Comment a été ce contenu ?
- Apprendre
- Comment Amazon SageMaker permet à Widebot de fournir une analyse des sentiments en arabe
Comment Amazon SageMaker permet à Widebot de fournir une analyse des sentiments en arabe
Les start-ups savent qu'il est important de créer des expériences client de qualité. L'analyse des sentiments est un outil qui y contribue : elle classe les données comme positives, négatives ou neutres selon des techniques de machine learning, telles que l'analyse de texte et le traitement du langage naturel (NLP). Les entreprises ont recours à l'analyse des sentiments pour évaluer la satisfaction des clients à l'égard d'un produit ou d'un service cible.
L'analyse des sentiments s'avérer particulièrement complexe pour les utilisateurs finaux arabophones : les habitants de la région du Moyen-Orient et de l'Afrique du Nord (MENA) parlent plus de 20 dialectes de la langue arabe, l'arabe standard moderne étant la langue la plus courante.
Dans ce billet de blog, nous expliquons comment Widebot utilise Amazon Sagemaker pour implémenter avec succès d'un classificateur de sentiments. Widebot est l'une des principales plateformes de chatbot d'intelligence artificielle (IA) conversationnelle axées sur l'arabe dans la région MENA. Son classificateur de sentiments prend en charge l'arabe standard moderne, ainsi que l'arabe dialectal égyptien, avec une grande précision lorsqu'il est testé sur plusieurs jeux de données provenant de différents domaines.
Le modèle de Widebot peut être facilement ajusté après avoir ingéré quelques centaines d'échantillons provenant du nouveau domaine ou du nouveau jeu de données. Cela rend la solution générique et adaptable à différents domaines et cas d'utilisation.
Les caractéristiques d'un chatbot performant
Les chatbots représentent un outil utile pour gérer et améliorer l'expérience client, ainsi que pour automatiser les tâches afin que les employés puissent se concentrer sur les tâches essentielles à la mission de leur entreprise. Les start-ups, en particulier, connaissent l'intérêt d'utiliser des services gérés afin de pouvoir consacrer leur temps aux tâches qui comptent le plus pour leur réussite.
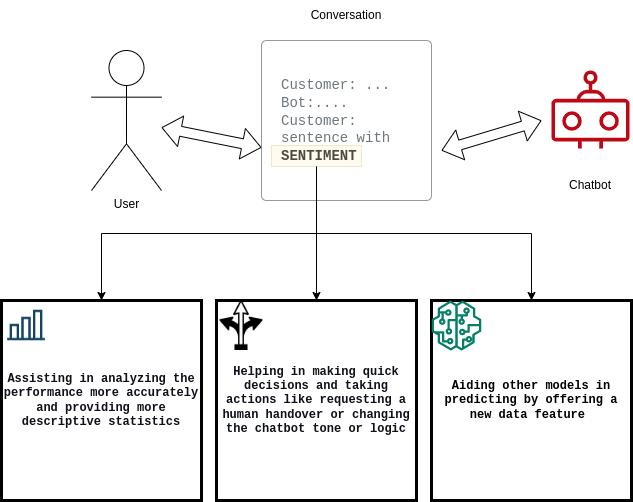
Il est important pour les chatbots de quantifier les clients satisfaits ou insatisfaits, ainsi que de documenter le taux de conversion entre satisfaits et insatisfaits (ou vice versa). Pour répondre à ces exigences, la solution de Widebot :
- aide les utilisateurs à analyser les performances de leur système de chatbot ;
- améliore la prise de décision du chatbot ;
- facilite d'autres modèles de machine learning (ML) en aval.
Défis techniques liés à l'élaboration d'une analyse des sentiments
Les scientifiques des données de Widebot innovent constamment pour améliorer et optimiser leurs modèles de deep learning afin de répondre aux attentes croissantes de leurs clients. Pour mieux servir leurs clients de chatbots arabes, ils ont travaillé au développement d'une nouvelle solution pour les modèles de deep learning destinés à l'analyse des sentiments en arabe.
Les défis étaient les suivants :
- Capacité de mise à l'échelle du modèle
- Temps de réponse
- Nombreuses demandes simultanées
- Coût de fonctionnement
Comme de nombreuses start-ups, l'entreprise a initialement déployé le modèle sur une infrastructure autogérée et des serveurs à usage général. Cependant, à mesure que la start-up se développait, elle n'a pas pu mettre à l'échelle efficacement le modèle pour prendre en charge l'augmentation des données et les pics de demandes simultanées.
Widebot a commencé à rechercher une solution qui l'aiderait à se concentrer sur la création rapide des modèles, sans consacrer trop de temps à la gestion et à la mise à l'échelle de l'infrastructure sous-jacente et des flux de travail des opérations de machine learning (MLOps).
Déploiement de modèles sur Amazon SageMaker
Widebot a choisi SageMaker, car la plateforme propose de nombreuses options de déploiement de modèles et d'infrastructure de ML pour répondre à tous ses besoins en inférence ML. SageMaker permet aux start-ups de déployer facilement des modèles de ML au meilleur prix.
« Par chance, nous avons découvert qu'Amazon SageMaker nous donne la pleine propriété et le contrôle tout au long du cycle de développement du modèle. Les outils simples et puissants de SageMaker nous permettent d'automatiser et de normaliser les pratiques MLOps afin de créer, d'entraîner, de déployer et de gérer des modèles plus facilement et plus rapidement qu'avec notre infrastructure autogérée », a déclaré Mohamed Mostafa, cofondateur et Chief Technology Officer (CTO) de Widebot.
L'équipe de Widebot peut désormais se concentrer sur la création et l'amélioration de ses modèles de ML pour répondre aux attentes de ses clients, tandis que SageMaker s'occupe de la configuration et de la gestion des instances, des compatibilités des versions logicielles et de l'application de correctifs aux versions. SageMaker fournit également des métriques et des journaux intégrés pour les points de terminaison, afin de continuer à surveiller l'état et les performances du modèle.
Amazon SageMaker Inference Recommender a aidé Widebot à choisir la meilleure instance de calcul et la meilleure configuration pour déployer ses modèles de ML afin d'optimiser les performances et les coûts d'inférence. SageMaker Inference Recommender sélectionne automatiquement le type d'instance de calcul, le nombre d'instances, les paramètres du conteneur et les optimisations du modèle à des fins d'inférence afin d'optimiser les performances et de minimiser les coûts.
Widebot utilise également divers services AWS pour créer son architecture, notamment Amazon Simple Storage Service (Amazon S3), AWS Lambda, Amazon API Gateway et Amazon Elastic Container Registry (ECR) :
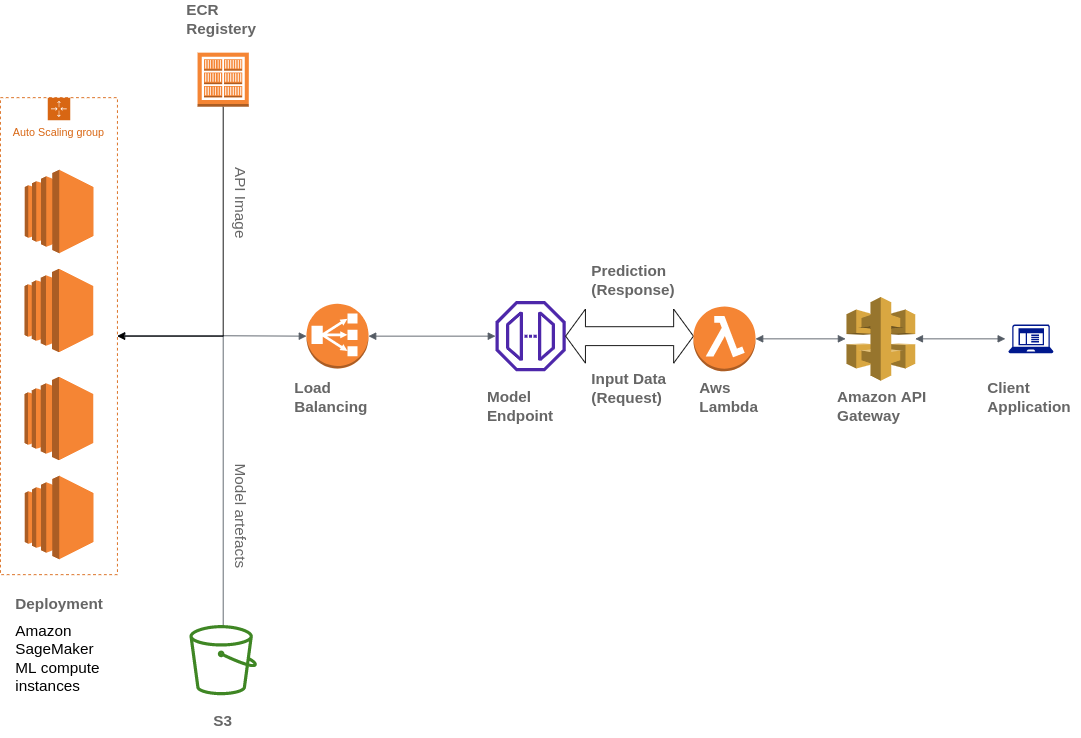
Widebot souhaitait une solution lui permettant de publier en toute sécurité les modèles de ML qu'elle a développés pour ses clients en tant que point de terminaison d'API. Elle a utilisé API Gateway, un service entièrement géré, pour publier, gérer, surveiller et sécuriser les points de terminaison d'API des modèles ML déployés sur SageMaker. API Gateway est un point d'entrée unique externe pour les points de terminaison SageMaker et permet aux clients d'y accéder facilement et en toute sécurité.
Les clients interagissent avec le point de terminaison d'inférence SageMaker en envoyant une demande d'API au point de terminaison API Gateway. L'API Gateway mappe les demandes du client au point de terminaison d'inférence SageMaker correspondant et invoque le point de terminaison pour obtenir une inférence à partir du modèle. L'API Gateway reçoit ensuite la réponse du point de terminaison SageMaker et la mappe à nouveau, dans une réponse envoyée au client.
Présentation de la solution
Comment Widebot a-t-elle développé une nouvelle solution efficace pour les modèles de deep learning destinés à l'analyse des sentiments en arabe ? Voici les étapes suivies :
Collecte et préparation de jeux de données
Collecte de dizaines de milliers d'échantillons de données provenant de différentes sources de données (publiques et internes).
Examen attentif des jeux de données, étiquetage des données et amélioration de la qualité des données par la suppression des échantillons non pertinents.
L'équipe chargée des données réalise un processus d'annotation en utilisant Amazon SageMaker Ground Truth pour annoter suffisamment d'échantillons provenant de différents domaines et styles d'écriture afin d'enrichir le jeu de données utilisé.
Envoi des échantillons par le biais du pipeline de prétraitement, avant l'entraînement du modèle à l'aide du deep learning pour classer le texte d'entrée dans les catégories positif, négatif ou neutre, et en lui attribuant une probabilité.
Création et entraînement du modèle
Utilisation d'un modèle de réseau neuronal convolutif (CNN, Convolutional Neural Network) entraîné à l'aide de Keras et de TensorFlow.
Exécution de nombreuses itérations dans le but de tester différents pipelines, architectures et générateurs de jetons de prétraitement, jusqu'à obtenir l'architecture qui donne les meilleurs résultats sur différents échantillons de jeux de données et provenant de différents domaines.
Utilisation d'un pipeline de prétraitement natif développé en interne pour supprimer les informations inutiles du texte : dates, URL, mentions, adresses e-mail, ponctuation (sauf pour « ! ? ») et chiffres.
Application des étapes de normalisation du texte en arabe, telles que la suppression des signes diacritiques et la normalisation de certaines lettres que les utilisateurs utilisent de manière interchangeable, comme (ء أ ئ ؤ إ), yaa (ي ى) ou d'autres caractères.
Application d'une légère troncature au texte afin de supprimer certains suffixes et préfixes et de réduire certains mots à leur racine (par exemple, (التعيينات) réduit en (تعيين)).
Enregistrement du modèle, du préprocesseur, des hyperparamètres et des générateurs de jeton à l'aide de la sérialisation et exportation sous forme de fichiers .h5 et .pickle.
Déploiement du modèle sur Amazon SageMaker
Intégration du modèle dans une API, qui constitue le point de terminaison de la prédiction. Ce point de terminaison accepte les entrées JSON de l'utilisateur final et transforme les données en une structure de données simplifiée, les nettoie et renvoie les résultats des données d'entrée en matière de sentiments.
Création d'une image Docker contenant le code, toutes les dépendances et les instructions nécessaires pour créer et exécuter les composants dans n'importe quel environnement.
Chargement des artefacts du modèle dans un compartiment Amazon S3 et de l'image Docker dans Amazon ECR.
Déploiement du modèle à l'aide de SageMaker, en sélectionnant l'emplacement de l'image dans Amazon ECR et l'URI des artefacts dans le compartiment Amazon S3.
Création d'un point de terminaison à l'aide de SageMaker et utilisation d'API Gateway pour publier le point de terminaison auprès des clients.
Type et volume de données
Dans le cadre de l'élaboration du modèle, les données de Widebot se composent d'environ 100 000 messages différents pour l'entraînement et de 20 000 messages pour la validation et les tests. Les messages :
- provenaient de différents secteurs, tels que l'e-commerce, l'alimentation et les boissons et les services financiers ;
- comprenaient des avis concernant différents services ou produits (par exemple, des avis sur des hôtels, des réservations, des restaurants et des entreprises) ;
- variaient au niveau du ton, allant d'un langage très formel à l'utilisation de mots extrêmement grossiers ;
- étaient écrits en dialecte égyptien et en arabe standard moderne ;
- étaient classés dans l'une des trois catégories suivantes : négatif, neutre ou positif.
Le tableau suivant présente des exemples de messages :
| Exemple | Sentiment | Fiabilité |
| الخدمة لديكم مناسبة « Vous offrez un bon service. » | positif | 0,8471 |
| شكرا لحسن تعاونكم « Merci pour votre coopération. » | positif | 0,9688 |
| الخدمة والتعامل لديكم دون المستوى « Vous offrez un service médiocre. » | négatif | 0,8982 |
| حالة الجو سيئة جدا « La météo est très mauvaise. » | négatif | 0,9737 |
| سأعاود الإتصال بكم وقت لاحق « Je vous contacterai plus tard. » | neutre | 0,8255 |
| أريد الإستعلام عن الخدمات « Je souhaite me renseigner sur les services. » | neutre | 0,9728 |
Résumé des résultats
Widebot a testé son modèle par rapport à différents jeux de données de textes en arabe, dans différents dialectes. Ces métriques ont été mesurées à l'aide de jeux de données contenant des milliers d'échantillons. Le score F1 est utilisé pour mesurer la précision du modèle avec les différents jeux de données. Les moyennes macro et pondérées du score F1 sont utilisées pour évaluer la précision et les performances globales.
Précision du modèle
Jeu de données de test (20 679 échantillons dans le ratio 5 004:1 783:13 892)
| F1 négatif | F1 neutre | F1 positif | Précision globale | Moyenne macro | Moyenne pondérée |
| 89,9 | 79,4 | 95,1 | 92,5 | 88,1 | 92,5 |
Temps de réponse du modèle
Widebot a évalué le temps de réponse en utilisant les secondes moyennes (AVG), minimales (MIN) et maximales (MAX) par réponse (s/réponse) :
- AVG : 0,106 s/réponse
- MIN : 0,088 s/réponse
- MAX : 0,957 s/réponse
Les éléments suivants comparent la métrique du temps de réponse entre l'utilisation d'une plateforme de calcul à usage général et l'utilisation d'Amazon SageMaker pour l'hébergement de modèles, lors du déploiement des mêmes jeux de données avec une taille de charge utile moyenne de 2 Ko.
| Temps de réponse total | Temps de réponse total Plateforme de calcul générale (instances EC2 : p2.xlarge) | Amazon SageMaker (instances SageMaker : ml.m4.xlarge) |
| Moyenne | 0,202 s/réponse | 0,106 s/réponse |
| Minimum | 0,097 s/réponse | 0,088 s/réponse |
| Maximum | 8,458 s/réponse | 0,957 s/réponse |
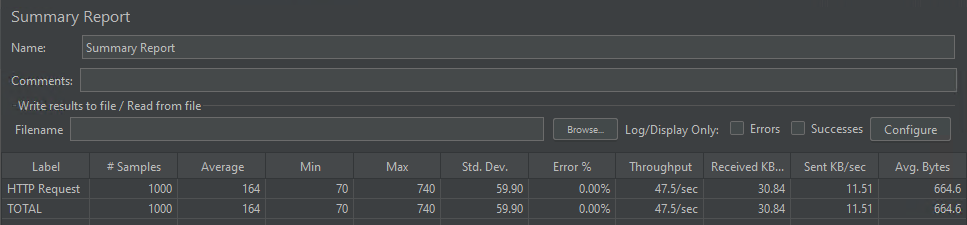
Simultanéité du modèle
Le modèle a pu traiter 1 000 demandes simultanées délivrées en moyenne en 164 millisecondes.
Conclusion
Ce billet montre comment les services AWS ont aidé Widebot à créer une solution complète pour extraire les sentiments du texte de chat dans différents dialectes arabes, à l'aide d'un modèle de deep learning hébergé sur SageMaker.
SageMaker a aidé Widebot à innover plus rapidement et à déployer son classificateur de sentiments afin de résoudre un problème complexe du ML : l'extraction de sentiments à partir de discussions en arabe et leur publication en tant que point de terminaison RESTful public auquel les clients peuvent accéder facilement et en toute sécurité via l'API Gateway.
Cette démarche peut être utile pour de nombreux cas d'utilisation similaires, dans lesquels les clients souhaitent créer, entraîner et déployer leur modèle de ML sur SageMaker, puis publier le point de terminaison d'inférence du modèle pour leurs clients de manière simple mais sécurisée, à l'aide d'API Gateway.
Si vous souhaitez en matière de diversité linguistique et de méthodes d'affinage des modèles de langage préentraînés basés sur des transformateurs sur Amazon SageMaker, vous pouvez lire ce billet de blog.

Mohamed Mostafa
Mohamed Mostafa est co-fondateur et directeur technique de WideBot. Il est passionné par l'application des pratiques d'ingénierie modernes et le développement de logiciels de haute qualité dont le but est d’améliorer l'expérience des utilisateurs.

Ahmed Azzam
Ahmed Azzam est un architecte de solutions senior basé à Dubaï, aux Émirats arabes unis. Sa passion c’est d'aider les startups non seulement à concevoir et à développer des applications évolutives, mais aussi à réfléchir à des solutions innovantes utilisant les services AWS.
Comment a été ce contenu ?