O blog da AWS
Como exportar para as tabelas do Amazon S3 usando o Distributed Map do AWS Step Functions
Por Chetan Makvana, Sr. Solutions Architect e Aidan Eglin, Software Development Manager.
As empresas que executam cargas de trabalho Serverless geralmente precisam realizar operações de extração, transformação e carregamento (ETL) em arquivos de dados armazenados em buckets do Amazon Simple Storage Service (Amazon S3). Embora abordagens tradicionais, como um trigger do AWS Lambda para Amazon S3 ou notificações de eventos do Amazon S3, possam lidar com essas operações, elas podem falhar quando os fluxos de trabalho exigem maior visibilidade, controle ou intervenção humana. Por exemplo, alguns processos podem precisar de revisão manual de registros reprovados ou aprovação explícita antes de prosseguir para as etapas subsequentes. As soluções de orquestração de clientes para esses problemas podem se mostrar complexas e propensas a erros.
O AWS Step Functions aborda esses desafios fornecendo recursos integrados de gerenciamento e monitoramento do fluxo de trabalho. O recurso Distributed Map do Step Functions foi projetado para fluxos de trabalho de processamento de dados paralelos e de alto rendimento, para que as empresas possam lidar com tarefas complexas de ETL, processamento distribuído e visualização de dados em grande escala. O Distributed Map trata cada item do conjunto de dados como um fluxo de trabalho secundário independente, processando milhões de registros enquanto mantém controles de simultaneidade integrados, tolerância a falhas e rastreamento de progresso. Os dados processados podem ser exportados sem problemas para vários destinos, incluindo tabelas do Amazon S3 com suporte ao Apache Iceberg.
Nests publicação, mostramos como usar o Step Functions Distributed Map para processar objetos do Amazon S3 e exportar resultados para tabelas do Amazon S3, criando um pipeline de processamento de dados escalável e sustentável.
Consulte o repositório associado do GitHub para obter instruções detalhadas sobre a implantação dessa solução, bem como o código de amostra.
Visão geral da solução
Considere uma empresa de eletrônicos de consumo que participa regularmente de feiras e conferências do setor. Durante esses eventos, os participantes interessados preenchem formulários de inscrição em papel para solicitar demonstrações de produtos, receber boletins informativos ou participar de programas de acesso antecipado. Após os eventos, a equipe da empresa digitaliza centenas de milhares desses formulários e os envia para o Amazon S3. Em vez de revisar cada formulário manualmente, a empresa deseja automatizar a extração dos principais detalhes do cliente, como nome, endereço de e-mail, endereço para correspondência e áreas de interesse. Eles gostariam de armazenar esses dados estruturados em tabelas S3 com o formato Apache Iceberg para análises posteriores e segmentação de campanhas de marketing.
Vamos ver como a solução desta postagem usa o Distributed Map para processar PDFs em paralelo, extrair dados usando o Amazon Textract e gravar a saída limpa diretamente nas tabelas do S3. O resultado é uma integração de dados pós-evento escalável e serverless, conforme mostrado na figura a seguir.
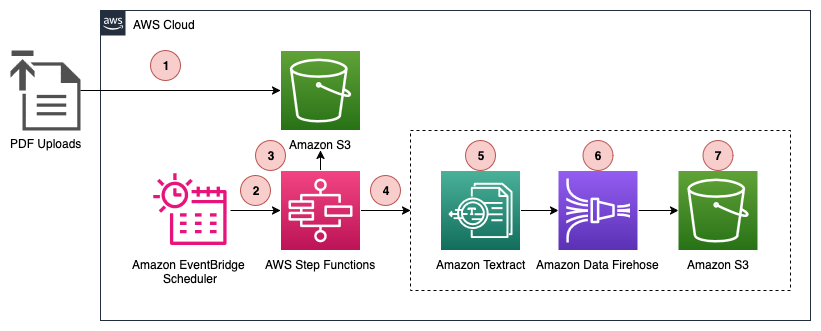
O fluxo de trabalho de processamento de dados, conforme mostrado no diagrama anterior, inclui as seguintes etapas:
- Um usuário carrega formulários de interesse do cliente como PDFs digitalizados em um bucket do Amazon S3.
- Uma regra do Amazon EventBridge Scheduler é acionada em intervalos regulares, iniciando a execução do fluxo de trabalho do Step Functions.
- A execução do fluxo de trabalho ativa o estado do Step Functions Distributed Map, que lista todos os arquivos PDF enviados para o Amazon S3 desde a execução anterior.
- O Distributed Map itera a lista de objetos e passa os metadados de cada objeto (bucket, chave, tamanho, tag de entidade [ETag]) para a execução de um fluxo de trabalho secundário.
- Para cada objeto, o fluxo de trabalho secundário chama o Amazon Textract com o bucket e a chave fornecidos para extrair texto bruto e campos relevantes (nome, endereço de e-mail, endereço postal, área de interesse) do PDF.
- O fluxo de trabalho secundário envia os dados extraídos para o Amazon Data Firehose, que está configurado para encaminhar dados para as tabelas do S3.
- O Firehose agrupa os dados recebidos do fluxo de trabalho secundário e os grava nas tabelas do S3 em um intervalo de tempo pré-configurado de sua escolha.
Com os dados agora estruturados e acessíveis nas tabelas do S3, os usuários podem analisá-los facilmente usando consultas SQL padrão com o Amazon Athena ou inteligência de negócios como o Amazon QuickSight.
O fluxo de trabalho de processamento de dados
O EventBridge Scheduler inicia novos fluxos de trabalho do Step Functions em intervalos regulares. O intervalo para esse cronograma é flexível. No entanto, ao configurar sua agenda, verifique se a frequência está alinhada com a data em que sua máquina de estado está configurada para procurar PDFs. Por exemplo, se sua máquina de estado verificar os PDFs da semana passada, convém programá-la para ser executada semanalmente. Posteriormente, o fluxo de trabalho do Step Functions executa as três etapas a seguir (observe que essas etapas são as etapas 4, 5, 6 e 7 no diagrama de fluxo de trabalho anterior):
- Extraia dados relevantes do usuário dos PDFs.
- Envie os dados extraídos do usuário para o Firehose.
- Grave os dados nas tabelas do S3 no formato de tabela Apache Iceberg.
O diagrama a seguir ilustra esse fluxo de trabalho.
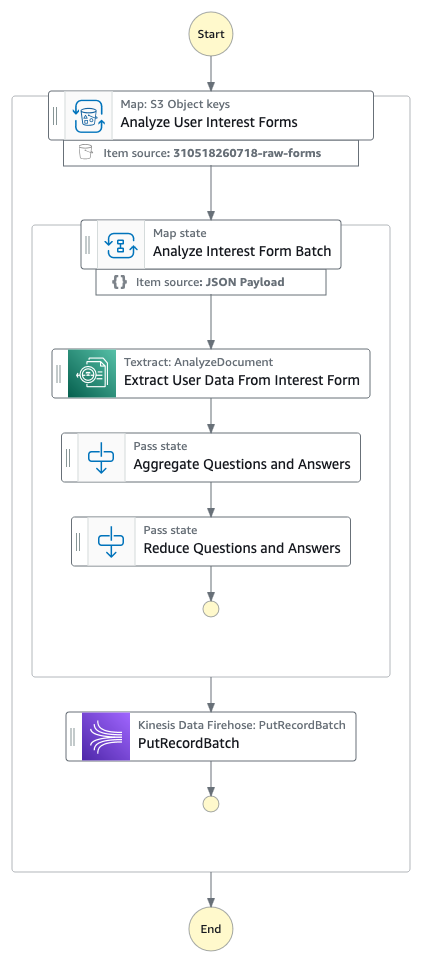
Vamos examinar cada etapa do fluxo de trabalho anterior com mais detalhes.
Extrair dados relevantes do usuário de documentos PDF
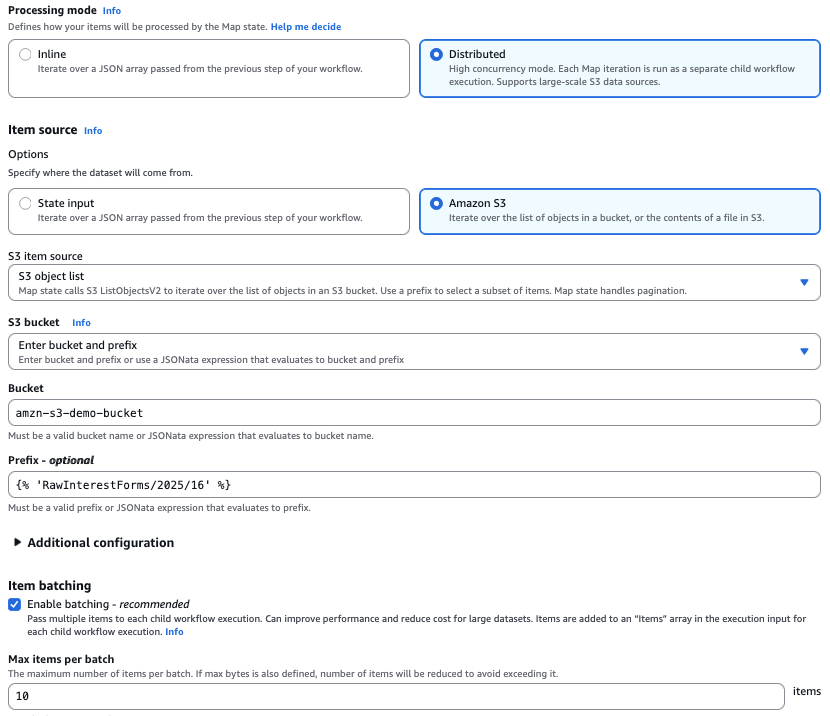
O Step Functions usa o Distributed Map para processar PDFs simultaneamente em fluxos de trabalho secundários paralelos. Ele aceita entradas de arquivos JSON, JSONL, CSV, Parquet, arquivos de manifesto do Amazon S3 armazenados no Amazon S3 (usados para especificar arquivos específicos para processamento) ou de um prefixo de bucket do Amazon S3 (permite a iteração dos metadados do arquivo para todos os objetos sob esse prefixo). O Step Functions gerencia automaticamente a paralelização dividindo o conjunto de dados e executando fluxos de trabalho secundários para cada item, com o campo ItemBatcher permitindo agrupar vários PDFs em uma única execução de fluxo de trabalho secundário (por exemplo, 10 PDFs por lote) para otimizar o desempenho e o custo.
A captura de tela a seguir do console do Step Functions mostra a configuração do Distributed Map. Por exemplo, configuramos o Distributed Map para processar 10 PDFs de interesse do cliente em um único fluxo de trabalho secundário.
A imagem a seguir mostra um exemplo desses PDFs digitalizados, que inclui as informações do cliente que a solução desta publicação processa.
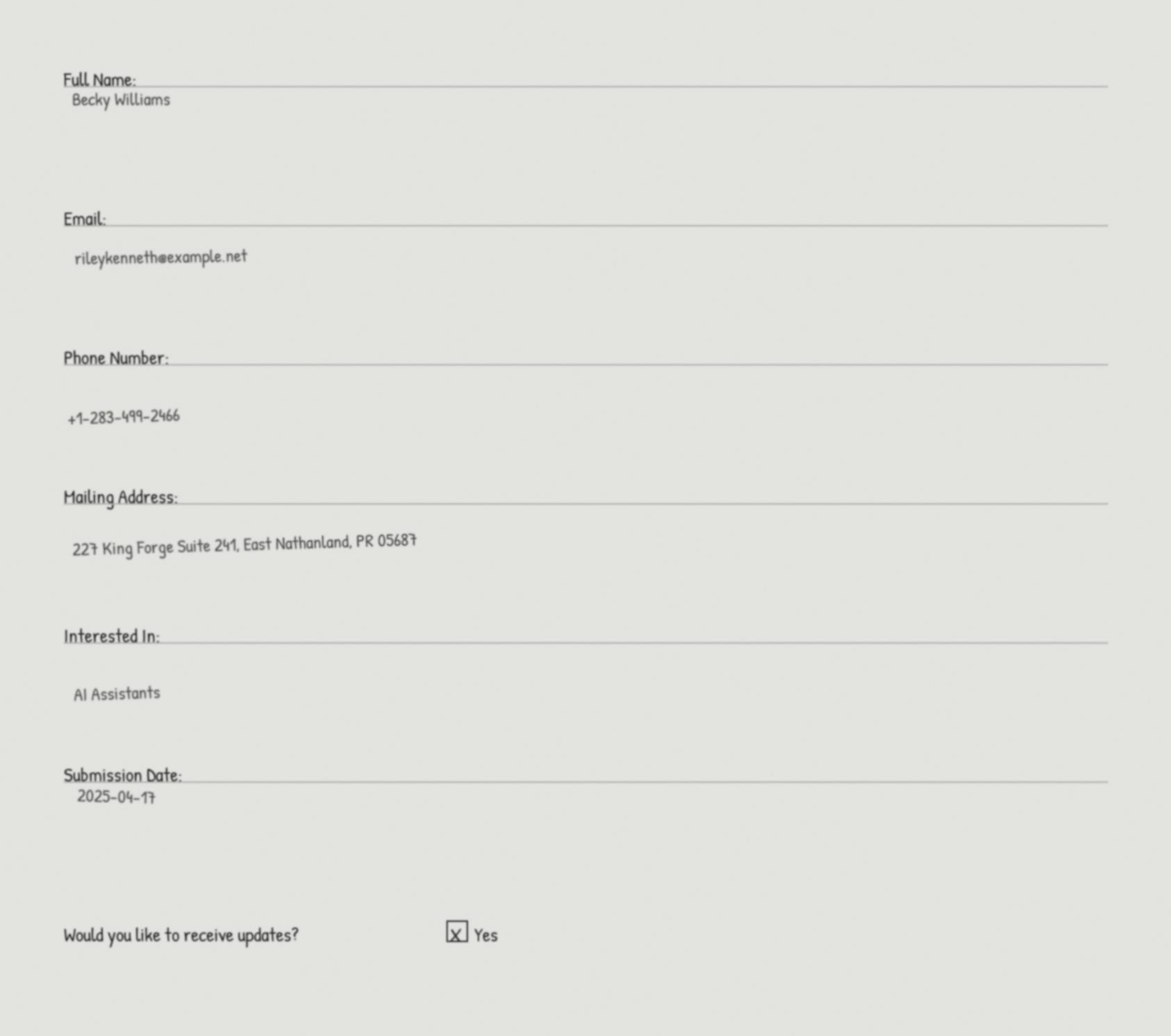
Em seguida, cada fluxo de trabalho secundário chama a API Amazon Textract AnalyzeDocument com consultas específicas para extrair informações do cliente.
A API analisa cada PDF digitalizado e retorna uma estrutura JSON contendo as informações extraídas do cliente.
Enviar os dados extraídos do usuário para o Firehose
Em seguida, o fluxo de trabalho secundário usa uma ação da API Firehose PutRecordBatch com integrações de serviços para enfileirar as informações extraídas do cliente para processamento posterior. A solicitação de ação putRecordBatch inclui o nome do stream do Firehose e os registros de dados. Os registros de dados incluem um blob de dados da etapa 1 que contém informações extraídas do cliente, conforme mostrado no exemplo a seguir.
Gravar os dados nas tabelas do S3 no formato de tabela Apache Iceberg
O Firehose gerencia com eficiência o buffer de dados, a conversão de formatos e a entrega confiável para vários destinos, incluindo Apache Iceberg, arquivos brutos no Amazon S3, no Amazon OpenSearch Service ou em qualquer outro destino compatível. As tabelas do Apache Iceberg podem ser autogerenciadas no Amazon S3 ou hospedadas nas tabelas do S3. Embora as tabelas Iceberg autogerenciadas exijam otimização manual, como compactação e expiração de instantâneos, as tabelas S3 otimizam automaticamente o armazenamento para cargas de trabalho de análise em grande escala, melhorando o desempenho das consultas e reduzindo os custos de armazenamento.
O Firehose simplifica o processo de streaming de dados configurando um fluxo de entrega, selecionando uma fonte de dados e definindo uma tabela Iceberg como destino. Depois de configurá-lo, o stream do Firehose está pronto para fornecer dados. Os dados fornecidos podem ser consultados nas tabelas do S3 usando o Athena, conforme mostrado na captura de tela a seguir do console do Athena.
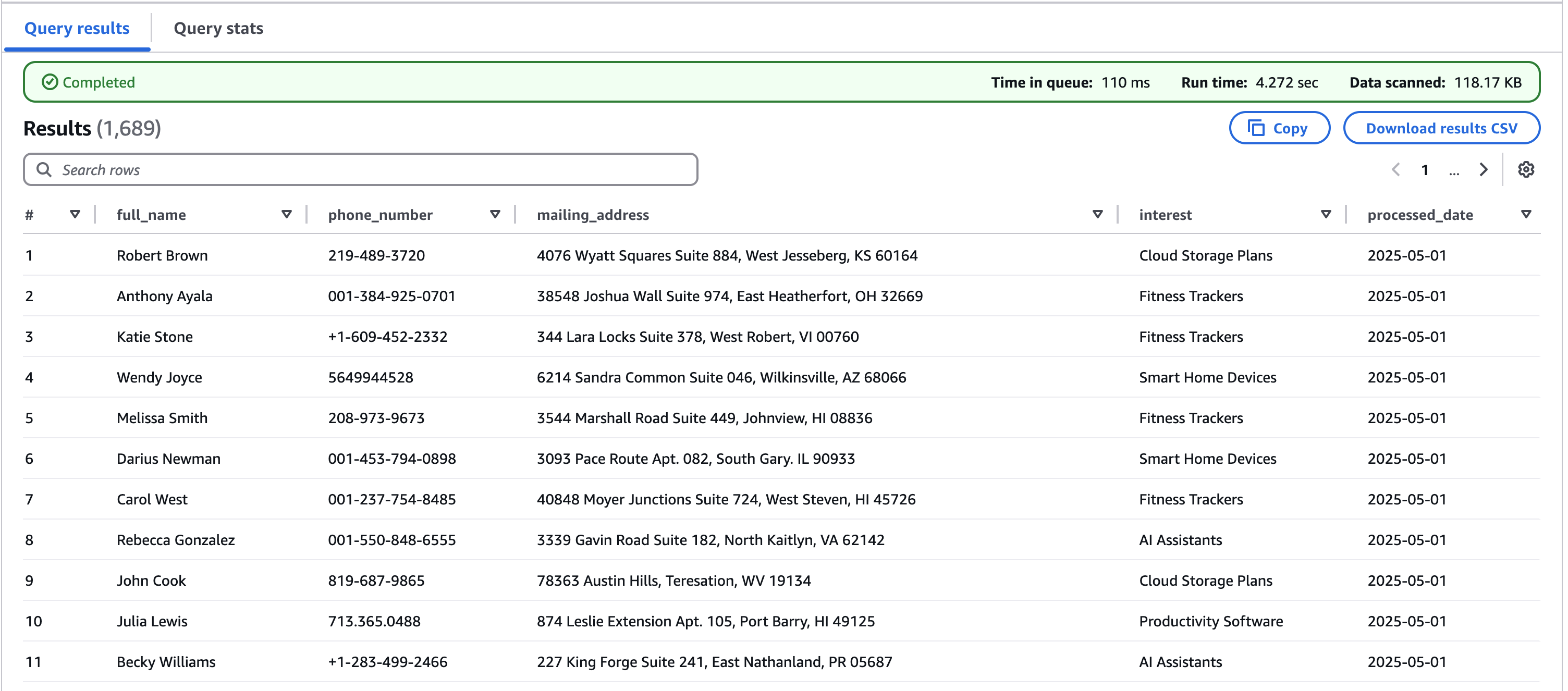
Os resultados da consulta incluem todos os dados processados do cliente a partir dos PDFs, conforme mostrado na captura de tela a seguir.
Essa integração demonstra uma solução poderosa e sem código para transformar formulários PDF brutos em dados enriquecidos e consultáveis em uma tabela Iceberg. Você pode usar esses dados para análises adicionais.
Conclusão
Nesta publicação, mostramos como criar uma solução escalável e Serverless para processar documentos PDF e exportar os dados extraídos para tabelas do S3 usando o Step Functions Distributed Map. Essa arquitetura oferece vários benefícios importantes, como confiabilidade, economia, visibilidade e facilidade de manutenção. Ao aproveitar os serviços da AWS, como Step Functions, Amazon Textract, Firehose e S3 Tables, as empresas podem automatizar seus fluxos de trabalho de processamento de documentos e, ao mesmo tempo, garantir o desempenho ideal e a excelência operacional. Essa solução pode ser adaptada para vários casos de uso além dos formulários de interesse do cliente, como processamento de faturas, formulários de inscrição ou qualquer cenário que exija extração estruturada de dados de documentos em grande escala.
Embora este exemplo se concentre no processamento de dados em PDF e na gravação em tabelas do S3, o Distributed Map pode lidar com várias fontes de entrada, incluindo arquivos JSON, JSONL, CSV e Parquet no Amazon S3; itens nas tabelas do Amazon DynamoDB; resultados de consultas do Athena; e todas as APIs paginadas da AWS List. Da mesma forma, por meio das integrações de serviços do Step Functions, você pode gravar resultados em vários destinos, como tabelas do DynamoDB, usando a integração do serviço PutItem.
Para começar a usar essa solução, consulte o repositório associado do GitHub para ver as instruções de implantação e o código de amostra.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Autores
 |
Chetan Makvana, Sr. Solutions Architect |
 |
Aidan Eglin, Software Development Manager |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |