O blog da AWS
Padrões Serverless de arquiteturas de IA generativos — Parte 2
Por Michael Hume, arquiteto de soluções sênio na Amazon Web Services e Parnab Basa, sênior product acelerator SA na Amazon Web Services.
Na Parte 1 desta série, discutimos três padrões e melhores práticas gerais para criar aplicativos de IA generativos, interativos e em tempo real. No entanto, nem todos os fluxos de trabalho generativos de IA exigem respostas imediatas. Esta publicação explora duas abordagens complementares para cenários que não são em tempo real: processamento assíncrono em buffer para solicitações individuais demoradas e processamento em lote para fluxos de trabalho programados ou orientados por eventos.
O processamento assíncrono em buffer é útil para casos de uso que exigem processamento demorado para produzir os resultados mais precisos. Consequentemente, eles se beneficiam de um ciclo interativo de resposta de solicitação atrasada que pode ser obtido por meio de uma integração assíncrona com buffer. Os exemplos incluem gerar vídeo ou música a partir de texto, conduzir análises e visualizações médicas ou científicas, criar mundos virtuais completos para jogos ou metaverso, geração de gráficos de moda e estilo de vida e muito mais.
A segunda abordagem aborda um desafio diferente: processar conjuntos de dados extensos em um cronograma ou quando eventos específicos ocorrem. Os exemplos incluem aprimoramento e otimização de imagens em massa, geração de relatórios semanal ou mensal, análise semanal de avaliações de clientes e criação de conteúdo de mídia social. Esses fluxos de trabalho de IA generativos não interativos e orientados por lotes exigem repetibilidade, escalabilidade, paralelismo e gerenciamento de dependências para gerenciar grandes volumes de dados. O lote não interativo implementa esse padrão de processamento.
Padrão 4: resposta de solicitação assíncrona armazenada em buffer
Esse padrão assíncrono usa arquiteturas orientadas por eventos para aprimorar a escalabilidade e a confiabilidade do aplicativo. Essa abordagem oferece várias vantagens, incluindo desempenho aprimorado por meio de processamento simultâneo, escalabilidade aprimorada por meio do processamento em grupo e melhor confiabilidade por meio de componentes desacoplados. Esse padrão é particularmente eficaz para lidar com solicitações de alto volume ou processos de longa execução.
A implementação normalmente envolve serviços de enfileiramento de mensagens, como o Amazon Simple Queue Service (Amazon SQS), para armazenar solicitações em buffer e gerenciar cargas de processamento. Esse padrão pode ser particularmente eficaz quando combinado com as APIs do WebSocket para atualizações interativas, aliviando a necessidade de pesquisas do lado do cliente. Para cenários complexos envolvendo vários modelos LLM, o padrão de distribuição multimodal (consulte o padrão 5 abaixo) usando o Amazon EventBridge ou o Amazon Simple Notification Service (Amazon SNS) permite o processamento paralelo em diferentes endpoints. Esse padrão pode ser implementado por meio de várias abordagens arquitetônicas.
APIs REST com enfileiramento de mensagens
Para limitar os desafios de escalabilidade com seu endpoint LLM, use uma fila do Amazon SQS para armazenar mensagens em buffer. O frontend envia mensagens para os endpoints REST do Amazon API Gateway, que as envia para a fila. O API Gateway retorna uma confirmação e um identificador exclusivo (o ID da mensagem) para o frontend. O middleware executado em serviços computacionais como AWS Lambda, Amazon EC2 ou AWS Fargate processa mensagens em lotes, criando entradas no Amazon DynamoDB para cada registro. Em seguida, ele chama os endpoints do LLM para gerar respostas, armazenando os resultados na tabela do DynamoDB com o ID da mensagem correspondente. O frontend consulta o endpoint do API Gateway para verificar se a mensagem de resposta foi gerada, consultando a tabela do DynamoDB usando o ID da mensagem. Esse padrão ajuda a superar o limite de 29 segundos do API Gateway para o ciclo de resposta da solicitação. Para ver um exemplo de implementação, consulte API Gateway REST API to SQS to Lambda to Bedrock. Uma solução semelhante pode ser implementada usando as APIs do AWS AppSync GraphQL em vez do Amazon API Gateway. O diagrama a seguir ilustra um exemplo de arquitetura.
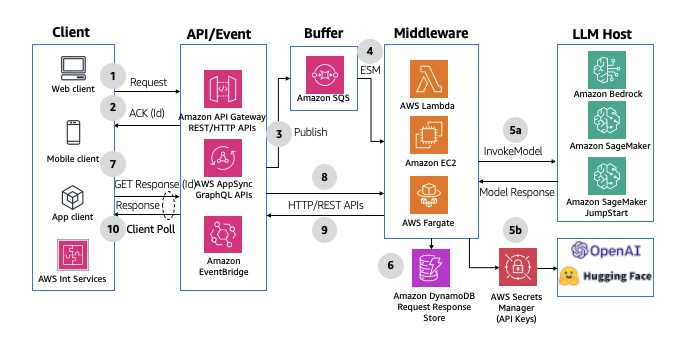
Figura 11: Resposta de solicitação assíncrona armazenada em buffer usando serviços de integração de API da Amazon e filas do Amazon SQS
APIs do WebSocket com enfileiramento de mensagens
Essa é uma variação do padrão anterior, mas usa APIs do API Gateway WebSocket em vez de endpoints REST. Nesse padrão, em vez de o cliente frontend precisar pesquisar continuamente a resposta, o middleware envia o resultado de volta ao cliente depois que ele é gerado. Isso usa a comunicação omnicanal do WebSocket para aceitar e responder às mensagens, todas mantidas pelo API Gateway. Para ver um exemplo de implementação, consulte o AWS Solutions Construct aws-apigatewayv2websocket-sqs. O diagrama a seguir ilustra essa arquitetura.
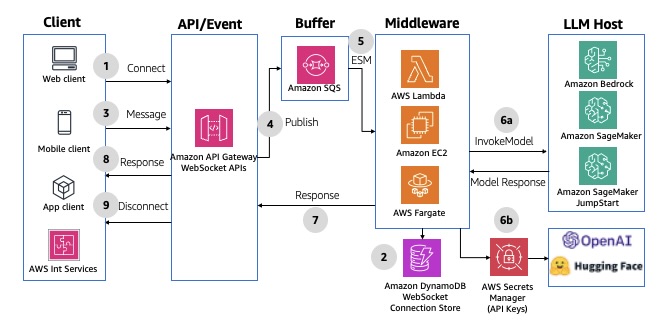
Figura 12: Resposta de solicitação assíncrona armazenada em buffer usando APIs do Amazon API Gateway, WebSocket e filas do Amazon SQS
Padrão 5: distribuição paralela multimodal
Para casos de uso que exigem interação com vários modelos, fontes de dados ou agentes de LLM, você pode usar o padrão de distribuição de mensagens, que distribui mensagens para vários destinos em paralelo. Você pode usar o Amazon EventBridge ou o Amazon SNS para enviar mensagens específicas para endpoints ou agentes do LLM de destino usando distribuição de mensagens com base em regras. Esse padrão decompõe tarefas complexas em subtarefas e as executa em paralelo, minimizando o tempo geral de geração. Para ver um exemplo de implementação, consulte Padrão de fanout de SNS para SQS. O diagrama a seguir ilustra a arquitetura.
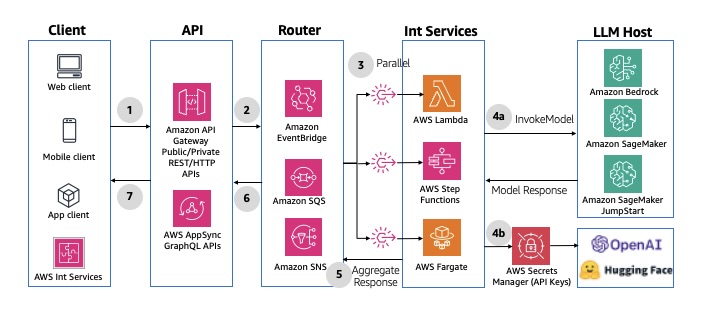
Figura 13: Distribuição paralela multimodal usando serviços de integração e mensagens de API da Amazon
Padrão 6: processamento em lote não interativo
Os pipelines de processamento em lote não interativos são ideais quando você precisa processar grandes volumes de dados com eficiência sem a interação do usuário em tempo real, normalmente sendo executados de forma programada para maximizar o uso e a taxa de transferência dos recursos. Esse padrão usa o AWS Step Functions, o AWS Glue ou outros serviços de computação para criar um pipeline de processamento e inferência de dados Serverless. Os trabalhos de integração, transformação e inferência de dados podem ser acionados com base em um cronograma ou na ocorrência de eventos. Esse padrão oferece maior rendimento, otimiza o uso de recursos e aprimora a automação por meio do processamento de volumes. Para ver um exemplo de implementação, consulte aws-sqs-pipes-stepfunctions AWS Solutions Construct. O diagrama a seguir ilustra um exemplo de arquitetura.
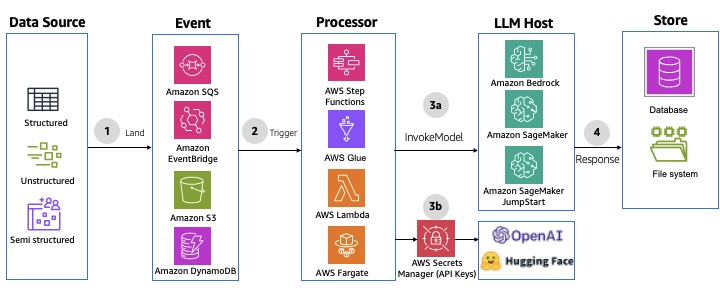
Figura 14: Processamento em lote não interativo usando os serviços de integração de dados da Amazon
Conclusão
Nesta publicação (série), você aprendeu seis padrões de arquitetura na criação de aplicativos generativos de IA usando os serviços Serverless da AWS. Esses padrões implementam cargas de trabalho interativas em tempo real, assíncronas ou orientadas por lotes sem muita sobrecarga operacional. Você pode combinar esses padrões para fornecer aplicativos nativos da nuvem modernos. Dada a trajetória atual de inovação nesse domínio, prevê-se que surjam novos planos para aumentá-los ou desenvolvê-los no futuro. A implantação bem-sucedida de aplicativos de IA generativa prontos para produção requer uma análise cuidadosa dos padrões de arquiteturas e das abordagens de implementação. Você deve avaliar vários fatores, como tempo de resposta, escalabilidade, necessidades de integração, confiabilidade e experiência do usuário, ao selecionar padrões apropriados ou uma combinação deles.
Para saber mais sobre arquiteturas sem servidor, consulte Serverless Land.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Autores
 |
Michael Hume é arquiteto de soluções sênio na Amazon Web Services |
 |
Parnab Basa é sênior product acelerator SA na Amazon Web Services |
Tradutores
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |