입(또는 수집)하는 작업의 성능에 영향을 미치는 여러 요인이 있습니다. 데이터베이스를 요구사항에 맞게 더 잘 최적화하기 위해서는 이러한 각 요인을 이해하는 것이 중요합니다. 이 포스트에서는 다음 사항들을 다룹니다:
- 테이블 크기
- 인덱스
- 수집 방법
- 체크포인트
- 가용 영역
테이블 크기
테이블 크기는 행 수와 디스크에서 소비하는 공간을 의미합니다. 데이터 수집에 대해서만 보자면, 테이블 크기 자체는 수집 성능에 큰 영향을 미치지 않습니다. 대부분의 경우 큰 테이블은 읽기 작업도 수행해야 합니다. 테이블이 클수록 읽기 속도는 느려집니다. 읽기 속도를 높이기 위해 인덱스를 생성하지만, 여기에는 함정이 있습니다. 대형 테이블에 인덱스가 많을수록 데이터 수집이 느려집니다.
인덱스
테이블 크기와 관련이 있지만 그 자체로도 중요한 것은 테이블과 연관된 인덱스의 수(크기, 컬럼 수, 방식을 포함)입니다. 인덱스는 항상 정렬된 상태를 유지해야 하기 때문에 데이터 수집 성능에 영향을 미칩니다. 기본적으로 PostgreSQL 인덱스는 인덱싱되는 컬럼의 모든 값을 저장하기 위해 균형 트리 데이터 구조(BTree)를 사용합니다. 인덱스 값은 정렬되어야 하며 테이블 자체에 대한 포인터를 가져야 합니다(테이블 자체는 반드시 정렬된 방식으로 데이터를 저장할 필요는 없습니다). 인덱스를 정렬된 상태로 유지하기 위해 BTree 알고리즘은 데이터 구조를 분할하고, 올바른 위치를 유지하며, 한 브랜치가 다른 브랜치보다 커지지 않도록 순서를 유지해야 합니다. 이는 읽을 때 균일한 속도를 유지하며, 실제로 필요한 것보다 더 많은 인덱스를 생성하지 않을 것을 강력히 권장하는 이유입니다.
데이터베이스를 쿼리하여 사용되지 않는 모든 인덱스를 식별할 수 있습니다:
SELECT n.nspname AS schemaname
, c.relname AS tablename
, i.relname AS indexname
, t.spcname AS tablespace
, pg_get_indexdef(i.oid) AS indexdef
FROM pg_index x
JOIN pg_class c ON (c.oid = x.indrelid )
JOIN pg_class i ON (i.oid = x.indexrelid )
JOIN pg_stat_all_indexes sai ON (sai.indexrelid = i.oid )
LEFT JOIN pg_namespace n ON ( n.oid = c.relnamespace )
LEFT JOIN pg_tablespace t ON ( t.oid = i.reltablespace )
WHERE (c.relkind = ANY (ARRAY[ 'r'::"char"
,'m'::"char"
, 'p'::"char"]))
AND (i.relkind = ANY (ARRAY['i'::"char", 'I'::"char"]))
AND sai.idx_scan = 0
AND sai.schemaname not like 'pg_%'
AND NOT ( x.indisprimary OR x.indisunique ) ;앞의 예제에서는 인덱스 정의, 스키마, 각 인덱스가 사용된 횟수를 저장하는 카탈로그 테이블(pg_index와 pg_stat_indexes)을 조인하고 있으며, 이는 idx_scan 컬럼으로 결정됩니다. 기본 키와 고유 인덱스는 사용되지 않더라도 스키마 정의에서 중요한 역할을 하므로 제외합니다.
또 다른 중요한 튜닝은 중복된 인덱스(동일한 정의를 가진 두 개 이상의 인덱스)를 제거하는 것입니다. 중복 인덱스를 식별하는 예제 쿼리는 Duplicate indexes를 참조합니다.
수집 방법
한 번에 많은 수의 행을 수집하는 것(COPY 명령을 통한 대량 삽입)과 동일한 트랜잭션에서라도 INSERT를 사용하여 여러 행을 삽입하는 것 사이에는 성능상 중요한 차이가 있습니다. 예를 들어, COPY를 사용하여 백만 개의 행을 수집하는 것이 백만 개의 insert 문을 사용하는 것보다 항상 빠릅니다. INSERT가 느린 이유는 INSERT 명령을 실행할 때마다 PostgreSQL 엔진이 명령 문법이 올바른지 파싱하고 확인해야 하기 때문입니다. COPY를 사용할 때는 수집하려는 데이터를 미리 가지고 있다고 가정합니다(데이터를 가져오는 중). COPY는 대량 로드 작업에 권장됩니다. 항상 COPY를 사용할 기회가 있는 것은 아니기 때문에 이를 이해하는 것이 중요합니다. 대부분의 애플리케이션은 INSERT를 사용하여 테이블에 행을 추가합니다. 다음은 사용 사례와 일반적으로 사용되는 수집 방법을 연관시킨 몇 가지 예입니다:
- IoT 및 DevOps – IoT 센서와 데이터 수집 에이전트가 사용하는 애플리케이션은 INSERT 문을 통해 또는 COPY를 사용한 소규모 배치를 통해 테이블에 직접 데이터를 삽입합니다. COPY는 일반적으로 백업 중에 데이터를 내보내거나 가져올 때 사용되지만, JDBC, psycopg2, DBD::Pg와 같은 많은 연결 드라이버에서 직접 호출할 수도 있습니다.
- 과거 데이터셋 – 완전한 데이터셋의 경우 COPY 또는 공통 테이블 표현식(Common Table Expression, CTE)을 사용할 수 있습니다. 수집하려는 데이터셋이 이미 CSV 파일에 있다면 COPY를 사용할 수 있습니다. 과거 데이터가 다른 테이블에서 검색되는 경우(foreign data wrapper를 통한 원격 테이블에서도), SELECT 쿼리 결과를 기반으로 다른 테이블에 데이터를 INSERT하는 CTE를 사용할 수 있습니다.
체크포인트
체크포인트 작업이 발생할 때마다 전체 페이지 쓰기(full-page write) 작업도 발생합니다. 이는 8KB 페이지(메모리의 데이터베이스 블록)가 파일 시스템(4KB로 정의된 더 작은 페이지를 가짐)에 완전히 쓰여지도록 보장하기 위해서입니다. 전체 페이지 쓰기는 장애 발생 시 부분 페이지를 쓰지 않도록 보장하여 잠재적으로 데이터 손상을 방지하는 기술입니다. 모든 Amazon Relational Database Service (Amazon RDS) for PostgreSQL 인스턴스는 전체 페이지 쓰기를 강제합니다. 짧은 기간에 너무 많은 데이터를 수집하고, 많은 인덱스를 가진 테이블을 사용하며, 전체 페이지 쓰기로 인해 체크포인트가 너무 자주 발생하고 필요 이상으로 많은 데이터를 기록할 가능성이 높습니다. 그런 경우, 데이터베이스 로그에 다음 메시지가 나타납니다:
LOG: checkpoints are occurring too frequently이 메시지가 보이면 체크포인트 매개변수를 튜닝해야 합니다.
가용 영역
데이터베이스에 대량의 데이터를 수집할 때 무시할 수 없는 요인은 데이터베이스가 데이터를 수집하는 소스나 애플리케이션으로부터 얼마나 떨어져 있는지입니다. 예를 들어, 애플리케이션이나 소스가 특정 가용 영역(us-west-2d)에 있다면, 두 개의 서로 다른 가용 영역 간의 네트워크 지연을 피하기 위해 RDS for PostgreSQL DB 인스턴스를 동일한 가용 영역에 두는 것이 좋습니다. 지연 시간 차이가 미미해 보이지만, 많은 수의 행을 수집할 때 INSERT 방법을 사용하면 상당한 성능 영향을 미칠 수 있습니다. 가용 영역에 주의를 기울이는 것은 서로 다른 설정을 가진 두 인스턴스를 벤치마킹하거나 다른 전략을 사용할 때 특히 중요합니다. 네트워크 지연으로 인한 왜곡된 결과를 방지하기 위해 두 인스턴스가 동일한 가용 영역에 있는지 확인해야 합니다.
데이터 수집 예제 및 벤치마크
대량의 데이터 수집을 시뮬레이션하기 위해 여러 도구 중에서 선택할 수 있습니다. 이러한 도구를 사용하면 가능한 한 빠르게 데이터를 수집하여 다양한 접근 방식을 비교할 수 있습니다. 예를 들어, 여러 인덱스를 가진 단일 테이블과 동일한 인덱스를 가진 파티션된 테이블을 사용하여 대량 로드 유형의 데이터 수집을 비교할 수 있습니다. 또한 다양한 매개변수 설정을 비교할 수도 있습니다. 하지만 각 변경사항의 정확한 성능 이점을 이해할 수 있도록 동시에 여러 변수를 변경하는 것은 권장하지 않습니다. 예를 들어, 파티션된 테이블과 단일 테이블을 비교하는 경우 다른 매개변수는 변경하지 마세요(이렇게 하면 공정한 비교가 가능합니다).
이 포스트에서는 데이터 수집을 벤치마킹하고 비교하기 위한 두 가지 도구인 tsbs와 pgbench를 보여줍니다. 다른 많은 도구들(HammerDB나 Sysbench 같은)도 존재하며, 각각 고유한 특성과 전문성을 가지고 있습니다.
수집 예제: tsbs
Amazon RDS for PostgreSQL에서 고성능 시계열 데이터 테이블 설계 포스트에서는 tsbs를 사용한 데이터 수집 예제를 보여주었습니다. tsbs는 여러 데이터베이스에서 시계열 데이터를 측정하도록 설계된 간단하지만 훌륭한 벤치마크 도구입니다. 가능한 한 빠르게 수집하기 위해 tsbs는 수집하려는 데이터셋을 미리 생성해야 합니다.
tsbs 도구는 DevOps와 IoT라는 두 가지 사용 사례를 시뮬레이션합니다. DevOps 사용 사례는 시스템 또는 호스트 모니터링 시스템을 시뮬레이션합니다. IoT 사용 사례는 가상의 트럭 회사에 속한 트럭 차량을 추적하여 연료 수준과 같은 환경 요인을 시뮬레이션합니다. 이 포스트에서는 IoT 사용 사례를 사용합니다.
기본적으로 tsbs는 네이티브 파티션을 미리 생성하지 않으므로, 다음 예제에서는 pg_partman을 사용하여 각 파티션의 생성을 자동으로 처리하는 테이블을 직접 생성하여 네이티브 파티션을 처리합니다.
파티션된 테이블과 파티션되지 않은 테이블 간의 데이터 수집을 비교하기 위해 tsbs를 설치할 수 있습니다.
먼저 tsbs의 종속성인 golang을 설치합니다:
sudo yum install golang git -y
export GOPATH="$HOME/go"
export PATH=$GOPATH/bin:$PATH
mkdir -p $GOPATH/bingolang이 성공적으로 설치되면 벤치마크 도구인 tsbs를 설치합니다:
go get github.com/timescale/tsbs
cd $GOPATH/src/github.com/timescale/tsbs
make
ls -la $GOPATH/bin/tsbs_* | wc -l이 모든 단계가 성공적으로 완료되고 실패가 발생하지 않았다면, 다음 명령이 25를 반환하는 것을 볼 수 있습니다. ($GOPATH/bin 디렉토리에서 tsbs_ 문자열로 시작하는 25개의 줄 또는 명령이 발견되었다는 의미)
이제 테스트에서 사용할 데이터를 생성합니다. 이를 위해 새 디렉토리를 만들고 tsbs_generate_data 프로그램을 호출합니다:
mkdir -p /mnt/DATA/tsbs/iots_small
time tsbs_generate_data --use-case="iot" --scale=4000\
--timestamp-start="2021-06-08T00:00:00Z" \
--timestamp-end="2021-06-11T00:00:00Z" \
--log-interval="10s" --format="timescaledb" \
| gzip > /mnt/DATA/tsbs/iots_small/timescaledb-data_iot_Jun21_3days.gzPostgreSQL 네이티브 파티션용 데이터를 생성할 때도 timescaledb 형식 매개변수를 사용해야 합니다. iot와 함께 사용할 때 scale 매개변수는 추적되는 트럭의 총 수를 정의합니다.
앞의 명령은 2021-06-08 00h00m00s와 2021-06-10 23h59m59s사이에 미리 설정된 타임스탬프 간격으로 3일간의 데이터를 생성합니다. 테스트 호스트(동일한 가용 영역에 배포된 m5.16xlarge 인스턴스)에서 이 명령은 20분이 걸렸으며, 3.1GB의 압축 파일을 생성했습니다.
데이터셋이 생성된 후 첫 번째 데이터 수집을 시작할 준비가 되었습니다. 이 포스트에서는 PostgreSQL 13.2를 실행하는 RDS for PostgreSQL DB 인스턴스로 데이터를 수집합니다. 파티션이나 최적화 없이 예제부터 시작합니다. 이 테스트에 사용된 인스턴스 클래스는 8TB 스토리지와 20,000 IOPS를 가진 db.r6g.4xlarge였습니다. 선호하는 인스턴스 클래스를 선택하되, 다른 인스턴스 클래스는 vCPU와 메모리의 양뿐만 아니라 I/O 처리량 기능도 다르다는 점을 염두에 두어야 합니다. 자세한 정보는 Network Performance를 참조합니다.
단일 테이블로 수집
작업을 쉽게 하기 위해 PostgreSQL의 연결 환경 변수를 설정하고 로드 스크립트를 호출할 때 사용합니다:
export PGHOST="iot-dbe-benchmark-single.uniqueaccountrdshash.us-west-2.rds.amazonaws.com"
export PGDATABASE="postgres"
export PGPORT="5432"
export PGUSER="dberoot"
export PGPASSWORD="my-secret-p4ssw0rd"로드 스크립트는 tsbs 소스 코드 내부에 있습니다(앞서 git 명령을 사용하여 다운로드했습니다):
cat /mnt/DATA/tsbs/iots_current/timescaledb-data_iot_Jun21_3days.gz \
| gunzip \
| tsbs_load_timescaledb \
--postgres=sslmode=disable \
--db-name=test \
--host="$PGHOST" \
--port="$PGPORT" \
--pass="$PGPASSWORD" \
--user="$PGUSER" \
--workers=4 \
--batch-size=10000 \
--reporting-period=10s \
--use-hypertable=false \
--use-jsonb-tags=false \
--in-table-partition-tag=true \
--hash-workers=false \
--time-partition-index=false \
--partitions=0 \
--write-profile= \
--field-index-count=1 \
--create-metrics-table=true \
--do-create-db=true \
--force-text-format=false 2>&1 | tee -a $HOME/data_load_metrics_iot-single-table-Jun21_rpg13.log요약:
- 4개의 워커로 1784.768초 동안 933,526,165개의 메트릭을 로드했습니다 (평균 속도 523,051.96 메트릭/초)
- 4개의 워커로 1784.768초 동안 186,706,431개의 행을 로드했습니다 (평균 속도 104,611.06 행/초)
tsbs_load_timescaledb 명령에 전달하는 매개변수 --workers=4와 --batch-size=10000에 주목합니다. 첫 번째는 COPY 명령을 통해 데이터를 수집하는 동시 연결 수를 정의합니다. 또한 각 워커에 대해 tags 테이블에 행을 수집하기 위한 두 번째 연결이 생성됩니다. 두 번째 매개변수는 각 워커가 수집하는 행 수를 정의합니다. 이론적으로 더 많은 워커를 사용하면 동시에 더 많은 데이터를 수집할 수 있지만, 더 많은 워커를 사용하려면 DB 인스턴스가 워크로드를 처리하기 위해 CPU, 메모리, I/O와 같은 더 많은 리소스를 가져야 합니다.
매개변수 --use-hypertable=false는 파티셔닝에 다른 접근 방식을 사용하는 timescaledb 확장을 사용하지 않는다고 로드 명령에 알려줍니다.
데이터베이스는 COPY를 수집 방법으로 사용하여 4개의 워커(또는 동시 세션)에서 186,706,431개의 행을 수집했으며, 각 워커는 10,000개의 행을 배치 처리했습니다. 이러한 행들은 각각 17GB와 21GB 크기의 diagnostics와 readings 두 테이블에 삽입되었습니다. 이 테이블들은 파티션되지 않았으며, 전체 수집 과정은 1,784초(약 29분)가 걸렸습니다.
데이터는 미리 생성되었고 데이터를 수집하는 데 사용된 Amazon Elastic Compute Cloud (Amazon EC2) 인스턴스(tsbs 프로그램을 실행하는 의미)는 4개의 병렬 워커를 처리할 수 있을 만큼 강력했습니다. 또한 RDS 인스턴스는 tsbs를 실행하는 EC2 인스턴스가 배포된 동일한 가용 영역에 배포되었습니다. RDS 인스턴스는 파티션된 테이블과 파티션되지 않은(일반 또는 단일) 테이블 사용 간의 차이점에만 집중할 수 있을 만큼 충분했습니다.
시간이 지남에 따라 얼마나 많은 행이 수집되고 있는지 분석하기 위해 수집 보고서를 $HOME/data_load_metrics_iot-single-table-Jun21_rpg13.log 파일에 저장합니다.
다음 코드는 이 두 테이블 정의와 크기를 보여줍니다:
test=> \d readings
Table "public.readings"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | |
tags_id | integer | | |
name | text | | |
latitude | double precision | | |
longitude | double precision | | |
elevation | double precision | | |
velocity | double precision | | |
heading | double precision | | |
grade | double precision | | |
fuel_consumption | double precision | | |
additional_tags | jsonb | | |
Indexes:
"readings_tags_id_time_idx" btree (tags_id, "time" DESC)
"readings_time_idx" btree ("time" DESC)
test=> select pg_size_pretty(pg_total_relation_size('readings'));
pg_size_pretty
----------------
21 GB
(1 row)
test=> select count(*) from readings;
count
----------
93351718
(1 row)
test=> \d diagnostics
Table "public.diagnostics"
Column | Type | Collation | Nullable | Default
-----------------+--------------------------+-----------+----------+---------
time | timestamp with time zone | | |
tags_id | integer | | |
name | text | | |
fuel_state | double precision | | |
current_load | double precision | | |
status | double precision | | |
additional_tags | jsonb | | |
Indexes:
"diagnostics_tags_id_time_idx" btree (tags_id, "time" DESC)
"diagnostics_time_idx" btree ("time" DESC)
test=> select pg_size_pretty(pg_total_relation_size('diagnostics')) ;
pg_size_pretty
----------------
17 GB
(1 row)
test=> select count(*) from diagnostics ;
count
----------
93354713
(1 row)데이터베이스의 총 크기는 다음과 같습니다:
test=> select pg_size_pretty( pg_database_size('test') ) ;
pg_size_pretty
----------------
37 GB
(1 row)파티션된 테이블로 수집
이제 단일 테이블(파티션되지 않은) 접근 방식을 사용하여 행을 수집했으므로, 파티션된 테이블을 사용하여 동일한 작업을 수행합니다. 이를 위해 수집 중에 사용되는 객체를 수동으로 생성하고 pg_partman 확장을 사용하여 파티션을 자동으로 생성합니다. Amazon RDS 환경에서의 파티셔닝에 대한 자세한 내용은 Managing PostgreSQL partitions with the pg_partman extension을 참조하세요.
연결하기 전에 객체 생성과 벤치마크 중에 사용할 연결 변수를 정의합니다:
export PGHOST="iot-dbe-benchmark-partitioned.uniqueaccountrdshash.us-west-2.rds.amazonaws.com"
export PGDATABASE="postgres"
export PGPORT="5432"
export PGUSER="dberoot"
export PGPASSWORD="my-secret-p4ssw0rd"이제 psql 클라이언트를 통해 객체를 생성할 수 있습니다:
psql
DROP DATABASE IF EXISTS test;
CREATE DATABASE test;
\c test
-- pg_partman 확장을 설치하여 네이티브 파티션을 제어할 수 있도록 합니다
CREATE SCHEMA partman;
CREATE EXTENSION pg_partman WITH SCHEMA partman;
-- Readings
CREATE TABLE public.readings (
time timestamp with time zone
,tags_id integer
,name text
,latitude double precision
,longitude double precision
,elevation double precision
,velocity double precision
,heading double precision
,grade double precision
,fuel_consumption double precision
,additional_tags jsonb
) PARTITION BY RANGE (time);
ALTER TABLE public.readings
ALTER COLUMN elevation TYPE real,
ALTER COLUMN velocity TYPE real,
ALTER COLUMN heading TYPE real,
ALTER COLUMN grade TYPE real,
ALTER COLUMN fuel_consumption TYPE real;
CREATE INDEX readings_tags_id_time_idx ON public.readings USING btree (tags_id, time DESC);
CREATE INDEX readings_time_idx ON public.readings USING btree (time DESC);
CREATE INDEX readings_latitude_time_idx ON public.readings USING btree (latitude, time DESC);
CREATE INDEX readings_time_brin_idx ON public.readings USING BRIN (time) WITH (pages_per_range = 32);
SELECT partman.create_parent(
p_parent_table => 'public.readings',
p_control => 'time',
p_type => 'native',
p_interval=> 'hourly',
p_start_partition=> '2021-06-08 00:00:00',
p_premake => 168); -- 24*7
UPDATE partman.part_config
SET infinite_time_partitions = true,
retention = '3 months',
retention_keep_table=true
WHERE parent_table = 'public.readings';
-- Diagnostics
CREATE TABLE public.diagnostics (
time timestamp with time zone
,tags_id integer
,name text
,fuel_state double precision
,current_load double precision
,status double precision
,additional_tags jsonb
) PARTITION BY RANGE (time);
CREATE INDEX diagnostics_fuel_state_time_idx ON public.diagnostics USING btree (fuel_state, time DESC);
CREATE INDEX diagnostics_tags_id_time_idx ON public.diagnostics USING btree (tags_id, time DESC);
CREATE INDEX diagnostics_time_idx ON public.diagnostics USING btree (time DESC);
SELECT partman.create_parent(
p_parent_table => 'public.diagnostics',
p_control => 'time',
p_type => 'native',
p_interval=> 'hourly',
p_start_partition=> '2021-06-08 00:00:00',
p_premake => 168); -- 24*7
UPDATE partman.part_config
SET infinite_time_partitions = true,
retention = '3 months',
retention_keep_table=true
WHERE parent_table = 'public.diagnostics';
-- Tags
CREATE TABLE tags (
id serial primary key
,name text
,fleet text
,driver text
,model text
,device_version text
,load_capacity double precision
,fuel_capacity double precision
,nominal_fuel_consumption double precision
);
CREATE INDEX tags_name_idx ON tags (name);
CREATE UNIQUE INDEX uniq1 ON tags (name, fleet, driver, model, device_version, load_capacity, fuel_capacity, nominal_fuel_consumption);객체를 생성한 후 tsbs_load_timescaledb 명령을 사용하여 벤치마크 수집을 시작할 수 있습니다. 하지만 이제 두 매개변수의 값을 변경합니다. 변경된 매개변수는 --create-metrics-table=false와 --do-create-db=false입니다. 이러한 변경으로 벤치마크 도구에게 데이터베이스를 삭제하지 않고, 벤치마크에 사용되는 테이블을 삭제 및 생성하지 않도록 합니다. 이는 파티션으로 테스트하기 위해 테이블을 수동으로 생성했기 때문입니다. 다음 코드를 참조하세요:
cat /mnt/DATA/tsbs/iots_current/timescaledb-data_iot_Jun21_3days.gz \
| gunzip \
| tsbs_load_timescaledb \
--postgres=sslmode=disable \
--db-name=test \
--host="$PGHOST" \
--port="$PGPORT" \
--pass="$PGPASSWORD" \
--user="$PGUSER" \
--workers=4 \
--batch-size=10000 \
--reporting-period=10s \
--use-hypertable=false \
--use-jsonb-tags=false \
--in-table-partition-tag=true \
--hash-workers=false \
--time-partition-index=false \
--partitions=0 \
--write-profile= \
--field-index-count=1 \
--create-metrics-table=false \
--do-create-db=false \
--force-text-format=false 2>&1 | tee -a $HOME/data_load_metrics_iot-single-table-Jun21.log
(…)
요약:
4개의 워커로 820.360초 동안 933526165개의 메트릭을 로드했습니다 (평균 속도 1137946.70 메트릭/초)
4개의 워커로 820.360초 동안 186706431개의 행을 로드했습니다 (평균 속도 227590.80 행/초)결과는 동일한 186,706,431개의 행이 삽입되었지만, 1,784초(약 29분) 대신 820초(약 14분)가 걸렸음을 보여줍니다. 성능 향상으로 수집 시간이 절반으로 단축되었습니다. 테스트 간의 유일한 차이점은 테이블 자체입니다. 더 빠른 수집은 파티션된 테이블을 사용한 것입니다.
이 예제에서 readings와 diagnostics 테이블은 각 파티션에 대해 1시간 간격을 사용하여 파티션됩니다. 3일(72시간)의 데이터를 수집하기 위해 미리 37개의 파티션과 DEFAULT 파티션을 생성했습니다.
파티션된 테이블이 어떻게 보이는지 확인하려면 psql 클라이언트에서 \d+ table_name 명령을 사용할 수 있습니다. 컬럼 이름과 데이터 타입, 인덱스, 제약 조건과 같이 일반적으로 보는 것 외에도 파티션된 테이블(부모 테이블이라고도 함)에 연결된 파티션도 볼 수 있습니다.
test=> \d+ readings
Partitioned table "public.readings"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
------------------+--------------------------+-----------+----------+---------+----------+--------------+-------------
time | timestamp with time zone | | | | plain | |
tags_id | integer | | | | plain | |
name | text | | | | extended | |
latitude | double precision | | | | plain | |
longitude | double precision | | | | plain | |
elevation | real | | | | plain | |
velocity | real | | | | plain | |
heading | real | | | | plain | |
grade | real | | | | plain | |
fuel_consumption | real | | | | plain | |
additional_tags | jsonb | | | | extended | |
Partition key: RANGE ("time")
Indexes:
"readings_latitude_time_idx" btree (latitude, "time" DESC)
"readings_tags_id_time_idx" btree (tags_id, "time" DESC)
"readings_time_brin_idx" brin ("time") WITH (pages_per_range='32')
"readings_time_idx" btree ("time" DESC)
Partitions: readings_p2021_06_08_0000 FOR VALUES FROM ('2021-06-08 00:00:00+00') TO ('2021-06-08 01:00:00+00'),
readings_p2021_06_08_0100 FOR VALUES FROM ('2021-06-08 01:00:00+00') TO ('2021-06-08 02:00:00+00'),
readings_p2021_06_08_0200 FOR VALUES FROM ('2021-06-08 02:00:00+00') TO ('2021-06-08 03:00:00+00'),
readings_p2021_06_08_0300 FOR VALUES FROM ('2021-06-08 03:00:00+00') TO ('2021-06-08 04:00:00+00'),
readings_p2021_06_08_0400 FOR VALUES FROM ('2021-06-08 04:00:00+00') TO ('2021-06-08 05:00:00+00'),
readings_p2021_06_08_0500 FOR VALUES FROM ('2021-06-08 05:00:00+00') TO ('2021-06-08 06:00:00+00'),
readings_p2021_06_08_0600 FOR VALUES FROM ('2021-06-08 06:00:00+00') TO ('2021-06-08 07:00:00+00'),
readings_p2021_06_08_0700 FOR VALUES FROM ('2021-06-08 07:00:00+00') TO ('2021-06-08 08:00:00+00'),
readings_p2021_06_08_0800 FOR VALUES FROM ('2021-06-08 08:00:00+00') TO ('2021-06-08 09:00:00+00'),
readings_p2021_06_08_0900 FOR VALUES FROM ('2021-06-08 09:00:00+00') TO ('2021-06-08 10:00:00+00'),
readings_p2021_06_08_1000 FOR VALUES FROM ('2021-06-08 10:00:00+00') TO ('2021-06-08 11:00:00+00'),
readings_p2021_06_08_1100 FOR VALUES FROM ('2021-06-08 11:00:00+00') TO ('2021-06-08 12:00:00+00'),
readings_p2021_06_08_1200 FOR VALUES FROM ('2021-06-08 12:00:00+00') TO ('2021-06-08 13:00:00+00'),
readings_p2021_06_08_1300 FOR VALUES FROM ('2021-06-08 13:00:00+00') TO ('2021-06-08 14:00:00+00'),
readings_p2021_06_08_1400 FOR VALUES FROM ('2021-06-08 14:00:00+00') TO ('2021-06-08 15:00:00+00'),
readings_p2021_06_08_1500 FOR VALUES FROM ('2021-06-08 15:00:00+00') TO ('2021-06-08 16:00:00+00'),
readings_p2021_06_08_1600 FOR VALUES FROM ('2021-06-08 16:00:00+00') TO ('2021-06-08 17:00:00+00'),
readings_p2021_06_08_1700 FOR VALUES FROM ('2021-06-08 17:00:00+00') TO ('2021-06-08 18:00:00+00'),
readings_p2021_06_08_1800 FOR VALUES FROM ('2021-06-08 18:00:00+00') TO ('2021-06-08 19:00:00+00'),
readings_p2021_06_08_1900 FOR VALUES FROM ('2021-06-08 19:00:00+00') TO ('2021-06-08 20:00:00+00'),
readings_p2021_06_08_2000 FOR VALUES FROM ('2021-06-08 20:00:00+00') TO ('2021-06-08 21:00:00+00'),
readings_p2021_06_08_2100 FOR VALUES FROM ('2021-06-08 21:00:00+00') TO ('2021-06-08 22:00:00+00'),
(…)
readings_p2021_06_16_0500 FOR VALUES FROM ('2021-06-16 05:00:00+00') TO ('2021-06-16 06:00:00+00'),
readings_p2021_06_16_0600 FOR VALUES FROM ('2021-06-16 06:00:00+00') TO ('2021-06-16 07:00:00+00'),
readings_p2021_06_16_0700 FOR VALUES FROM ('2021-06-16 07:00:00+00') TO ('2021-06-16 08:00:00+00'),
readings_p2021_06_16_0800 FOR VALUES FROM ('2021-06-16 08:00:00+00') TO ('2021-06-16 09:00:00+00'),
readings_default DEFAULT
test=>select pg_size_pretty(pg_total_relation_size('readings')) ;
pg_size_pretty
----------------
0 bytes
(1 row)
test=> \d+ diagnostics
Partitioned table "public.diagnostics"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------------+--------------------------+-----------+----------+---------+----------+--------------+-------------
time | timestamp with time zone | | | | plain | |
tags_id | integer | | | | plain | |
name | text | | | | extended | |
fuel_state | double precision | | | | plain | |
current_load | double precision | | | | plain | |
status | double precision | | | | plain | |
additional_tags | jsonb | | | | extended | |
Partition key: RANGE ("time")
Indexes:
"diagnostics_fuel_state_time_idx" btree (fuel_state, "time" DESC)
"diagnostics_tags_id_time_idx" btree (tags_id, "time" DESC)
"diagnostics_time_idx" btree ("time" DESC)
Partitions: diagnostics_p2021_06_08_0000 FOR VALUES FROM ('2021-06-08 00:00:00+00') TO ('2021-06-08 01:00:00+00'),
diagnostics_p2021_06_08_0100 FOR VALUES FROM ('2021-06-08 01:00:00+00') TO ('2021-06-08 02:00:00+00'),
diagnostics_p2021_06_08_0200 FOR VALUES FROM ('2021-06-08 02:00:00+00') TO ('2021-06-08 03:00:00+00'),
diagnostics_p2021_06_08_0300 FOR VALUES FROM ('2021-06-08 03:00:00+00') TO ('2021-06-08 04:00:00+00'),
diagnostics_p2021_06_08_0400 FOR VALUES FROM ('2021-06-08 04:00:00+00') TO ('2021-06-08 05:00:00+00'),
diagnostics_p2021_06_08_0500 FOR VALUES FROM ('2021-06-08 05:00:00+00') TO ('2021-06-08 06:00:00+00'),
diagnostics_p2021_06_08_0600 FOR VALUES FROM ('2021-06-08 06:00:00+00') TO ('2021-06-08 07:00:00+00'),
diagnostics_p2021_06_08_0700 FOR VALUES FROM ('2021-06-08 07:00:00+00') TO ('2021-06-08 08:00:00+00'),
diagnostics_p2021_06_08_0800 FOR VALUES FROM ('2021-06-08 08:00:00+00') TO ('2021-06-08 09:00:00+00'),
diagnostics_p2021_06_08_0900 FOR VALUES FROM ('2021-06-08 09:00:00+00') TO ('2021-06-08 10:00:00+00'),
(…)
diagnostics_p2021_06_16_0300 FOR VALUES FROM ('2021-06-16 03:00:00+00') TO ('2021-06-16 04:00:00+00'),
diagnostics_p2021_06_16_0400 FOR VALUES FROM ('2021-06-16 04:00:00+00') TO ('2021-06-16 05:00:00+00'),
diagnostics_p2021_06_16_0500 FOR VALUES FROM ('2021-06-16 05:00:00+00') TO ('2021-06-16 06:00:00+00'),
diagnostics_p2021_06_16_0600 FOR VALUES FROM ('2021-06-16 06:00:00+00') TO ('2021-06-16 07:00:00+00'),
diagnostics_p2021_06_16_0700 FOR VALUES FROM ('2021-06-16 07:00:00+00') TO ('2021-06-16 08:00:00+00'),
diagnostics_p2021_06_16_0800 FOR VALUES FROM ('2021-06-16 08:00:00+00') TO ('2021-06-16 09:00:00+00'),
diagnostics_default DEFAULT
test=> select pg_size_pretty(pg_total_relation_size('diagnostics')) ;
pg_size_pretty
----------------
0 bytes
(1 row)
test=> select count(*) from readings_p2021_06_08_0000 ;
count
---------
1297020
(1 row)
test=> select count(*) from diagnostics_p2021_06_08_0000 ;
count
---------
1297491
(1 row)
test=> select pg_size_pretty(pg_total_relation_size('diagnostics_p2021_06_08_0000')) ;
pg_size_pretty
----------------
203 MB
(1 row)
test=> select pg_size_pretty(pg_total_relation_size('readings_p2021_06_08_0000')) ;
pg_size_pretty
----------------
242 MB
(1 row)대형 테이블 두 개 대신 여러 개의 작은 테이블(파티션)을 사용합니다. 애플리케이션 관점에서 DML(삽입과 같은)은 여전히 diagnostics와 readings 테이블을 직접 대상으로 수행되지만, 데이터는 diagnostics나 readings 객체에 직접 저장되지 않습니다. 대신 PostgreSQL은 각 파티션에서 정의된 범위 간격과 삽입되는 값을 기반으로 해당 삽입을 올바른 파티션으로 자동으로 리디렉션합니다. 또한 부모 객체는 파티션을 생성하는 모델로도 사용되므로 새 파티션을 생성할 때 각 컬럼을 일일이 지정할 필요가 없습니다.
우리 예제에서 각 파티션은 time 컬럼을 기반으로 1시간의 범위 간격으로 정의됩니다. 사용자나 애플리케이션이 정의되지 않은 범위의 데이터를 수집하려고 하면 DEFAULT 파티션이 이를 포착하는 데 사용됩니다. 예를 들어, 앞의 코드에서 \d+를 사용하여 파티션 테이블을 정의함으로써 72개의 파티션을 생성했습니다. 첫 번째 파티션은 2021-06-08 00:00:00부터 2021-06-08 01:00:00까지의 데이터를, 두 번째 파티션은 2021-06-08 01:00:00부터 2021-06-08 02:00:00까지의 데이터를, 그리고 72번째 파티션은 2021-06-10 23:00:00부터 2021-07-11 00:00:00까지의 데이터를 저장합니다.
하지만 이러한 파티션으로 정의된 범위를 벗어난 데이터를 삽입하려고 하면, 예를 들어 시간 값이 2020-12-31 23:59:59(첫 번째 파티션으로 정의된 범위 이전)이거나 2021-08-15 20:00:01(미래의 값이며 정의된 파티션 범위에도 포함되지 않음)인 경우, 해당 데이터는 DEFAULT로 표시된 특수 파티션에 저장됩니다. 이 예에서 \d+ 명령을 실행하면 이 파티션이 가장 최근 파티션으로 표시됩니다.
pg_partman을 사용하는 장점 중 하나는 여러 파티션을 자동으로 생성하고 미래 범위에 대한 파티션도 생성한다는 것입니다. 본 테스트의 경우 pg_partman 함수 partman.create_parent와 그 매개변수 p_premake를 사용하여 179개의 추가 파티션을 미리 생성합니다. 목표는 처음에 필요한 것보다 더 많은 파티션을 갖는 것이지만, 향후 더많은 파티션이 필요할 수 있으므로 미리 생성해 두는 것입니다.필요할 때마다 새 파티션이 생성되도록 매시간과 같이 유지 관리 함수를 실행하는 스케쥴을 구성할 수 있습니다. 이는 pg_cron 확장을 통해 수행할 수 있습니다. 이 확장은 인스턴스 매개변수 그룹의shared_preload_libraries 매개변수에서 선언되어야 합니다. 자세한 정보는 Modifying parameters in a DB parameter group을 참조합니다.
다음 단계는 데이터베이스에 연결하고 다음 명령으로 pg_cron 확장을 생성하는 것입니다:
psql
test=> CREATE EXTENSION pg_cron;
CREATE EXTENSION확장이 설치되고 psql 클라이언트 내에서 다음 명령으로 pg_cron 스케줄러에게 새 파티션을 자동으로 생성하기 위해 pg_partman 유지 관리 절차를 실행하도록 지시할 수 있습니다:
test=> SELECT cron.schedule('@hourly', $$CALL partman.run_maintenance_proc()$$);pg_cron 확장에 대한 자세한 내용은 Scheduling maintenance with the PostgreSQL pg_cron extension을 참조합니다.
네이티브 파티션 테이블 vs 단일 테이블
접근 방식을 비교할 때, 파티션되지 않은 테이블에서 더 많은 행이 삽입될수록 데이터 수집 성능이 감소하는 반면, 파티션된 테이블의 성능은 더 일정하게 유지되는 것을 확인할 수 있습니다.
다음 차트는 단일 테이블에 더 많은 행이 수집될수록 새로운 행을 수집하는 것이 느려진다는 것을 보여줍니다(파란색 선). 이것이 최종 사용자가 매우 큰 테이블에서 데이터를 수집할 때 느끼는 속도 저하 현상입니다. 반면, 파티션된 테이블에 데이터를 수집할 때에는, 총 수집된 행 수에 관계없이 수집 속도가 일정합니다(테이블 정의가 동일했을 뿐만 아니라 데이터도 정확히 동일했다는 점을 염두에 두어야 합니다).
이는 각 파티션이 대략 동일한 양의 데이터를 보유하기 때문에 가능하며, 이는 시간이 지남에 따라 잘 분산된 수의 행이 수집되는 경우입니다.

각 데이터 포인트는 10초마다 생성됩니다. X축은 수집 시간이 아니라 두 테이블(readings와 diagnostics)에 이미 삽입된 총 행 수입니다.
데이터 수집 추적은 tsbs 도구가 10초마다 삽입된 행 수를 캡처하고 데이터 수집 중에 표시하여 이 결과를 CSV 파일로 파싱할 수 있게 해주기 때문에만 가능합니다.
인덱스 하나를 제거한 후 네이티브 파티션 테이블 vs 단일 테이블
앞서 데이터 수집 중에 중요하다고 언급한 요인 중 하나는 인덱스의 존재였습니다. 인덱스를 정렬되고 구조화된 방식으로 저장해야 하기 때문에 사용하는 인덱스의 수는 테이블 크기만큼 중요합니다. 이 섹션에서는 각 테이블에서 인덱스 하나를 제거하여 이를 보여줍니다.
readings_latitude_time_idx와 diagnostics_fuel_state_time_idx 인덱스를 제거했습니다. 이 테스트를 수행하기 위해 tsbs_load_timescaledb 프로그램을 호출할 때 매개변수 --field-index-count=1을 --field-index-count=0으로 변경했습니다.
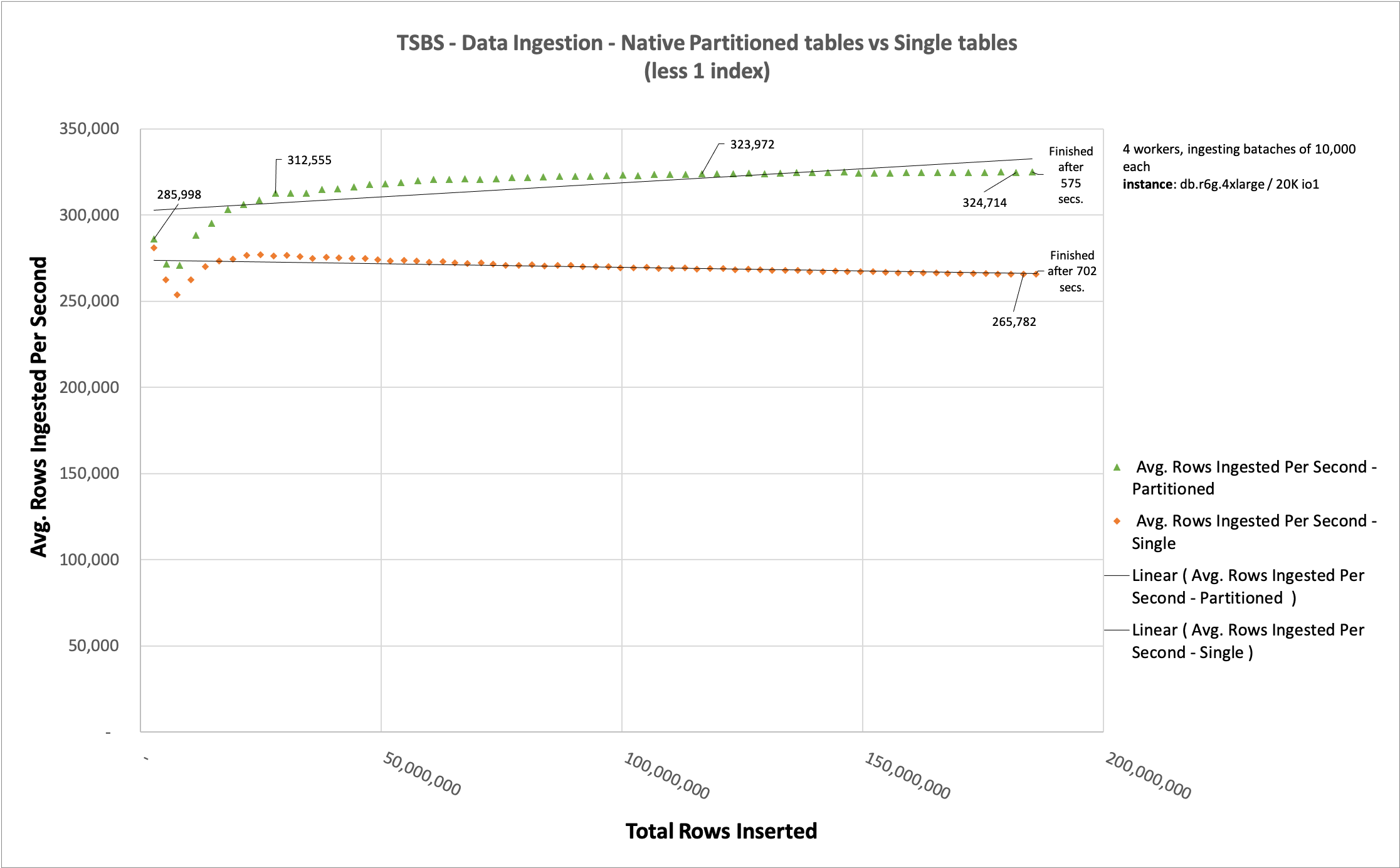
수집된 데이터는 정확히 동일합니다. 이 차트를 이전 차트와 비교할 때 유일한 차이점은 이 두 인덱스의 존재입니다. 이를 제거함으로써 파티션된 테이블과 단일 테이블 수집 간의 차이가 127초 줄어들었으며, 이전에는 그 차이가 944초였습니다.
데이터 수집에 대해 구체적으로 말하면, 테이블을 파티셔닝하는 것은 이 전략이 각 파티션의 개별 인덱스를 더 작게 만들기 때문에 데이터 수집 속도가 향상됩니다.
다른 수집 예제: pgbench
PostgreSQL 커뮤니티에는 pgbench라는 기본적이고 상대적으로 사용하기 쉬운 벤치마크 도구가 있습니다. PostgreSQL 13이 출시되었을 때, 파티션에 대해 이야기하고 있기 때문에 언급할 가치가 있는 기능이 pgbench에 도입되었습니다.
기본적으로 pgbench 도구는 초기화 모드와 벤치마킹 모드라는 두 가지 모드로 작동합니다. 이러한 모드는 하나의 매개변수인 --initialize 또는 간단히 -i로 구분됩니다. pgbench를 사용하여 벤치마킹을 처음 할 때는 초기화해야 합니다. 즉, 테이블, 기본 키, 외래 키를 생성하고 해당 객체를 채웁니다. PostgreSQL 13부터는 파티션된 방식으로 데이터셋을 초기화할 수 있습니다. 이를 위해서는 --partitions=NUM 매개변수를 사용해야 합니다.
이 매개변수는 pgbench_accounts 테이블을 파티션된 방식으로 생성한다고 말하며, NUM은 가지고 싶은 파티션 수를 정의합니다. 기본값은 0이며, 이는 테이블이 파티션되지 않음을 의미합니다.
PostgreSQL 환경 변수가 여전히 설정되어 있다는 점을 염두에 두고, 다음 명령을 사용하여 파티션된 방식으로 데이터셋을 초기화할 수 있습니다:
$ pgbench -s 100 -i --partitions=8
dropping old tables...
creating tables...
creating 8 partitions...
generating data (client-side)...
10000000 of 10000000 tuples (100%) done (elapsed 10.99 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 31.77 s (drop tables 0.05 s, create tables 0.03 s, client-side generate 11.19 s, vacuum 17.13 s, primary keys 3.37 s).
[tsbs@ip-172-31-53-9 tsbs]$ psql
psql (13.1, server 12.5)
Type "help" for help.
test=> \d+ pgbench_accounts
Partitioned table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------------+-----------+----------+---------+----------+--------------+-------------
aid | integer | | not null | | plain | |
bid | integer | | | | plain | |
abalance | integer | | | | plain | |
filler | character(84) | | | | extended | |
Partition key: RANGE (aid)
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Partitions: pgbench_accounts_1 FOR VALUES FROM (MINVALUE) TO (1250001),
pgbench_accounts_2 FOR VALUES FROM (1250001) TO (2500001),
pgbench_accounts_3 FOR VALUES FROM (2500001) TO (3750001),
pgbench_accounts_4 FOR VALUES FROM (3750001) TO (5000001),
pgbench_accounts_5 FOR VALUES FROM (5000001) TO (6250001),
pgbench_accounts_6 FOR VALUES FROM (6250001) TO (7500001),
pgbench_accounts_7 FOR VALUES FROM (7500001) TO (8750001),
pgbench_accounts_8 FOR VALUES FROM (8750001) TO (MAXVALUE)이 파티션이 구현되는 방식에 주목합니다. 8개의 파티션을 가진 범위 파티셔닝 방법을 사용하며, 파티션 1은 1250001보다 작은 모든 값을 받아들이고 파티션 8은 8750001보다 큰 모든 값을 허용합니다.
하지만 이는 이상적인 방식은 아닙니다. 테이블이 계속 증가하는 경우(파티션 키(aid)가 계속 새로운 값을 받는 시나리오를 가정), 파티션 8(pgbench_accounts_8)이 다른 파티션보다 훨씬 많은 값을 갖게 됩니다. 파티션 8이 과도하게 치우치는 것을 방지하려면 aid가 10,000,000에 도달하기 전에 파티션 9를 추가해야 합니다.
파티셔닝의 또 다른 접근 방식은 범위 방법이 아닌 해시 파티션 방법을 사용하는 것입니다. 이름에서 알 수 있듯이 해시 방법은 해시 함수에 의존하여 미리 결정된 수의 파티션에 행을 분산시킵니다. 이는 기본 키나 동등하게 분산될 수 있다고 알고 있는 값으로 파티셔닝하고 이러한 특정 행에 대한 액세스가 의사 무작위화되는 경우에 특히 유용합니다. 해시 파티션은 모든 파티션을 서로 동일한 상대적 크기로 유지하지만, 테이블에 더 많은 값이 추가됨에 따라 파티션의 크기가 증가합니다. 이는 범위 분할 방식 파티션의 성능 이점을 줄이거나 심지어 사라지게 할 수 있습니다.
pgbench는 PostgreSQL 13에서 해시 또는 범위 파티셔닝을 허용하는 partition-method라는 또 다른 매개변수를 도입했습니다. 기본적으로 범위 파티셔닝이 사용되며, 각 파티션은 파티션 키의 특정 내부를 처리하는 데 사용됩니다.
해시로 파티션된 테이블이 어떻게 보이는지 설명하기 위해, 앞서 했던 것처럼 pgbench -s 100 -i --partitions=8을 실행하는 대신, 이제 파티션에 해시 방법을 사용하여 벤치마크를 초기화하도록 지정합니다. 이를 위해 다음 명령을 사용합니다:
$ pgbench -s 100 -i --partitions=8 --partition-method=hash
dropping old tables...
creating tables...
creating 8 partitions...
generating data (client-side)...
10000000 of 10000000 tuples (100%) done (elapsed 10.02 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 26.94 s (drop tables 0.39 s, create tables 0.03 s, client-side generate 10.27 s, vacuum 12.66 s, primary keys 3.60 s).분할된 테이블은 다음과 같습니다.
test=> \d+ pgbench_accounts
Partitioned table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------------+-----------+----------+---------+----------+--------------+-------------
aid | integer | | not null | | plain | |
bid | integer | | | | plain | |
abalance | integer | | | | plain | |
filler | character(84) | | | | extended | |
Partition key: HASH (aid)
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Partitions: pgbench_accounts_1 FOR VALUES WITH (modulus 8, remainder 0),
pgbench_accounts_2 FOR VALUES WITH (modulus 8, remainder 1),
pgbench_accounts_3 FOR VALUES WITH (modulus 8, remainder 2),
pgbench_accounts_4 FOR VALUES WITH (modulus 8, remainder 3),
pgbench_accounts_5 FOR VALUES WITH (modulus 8, remainder 4),
pgbench_accounts_6 FOR VALUES WITH (modulus 8, remainder 5),
pgbench_accounts_7 FOR VALUES WITH (modulus 8, remainder 6),
pgbench_accounts_8 FOR VALUES WITH (modulus 8, remainder 7)해시 방법을 사용하면 파티션 컬럼(aid)에 대해 미리 결정된 범위를 갖는 대신, aid 컬럼에 대해 8(파티션 수)의 모듈러스를 적용합니다. 그런 다음 나머지에 따라 특정 행을 저장할 결정된 파티션이 선택됩니다.
파티션 방법 결합: 서브 파티션
시계열 데이터 수집에 대해 구체적으로 말하면, 범위 방법(타임스탬프 컬럼을 처리하여 행이 어느 서브 파티션에 있어야 하는지 정의)을 결합할 수 있습니다. 그런 다음 기본 키에 해시 방법을 사용하여 더 균등하게 분산되고 더 작은 파티션을 보장할 수 있습니다.
다음 코드는 readings라는 테이블과 서브 파티션된 테이블을 생성합니다:
CREATE TABLE readings ( time timestamp with time zone, tags_id integer
, latitude double precision
, longitude double precision
, elevation double precision
, velocity double precision
, heading double precision
, grade double precision
, fuel_consumption double precision
, additional_tags jsonb)
PARTITION BY RANGE (time);
CREATE TABLE readings_p_00001_2021_01_01_00_00
PARTITION OF readings FOR VALUES
FROM ('2021-01-01 00:00:00+00') TO ('2021-01-01 02:00:00+00')
PARTITION BY HASH (tags_id);
CREATE TABLE readings_p_00001_2021_01_01_00_00_sub01
PARTITION OF readings_p_00001_2021_01_01_00_00
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE readings_p_00001_2021_01_01_00_00_sub02
PARTITION OF readings_p_00001_2021_01_01_00_00
FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE readings_p_00001_2021_01_01_00_00_sub03
PARTITION OF readings_p_00001_2021_01_01_00_00
FOR VALUES WITH (MODULUS 3, REMAINDER 2);
CREATE TABLE readings_p_00002_2021_01_01_02_00
PARTITION OF readings FOR VALUES
FROM ('2021-01-01 02:00:00+00') TO ('2021-01-01 04:00:00+00')
PARTITION BY HASH (tags_id);
CREATE TABLE readings_p_00001_2021_01_01_02_00_sub01
PARTITION OF readings_p_00002_2021_01_01_02_00
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE readings_p_00001_2021_01_01_02_00_sub02
PARTITION OF readings_p_00002_2021_01_01_02_00
FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE readings_p_00001_2021_01_01_02_00_sub03
PARTITION OF readings_p_00002_2021_01_01_02_00
FOR VALUES WITH (MODULUS 3, REMAINDER 2);
CREATE TABLE readings_DEFAULT PARTITION OF readings DEFAULT;readings 테이블은 다중 계층 파티션된 접근 방식을 사용하며, 먼저 time 컬럼을 범위로 사용하여 특정 간격으로 결정된 여러 파티션에 데이터를 분산시킵니다. 우리는 이를 서브 파티셔닝이라고 부릅니다. readings 테이블 아래에는 time 컬럼에 대한 범위를 사용하여 정의된 두 개의 파티션과 하나의 기본 파티션이 있습니다. 범위로 정의된 이 두 파티션 각각 아래에 서브 파티션이 있습니다. 우리 예제에서는 tags_id 컬럼에서 해시 파티셔닝을 사용하여 파티션된 세 개의 서브 파티션이 있습니다. 이러한 파티션은 모든 데이터를 저장하는 리프 파티션입니다. 최하위 리프 파티션 위의 다른 모든 파티션은 비어 있습니다. 이들은 올바른 서브 파티션을 찾는 경로로 사용되어 읽을 때 더 빠른 액세스를 허용합니다. 또한 파티션으로 정의한 범위 외부의 모든 범위를 처리하기 위해 기본 파티션을 생성합니다.
요약
이 포스트에서는 Amazon RDS for PostgreSQL 또는 Amazon Aurora PostgreSQL-Compatible Edition에서 사용할 수 있는 PostgreSQL 네이티브 파티션 기능을 활용하여 데이터 수집 속도를 높이는 방법을 다뤘습니다. 파티셔닝의 아이디어는 데이터베이스 엔진이 단일 대형 테이블을 처리하는 것과 비교하여 더 작은 데이터 청크를 처리할 때 더 나은 성능을 발휘한다는 것입니다. 이는 테이블을 읽어야 할 때뿐만 아니라 새로운 데이터 행을 수집할 때도 마찬가지입니다. 파티션된 테이블은 더 큰 데이터셋을 분할하여 엔진이 단일 대형 테이블과 비교하여 더 작은 데이터 청크를 사용함으로써 더 나은 성능을 얻을 수 있도록 합니다.
또한 데이터 수집 성능에 기여하는 다섯 가지 요인인 테이블 크기, 인덱스, 수집 방법, 체크포인트, 가용 영역에 대해서도 논의했습니다.
그런 다음 벤치마크를 사용하여 파티션된 테이블을 사용하여 820.360초에 186,706,431개의 행을 수집하는 것과 파티션되지 않은 테이블을 사용하여 1784.768초에 수집하는 것을 비교하여 성능 향상을 보여주었습니다(수집 시간 54% 감소).
마지막으로, 각 테이블에서 하나의 인덱스를 제거한 후 동일한 데이터 수집을 비교했습니다. 파티션된 테이블은 모든 186,706,431개의 행을 127초에 수집했고, 파티션되지 않은 테이블은 994초가 걸렸으며, 이는 데이터 수집에 대한 인덱스의 영향을 보여줍니다.