AWS 기술 블로그
티로의 Amazon Bedrock과 RDS를 활용한 대화 기록 기반 Ask Tiro 구현
매일 쏟아지는 회의 내용, 강의 녹음, 팀 미팅 기록들이 쌓여가면 쌓여갈수록 필요한 정보를 빠르게 찾는 것은 점점 더 어려워집니다. “지난주 온보딩 프로젝트에서 논의된 핵심 이슈가 뭐였지?”, “지난주 A 기업과의 미팅에서 결정된 주요 사항들이 뭐였지?”와 같이 대화 기록을 기반으로 한 고-맥락의 질문에 답하려면 수 많은 대화 기록을 일일이 찾아 봐야 하는 번거로움이 생기기 마련 입니다.
티로(Tiro) 는 이러한 문제를 해결하면서 동시에 사용자가 티로를 사용해 중요한 대화 기록을 쌓아갈 수록, 더 큰 가치를 제공하고자 했습니다. 이를 위해 Amazon Bedrock과 Amazon RDS for PostgreSQL을 활용하여 “Ask Tiro” 기능을 개발했습니다. 이 기능을 통해 사용자들은 축적된 중요한 대화 기록들에 대해 자연어로 질문하고, 티로로부터 맥락을 이해한 정확한 답변을 받을 수 있게 되었습니다.
그림 1. Tiro 메인 대시보드 스크린샷
이번 글에서는 티로가 대화 기록 기반 질의응답 시스템인 “Ask Tiro” 를 어떻게 구현했는지, 그리고 Amazon Bedrock과 RDS를 활용하여 어떤 방식으로 안정적으로 서비스를 제공하며 사용자 경험을 극대화했는지에 대해 자세히 살펴보겠습니다.
티로의 아키텍처 및 Ask Tiro 처리 프로세스
티로는 Amazon Bedrock을 핵심으로 하여 다양한 AWS 서비스들을 활용해 Ask Tiro를 구현했습니다. Amazon Bedrock은 다양한 생성형 AI 모델을 완전 관리형 서비스로 제공하는 플랫폼입니다. Bedrock은 Anthropic, Amazon, Cohere, Meta 등 주요 AI 기업들의 파운데이션 모델들을 통합 API로 제공하여, 복잡한 모델 관리 없이도 최적의 AI 솔루션을 안정적으로 제공할 수 있도록 해줍니다.
티로 팀에서는 여러 프로바이더사에서 제공하는 여러 LLM 모델들에 대해 쿼리 생성 성능, 응답 생성 성능을 기반으로 꼼꼼한 내부 테스트를 진행했습니다. 그 결과, 티로 팀에서는 Ask Tiro를 이루는 두 기능 모두에 자연어 이해와 맥락 파악 성능이 가장 뛰어난 Claude 4.0 Sonnet을 도입하기로 최종 선택했습니다. Bedrock의 안정적인 관리형 인프라 덕분에 서비스 장애 걱정 없이 Claude 4.0 Sonnet의 강력한 성능을 안정적으로 활용할 수 있었습니다. 실제로 Bedrock에서 Claude 4.0 Sonnet을 서비스한 이래로 6개월이 넘는 기간동안 Ask Tiro 기능에서 LLM 관련 문제는 단 한건도 발생하지 않았습니다.
|
모델 |
제공자 | 평균 응답 시간 |
선택 근거 및 테스트 결과 |
|---|---|---|---|
| Claude 4 Sonnet | Amazon Bedrock | 450ms | 다국어 맥락 이해와 hallucination 저감에서 최고 성능. 쿼리의 의도파악 및 자연어로 답변 생성하는 기능 모두 가장 뛰어남. 내부 테스트에서 92% 이상 정확도 달성. Bedrock 통합으로 안정적 latency와 availability 유지. |
| GPT-4.1 | OpenAI (Azure) | 350ms | 응답 속도 우수하나, 복잡한 대화 기록 맥락에서 hallucination 발생률이 15%이상 높음. 창의적 응답 강점 있지만, 티로의 정확성 요구사항 미달. 또한 쿼리 생성시에 의도 파악 능력이 Sonnet 4.0에 비해 12% 이상 떨어짐. |
| Gemini 2.5 Pro | Google
(GCP) |
550ms | 비용 효율적이고 쿼리 의도파악 정확도 높음. 그러나 테스트 환경에서 latency가 비교적 길고, 특히 한국어에서 자연스러운 대답 생성 능력이 만족스럽지 못했음. 맥락 파악후 답변을 생성하는 능력에서 Sonnet에 비해 아쉬웠다고 평가함. |
| Claude 3.5 Sonnet | Amazon Bedrock | 450ms | Sonnet 계열 모델은 자연어 응답 생성시 맥락 이해와 자연스러운 답변 생성 능력에서 뛰어난 모습을 보임. 다만 Sonnet 4.0과 비용차이가 없고, Sonnet 4.0이 글쓰기, 맥락 파악 등에서 더 우수한 모습을 보임. |
Ask Tiro의 질의응답 워크플로우는 다음과 같은 과정으로 수행됩니다:
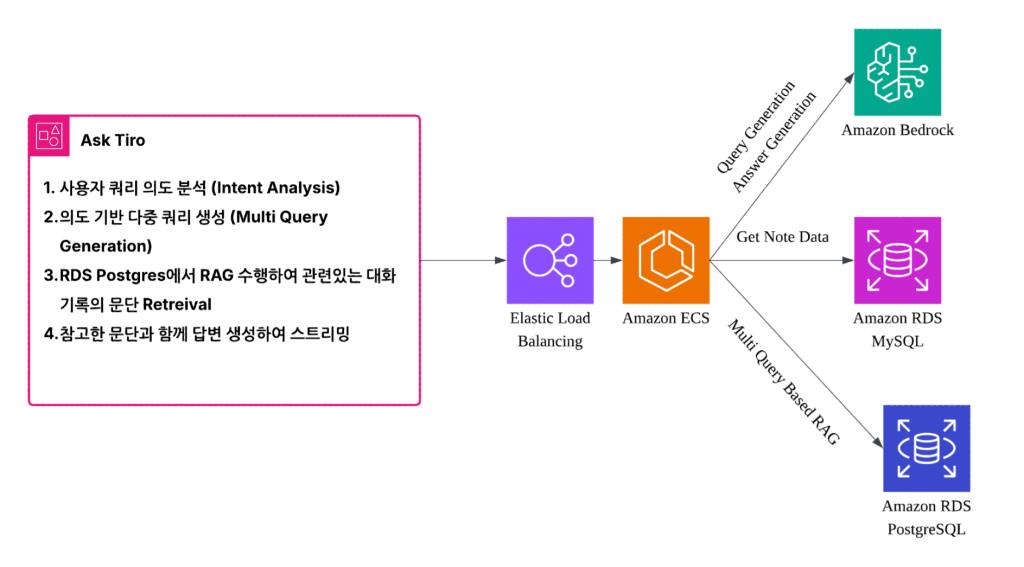
그림 2. Ask Tiro 처리 프로세스 플로우차트
1. 사용자 쿼리 의도 분석
- 사용자가 자연어 질문을 입력합니다 (예: “이번 2주 동안 온보딩 프로젝트에서 해야 할 일이 뭐야?”)
- Amazon Bedrock의 Claude 3.5 Sonnet 모델을 사용해 쿼리 의도를 분석하고 다음 세 가지 유형으로 분류합니다:
- 특정 도메인/상황 질문: 특정 프로젝트나 주제 관련 질문
- 용어 검색: 특정 용어나 개념의 정의를 찾는 질문
- 시간/추상적 질문: 시간 범위나 추상적 개념을 포함한 질문
2. 다중 쿼리 생성
분석된 의도를 바탕으로 세 가지 특화된 쿼리를 생성합니다:
- filterQuery: RAG 대상 풀을 필터링 (폴더/노트 범위, 시간 필터 등)
- searchQuery: 벡터 검색을 위한 핵심 키워드 추출
- intentionQuery: 최종 답변 생성 시 사용할 의도가 반영된 프롬프트
3. RAG(Retrieval-Augmented Generation) 수행
Ask Tiro의 핵심 강점은 폴더 기반 검색입니다. 사용자는 전체 노트에서 질문할 수도 있고, 특정 주제별로 구성된 폴더 내에서만 검색할 수도 있습니다.
- 1단계 필터링: filterQuery를 사용해 Amazon RDS for PostgreSQL에서 선택된 폴더나 시간 범위 내 대화 기록으로 범위를 좁힙니다.
- 2단계 벡터 검색: searchQuery를 Bedrock의 임베딩 모델로 벡터화하고, pgvector 확장의 HNSW 인덱스를 통해 유사도 검색을 수행합니다.
- 3단계 답변 생성: 검색된 관련 컨텍스트와 intentionQuery를 Claude 모델에 입력하여 정확한 답변을 생성합니다.
4. 검증 및 응답 제공
생성된 답변의 품질을 검증하고, 참조 소스 정보와 함께 사용자에게 제공합니다.
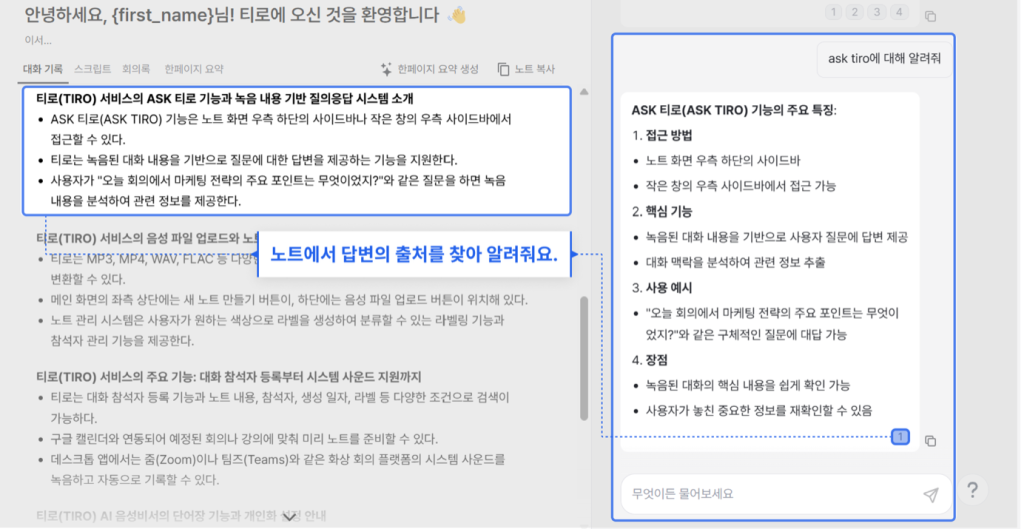
그림 3. Ask Tiro 결과물 스크린샷
Amazon Bedrock을 도입한 이유
Tiro가 Ask Tiro 기능 구현을 위해 Amazon Bedrock을 선택한 데에는 여러 이유가 있습니다. 특히 다국어 처리 능력과 기존 AWS 인프라와의 원활한 통합이 주요 결정 요인이었습니다.
탁월한 다국어 의도 분석 능력
Tiro는 12개 언어를 지원하는 글로벌 서비스로, 131개국의 사용자들이 이용하고 있습니다. Claude 4 Sonnet은 다양한 언어의 사용자 쿼리에서 의도를 정확하게 파악하는 데 탁월한 성능을 보여주었습니다.
예를 들어, 다음과 같은 다국어 쿼리들을 모두 정확하게 이해하고 처리할 수 있습니다:
|
언어 |
사용자 쿼리 |
분석된 의도 |
|---|---|---|
| 한국어 | “지난주 마케팅 회의에서 나온 액션 아이템들” | 특정 도메인 + 시간 필터 |
| 영어 | “What were the key decisions in our product roadmap discussion?” | 특정 도메인 + 핵심 정보 추출 |
| 일본어 | “プロジェクトの進捗について話し合った内容” | 특정 도메인 + 진행 상황 |
기존 AWS 서비스와의 연동성
티로는 이미 Amazon RDS, Lambda, S3 등 다양한 AWS 인프라를 활용해 안정적이고 확장 가능한 서비스를 제공하고 있었습니다. Bedrock은 AWS 생태계 내에서 작동하기 때문에 기존 서비스들과의 통합이 원활하며, 데이터가 외부로 이동할 필요 없이 AWS 네트워크 안에서 처리됩니다.
이로 인해 네트워크 레이턴시가 줄어들었고, 평균 450ms의 빠른 응답 시간을 달성할 수 있었습니다. 특히 RDS에 저장된 대화 기록을 Bedrock으로 바로 전달하고, 처리된 결과를 실시간으로 사용자에게 제공하는 전체 워크플로우가 매끄럽게 연결되었습니다.
Amazon RDS for PostgreSQL을 선택한 이유
높은 성능의 Ask Tiro를 제공하기 위해서는 올바른 쿼리로부터 정확한 벡터 검색을 통해 가장 관련성 높은 대화 기록과 노트를 가져오는 것이 핵심입니다. 이를 위한 벡터 데이터베이스로 Amazon RDS for PostgreSQL을 선택한 이유는 다음과 같습니다:
pgvector 확장을 통한 고성능 벡터 검색
PostgreSQL의 pgvector 확장과 HNSW 인덱스를 활용하여 대규모 벡터 데이터에서도 빠른 유사도 검색이 가능합니다. 10,000개 이상의 대화 기록에서도 평균 50ms 이내의 검색 성능을 보장합니다.
안정적이고 비용 효율적인 관리형 서비스
벡터 검색을 위해 별도의 인프라를 구축하고 관리하는 대신, AWS의 완전 관리형 서비스를 활용하여 유지보수 부담을 최소화했습니다. Pinecone과 같은 전용 벡터 데이터베이스 대비 약 30% 비용을 절감할 수 있었습니다.
확장 가능한 사전 필터링 지원
월간 80% 성장률로 기하급수적으로 늘어나는 티로의 노트 데이터에 대해, 기존 관계형 데이터와 벡터 검색을 하나의 쿼리로 처리할 수 있습니다. 이를 통해 시간 범위, 폴더, 참여자 등의 복잡한 필터링 조건을 벡터 유사도 검색과 효율적으로 결합하여 정확한 결과를 빠르게 제공할 수 있습니다.
Ask Tiro의 Bedrock 활용 사례
티로는 Ask Tiro 기능 구현 시 쿼리 의도 분석, 다중 쿼리 생성, 그리고 최종 답변 생성 단계에서 Bedrock을 핵심적으로 활용했습니다. 각 단계에서 어떻게 Bedrock을 활용했는지 프롬프트 예시와 함께 살펴보겠습니다.
사용자 쿼리 의도 분석하기
사용자의 자연어 질문을 정확히 이해하는 것이 Ask Tiro의 핵심입니다. 단순한 키워드 매칭이 아닌, 사용자의 진짜 의도를 파악하여 적절한 검색 전략을 수립해야 합니다.
컨텍스트 기반 답변 생성하기
RAG를 통해 검색된 관련 대화 기록들을 바탕으로, 사용자의 질문에 정확하고 유용한 답변을 생성합니다. 이 과정에서 Hallucination을 방지하고, 검색된 컨텍스트에 기반한 신뢰할 수 있는 답변만을 제공 하도록 설계했습니다.
INPUT:
{
"user_question": "string",
"conversation_contexts": [
{
"title": "string",
"date": "string",
"participants": ["string"],
"content": "string"
}
]
}OUTPUT:
{
"answer": "string",
"sources": ["string"],
"confidence": "high|medium|low"
}마무리
이번 글에서는 티로가 Amazon Bedrock과 RDS for PostgreSQL을 활용하여 대화 기록 기반 질의응답 시스템을 구현한 사례를 소개했습니다. 티로는 Bedrock의 강력한 자연어 이해 능력과 RDS의 확장 가능한 벡터 검색 기능을 결합하여, 사용자들이 축적된 대화 기록에서 필요한 정보를 자연스럽게 찾을 수 있는 경험을 제공했습니다.
특히 다국어 지원과 의도 기반 쿼리 분석을 통해 글로벌 사용자들의 다양한 요구사항을 만족시키면서도, AWS 생태계의 장점을 활용하여 비용 효율적이고 확장 가능한 솔루션을 구축할 수 있었습니다.