Come ti è sembrato il contenuto?
- Scopri
- In che modo Amazon SageMaker aiuta Widebot a migliorare l'analisi del sentiment in arabo
In che modo Amazon SageMaker aiuta Widebot a migliorare l'analisi del sentiment in arabo
Le startup sanno quanto è importante creare ottime esperienze per i clienti. L'analisi del sentiment è uno strumento che aiuta in questo senso: classifica i dati come positivi, negativi o neutri in base a tecniche di machine learning come l'analisi del testo e l'elaborazione del linguaggio naturale. Le aziende utilizzano l'analisi del sentiment per misurare la soddisfazione dei clienti per un prodotto o servizio target.
L'analisi del sentiment è particolarmente difficile da condurre sugli utenti finali arabi: gli abitanti della regione del Medio Oriente e del Nord Africa (MENA) parlano più di 20 dialetti della lingua araba e l'arabo standard moderno è la lingua più comune.
In questo post del blog, spieghiamo come Widebot utilizza Amazon SageMaker per implementare con successo un classificatore del sentiment. Widebot è una delle principali piattaforme di chatbot di intelligenza artificiale (IA) conversazionale focalizzate sull'arabo nella regione MENA. Il suo classificatore del sentiment supporta l'arabo standard moderno e il dialetto egiziano; testato su più set di dati provenienti da domini diversi, ha dimostrato una precisione elevata.
Il modello di Widebot può essere facilmente ottimizzato dopo aver ricevuto alcune centinaia di campioni dal nuovo dominio o set di dati. Ciò rende la soluzione generica e adattabile a diversi domini e casi d'uso.
Le caratteristiche di un chatbot di successo
I chatbot sono uno strumento utile sia per gestire e migliorare l'esperienza dei clienti, sia per automatizzare le attività, in modo che i dipendenti possano concentrarsi sui compiti fondamentali per la missione dell'azienda. Le startup, in particolare, conoscono il valore dell'utilizzo di servizi gestiti per avere più tempo da dedicare alle attività determinanti per il loro successo.
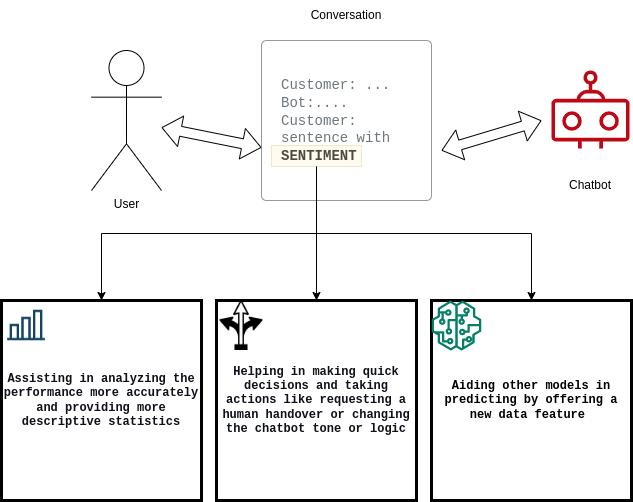
È importante che i chatbot quantifichino i clienti soddisfatti o insoddisfatti e documentino il tasso di conversione da una categoria all'altra. Per soddisfare questi requisiti, la soluzione di Widebot:
- Aiuta gli utenti ad analizzare le prestazioni del proprio sistema di chatbot
- Migliora il processo decisionale del chatbot
- Supporta altri modelli di machine learning (ML) a valle
Sfide tecniche legate alla creazione dell'analisi del sentiment
I data scientist di Widebot innovano continuamente per migliorare e ottimizzare i propri modelli di deep learning e stare al passo con le crescenti aspettative dei clienti. Per servire meglio i clienti di chatbot in arabo, hanno sviluppato una nuova soluzione per i modelli di deep learning di analisi del sentiment in arabo.
Le sfide di questa iniziativa includevano:
- Scalabilità del modello
- Tempi di risposta
- Numero elevato di richieste simultanee
- Costo di esecuzione
Come molte altre startup, inizialmente l'azienda ha implementato il modello su infrastrutture autogestite e server generici. Tuttavia, man mano che cresceva, la startup non riusciva a dimensionare il modello in modo efficiente per far fronte all'incremento dei dati e ai picchi di richieste simultanee.
Widebot ha iniziato a cercare una soluzione che la aiutasse a concentrarsi sulla creazione rapida di modelli, senza richiedere troppo tempo per la gestione e il dimensionamento dell'infrastruttura sottostante e dei flussi di lavoro delle operazioni di machine learning (MLOps).
Implementazione dei modelli su Amazon SageMaker
Widebot ha scelto SageMaker perché offre un'ampia selezione di infrastrutture di ML e opzioni di implementazione dei modelli che soddisfa tutte le sue esigenze di inferenza ML. SageMaker consente alle startup di implementare facilmente modelli di ML al miglior rapporto prezzo/prestazioni.
"Fortunatamente, abbiamo scoperto che Amazon SageMaker ci offre la piena proprietà e il controllo completo durante tutto il ciclo di vita dello sviluppo del modello. Gli strumenti semplici e potenti di SageMaker ci consentono di automatizzare e standardizzare le pratiche MLOps: così riusciamo a creare, addestrare, implementare e gestire i modelli in modo più semplice e rapido di quanto permettesse la nostra infrastruttura autogestita", ha dichiarato Mohamed Mostafa, co-fondatore e Chief Technology Officer (CTO) di Widebot.
Il team di Widebot è ora in grado di concentrarsi sulla creazione e sul miglioramento dei propri modelli di ML per soddisfare le aspettative dei clienti, mentre SageMaker si occupa della configurazione e della gestione delle istanze, della compatibilità delle versioni del software e dell'applicazione di patch alle versioni. SageMaker fornisce anche parametri e log integrati per gli endpoint per continuare a monitorare lo stato e le prestazioni dei modelli.
Inferenza con funzione di suggerimento Amazon SageMaker ha aiutato Widebot a scegliere l'istanza e la configurazione di calcolo migliori per implementare i modelli di ML assicurandosi prestazioni e costi di inferenza ottimali. Inferenza con funzione di suggerimento SageMaker seleziona automaticamente il tipo di istanza di calcolo, il numero di istanze, i parametri del container e le ottimizzazioni del modello per l'inferenza per massimizzare le prestazioni e ridurre al minimo i costi.
Inoltre, Widebot ha utilizzato vari servizi AWS per creare la propria architettura, tra cui Amazon Simple Storage Service (Amazon S3), AWS Lambda, Gateway Amazon API e Amazon Elastic Container Registry (ECR):
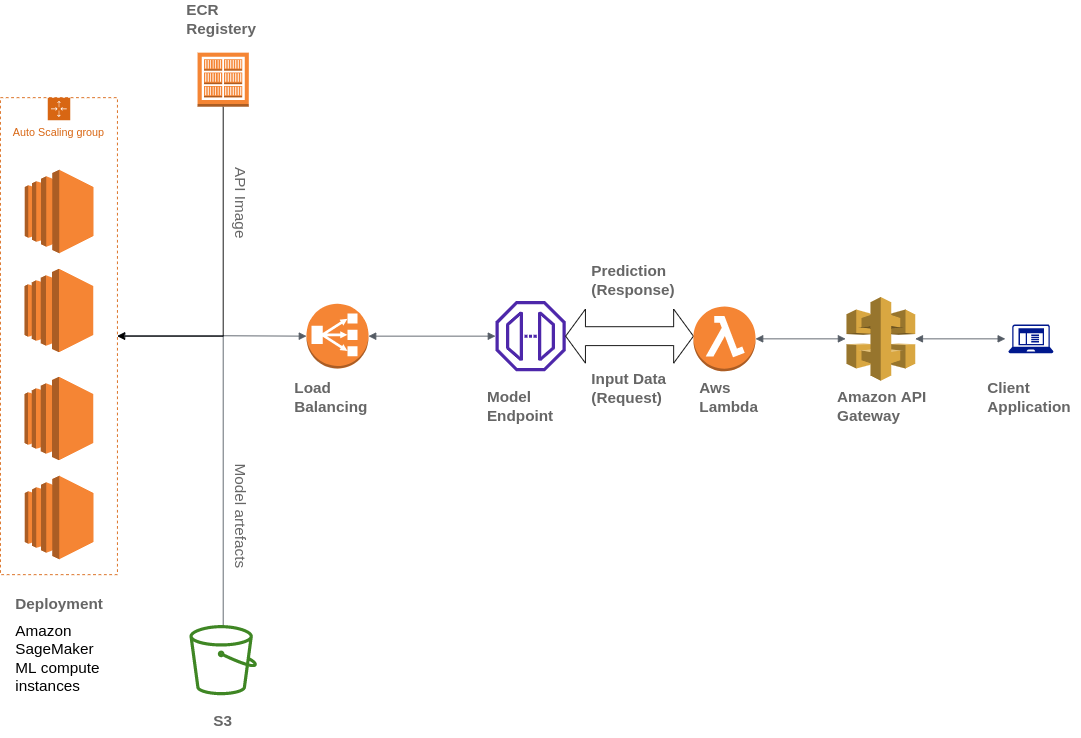
Widebot stava cercando una soluzione per pubblicare in modo sicuro i modelli di ML sviluppati per i suoi clienti come endpoint API. Ha utilizzato Gateway API, un servizio completamente gestito, per pubblicare, mantenere, monitorare e proteggere gli endpoint API dei modelli di ML implementati su SageMaker. Gateway API viene utilizzato come singolo punto di ingresso rivolto all'esterno per gli endpoint SageMaker, rendendoli accessibili in modo facile e sicuro dai client.
I client interagiscono con l'endpoint di inferenza SageMaker inviando una richiesta API all'endpoint Gateway API. Gateway API mappa le richieste del client all'endpoint di inferenza SageMaker corrispondente e richiama l'endpoint per ottenere un'inferenza dal modello. Successivamente, Gateway API riceve la risposta dall'endpoint SageMaker e la mappa a ritroso nella risposta che invia al client.
Panoramica della soluzione
In che modo Widebot ha creato una nuova soluzione di successo per i modelli di deep learning di analisi del sentiment in arabo? Ecco i passaggi che ha seguito:
Raccolta e preparazione dei set di dati
Vengono raccolte decine di migliaia di campioni di dati da diverse origini dati pubbliche e interne.
I set di dati vengono esaminati attentamente ed etichettati, e la qualità viene migliorata rimuovendo i campioni irrilevanti.
Il team addetto ai dati esegue un processo di annotazione utilizzando Amazon SageMaker Ground Truth per annotare un numero sufficiente di campioni provenienti da domini e stili di scrittura diversi al fine di arricchire il set di dati utilizzato.
I campioni vengono inseriti nella pipeline di pre-elaborazione, dopodiché il modello viene addestrato utilizzando il deep learning per classificare il testo di input come positivo, negativo o neutro e la rispettiva probabilità.
Costruzione e addestramento del modello
L'azienda utilizza un modello di rete neurale convoluzionale (CNN) addestrato con Keras e TensorFlow.
Esegue molte iterazioni per testare una varietà di pipeline, architetture e tokenizzatori di pre-elaborazione, fino a raggiungere l'architettura che produce i risultati migliori su diversi set di dati di esempio e provenienti da domini diversi.
Utilizza una pipeline di pre-elaborazione nativa sviluppata internamente per rimuovere le informazioni non necessarie dal testo, come date, URL, menzioni, indirizzi e-mail, punteggiatura (tranne '!' e '?') e numeri.
Applica i passaggi di normalizzazione del testo arabo, eliminando, ad esempio, i segni diacritici e normalizzando alcune lettere che gli utenti utilizzano in modo intercambiabile, come (ء أ ئ ؤ إ), yaa (ي ى) o altri caratteri.
Conduce sul testo uno stemming leggero, che rimuove alcuni suffissi e prefissi e riduce alcune parole derivate alla loro radice; ad esempio, (التعيينات) viene ridotto a (تعيين).
Salva il modello, il pre-elaboratore, gli iperparametri e i tokenizzatori utilizzando la serializzazione e li esporta come file con estensione .h5 e .pickle.
Implementazione del modello su Amazon SageMaker
Il modello viene integrato in un'API, l'endpoint di previsione. Tale endpoint accetta l'input in JSON dell'utente finale e trasforma i dati in una struttura più semplice, li pulisce e restituisce i risultati del sentiment dei dati di input.
Viene creata un'immagine Docker che contiene il codice, tutte le dipendenze e le istruzioni necessarie per creare ed eseguire i componenti in qualsiasi ambiente.
Gli artefatti del modello vengono caricati su un bucket Amazon S3 e l'immagine Docker su Amazon ECR.
Il modello viene implementato utilizzando SageMaker, selezionando la posizione dell'immagine in Amazon ECR e l'URI degli artefatti nel bucket Amazon S3.
Viene creato un endpoint utilizzando SageMaker e Gateway API viene utilizzato per pubblicare l'endpoint per i clienti.
Tipo e volume di dati
I dati che Widebot ha utilizzato per costruire il modello sono costituiti da circa 100.000 messaggi diversi per l'addestramento e da 20.000 messaggi per la convalida e il test. I messaggi:
- Provengono da settori diversi, come l'e-commerce, il settore alimentare e delle bevande e i servizi finanziari.
- Includono recensioni di servizi o prodotti diversi, ad esempio recensioni di hotel, di prenotazioni, di ristoranti e di aziende.
- Presentano registri diversi, da un linguaggio molto formale all'estremo opposto, colloquiale e con largo uso di parole volgari.
- Sono stati scritti sia in dialetto egiziano sia in arabo standard moderno.
- Sono stati classificati in una delle tre classi: negativo, neutro o positivo.
La tabella seguente mostra dei messaggi di esempio:
| Esempio | Sentiment | Affidabilità |
| الخدمة لديكم مناسبة "Il servizio è buono" | positivo | 0,8471 |
| شكرا لحسن تعاونكم "Grazie per la collaborazione" | positivo | 0,9688 |
| الخدمة والتعامل لديكم دون المستوى "Il servizio è scadente" | negativo | 0,8982 |
| حالة الجو سيئة جدا "Il tempo è pessimo" | negativo | 0,9737 |
| سأعاود الإتصال بكم وقت لاحق "La ricontatterò più tardi" | neutro | 0,8255 |
| أريد الإستعلام عن الخدمات "Voglio chiedere alcune informazioni sui servizi" | neutro | 0,9728 |
Riepilogo dei risultati
Widebot ha testato il proprio modello rispetto a diversi set di dati di testo arabo in vari dialetti. Questi parametri sono stati misurati utilizzando set di dati con migliaia di campioni. Il punteggio F1 viene utilizzato per misurare la precisione del modello rispetto ai diversi set di dati. Le medie aggregate e ponderate del punteggio F1 vengono utilizzate per misurare la precisione e le prestazioni complessive.
La precisione del modello
Il set di dati di test (20.679 campioni nel rapporto 5.004:1.783:13.892)
| F1 negativo | F1 neutro | F1 positivo | Precisione complessiva | Media aggregata | Media ponderata |
| 89,9 | 79,4 | 95,1 | 92,5 | 88,1 | 92,5 |
Il tempo di risposta del modello
Widebot ha misurato il tempo di risposta utilizzando la media (AVG), il minimo (MIN) e il massimo (MAX) di secondi per risposta (secondi/risposta):
- AVG: 0,106 secondi/risposta
- MIN: 0,088 secondi/risposta
- MAX: 0,957 secondi/risposta
Quanto segue confronta il parametro del tempo di risposta tra l'utilizzo di una piattaforma di calcolo per uso generico e l'utilizzo di Amazon SageMaker per l'hosting di modelli a parità di set di dati implementati, con una dimensione media del payload di 2 KB.
| Tempo di risposta totale | Tempo di risposta totalePiattaforma di calcolo per uso generico (istanze EC2: p2.xlarge) | Amazon SageMaker (istanze SageMaker: ml.m4.xlarge) |
| Media | 0,202 secondi/risposta | 0,106 secondi/risposta |
| Minimo | 0,097 secondi/risposta | 0,088 secondi/risposta |
| Massimo | 8,458 secondi/risposta | 0,957 secondi/risposta |
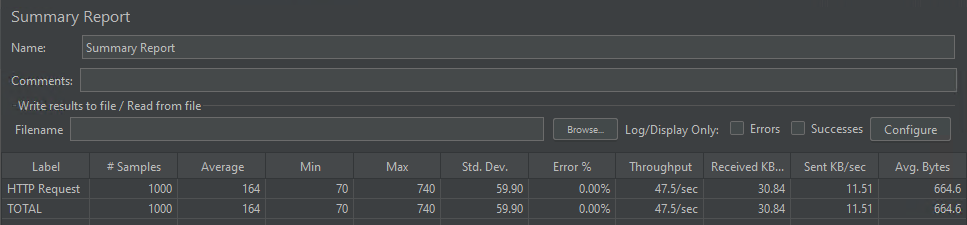
La simultaneità dei modelli
Il modello è stato in grado di gestire 1.000 richieste simultanee servite in media in 164 millisecondi.
Conclusioni
Questo post spiega come i servizi AWS hanno aiutato Widebot a creare una soluzione completa per ricavare i sentiment dai testi delle chat in diversi dialetti arabi utilizzando un modello di deep learning ospitato su SageMaker.
SageMaker ha aiutato Widebot a innovare più rapidamente e a implementare il proprio classificatore del sentiment per risolvere un complesso problema di ML, l'estrazione del sentiment dai testi conversazionali in arabo, e a pubblicarlo come endpoint RESTful pubblico a cui i clienti possono accedere in modo semplice e sicuro tramite Gateway API.
Questo approccio potrebbe essere utile per molti casi d'uso simili, in cui i clienti desiderano creare, addestrare e implementare il proprio modello di ML su SageMaker e successivamente pubblicare l'endpoint di inferenza del modello per i loro clienti in modo semplice ma sicuro utilizzando Gateway API.
Se ti interessa saperne di più sulla diversità linguistica e su come ottimizzare modelli linguistici pre-addestrati basati su trasformatori su Amazon SageMaker, puoi leggere questo post del blog.

Mohamed Mostafa
Mohamed Mostafa è co-fondatore e CTO di WideBot. Nutre una forte passione nell'applicare moderne pratiche ingegneristiche e nello sviluppare software di alta qualità al fine di migliorare l'esperienza degli utenti.

Ahmed Azzam
Ahmed Azzam è Senior Solutions Architect e risiede a Dubai. Assiste con passione e dedizione le startup nel progettare e sviluppare applicazioni scalabili, e le incoraggia a pensare in modo innovativo per creare soluzioni di grande impatto, avvalendosi dei servizi AWS.
Come ti è sembrato il contenuto?