Wie war dieser Inhalt?
- Lernen
- Wie Amazon SageMaker Widebot hilft, arabische Stimmungsanalysen zu erstellen
Wie Amazon SageMaker Widebot hilft, arabische Stimmungsanalysen zu erstellen
Startups wissen, wie wichtig es ist, großartige Kundenerlebnisse zu schaffen. Die Stimmungsanalyse ist ein Tool, das dabei hilft. Es kategorisiert Daten auf der Grundlage von Techniken des Machine Learning wie Textanalyse und natürlicher Sprachverarbeitung (NLP) als positiv, negativ oder neutral. Unternehmen verwenden Stimmungsanalysen, um die Zufriedenheit der Kunden mit einem Zielprodukt oder -Service zu messen.
Stimmungsanalysen können für arabische Endnutzer besonders schwierig sein: Menschen in der MENA-Region (Naher Osten und Nordafrika) sprechen mehr als 20 Dialekte der arabischen Sprache, wobei modernes Hocharabisch die gängigste Sprache ist.
In diesem Blogbeitrag erklären wir, wie Widebot Amazon Sagemaker verwendet, um erfolgreich einen Stimmungsklassifikator zu implementieren. Widebot ist eine der führenden Chatbot-Plattformen für Konversation mit künstlicher Intelligenz (KI) in der MENA-Region mit Fokus auf Arabisch. Ihr Stimmungsklassifikator unterstützt modernes Hocharabisch sowie Arabisch im ägyptischen Dialekt mit hoher Genauigkeit, wenn er an mehreren Datensätzen aus verschiedenen Domains getestet wird.
Das Modell von Widebot kann leicht angepasst werden, nachdem einige hundert Proben aus der neuen Domain oder dem neuen Datensatz erhalten wurden. Das macht die Lösung generisch und an verschiedene Domains und Anwendungsfälle anpassbar.
Die Eigenschaften eines erfolgreichen Chatbots
Chatbots sind ein nützliches Werkzeug für die Verwaltung und Verbesserung von Kundenerlebnissen, sowie für die Automatisierung von Aufgaben, sodass sich die Mitarbeiter auf die für ihr Unternehmen wichtigen Aufgaben konzentrieren können. Vor allem Startups kennen den Wert der Nutzung von verwalteten Services, damit sie ihre Zeit für die Aufgaben verwenden können, die für ihren Erfolg am wichtigsten sind.
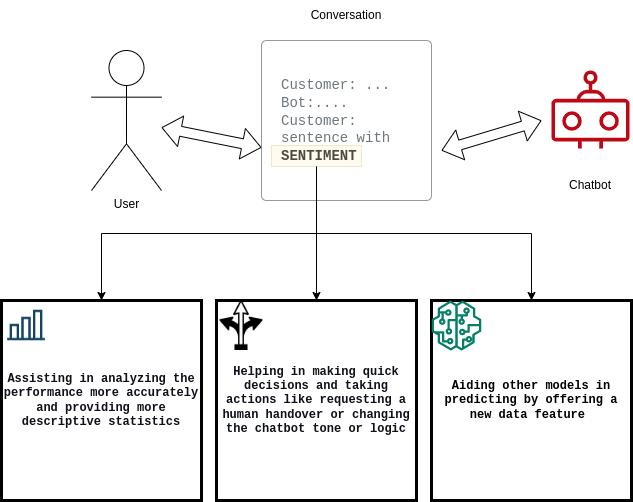
Für Chatbots ist es wichtig, zufriedene oder unzufriedene Kunden zu quantifizieren und die Konversionsrate von zufriedenen zu unzufriedenen Kunden (oder umgekehrt) zu dokumentieren. Um diese Anforderungen zu erfüllen, kann die Lösung von Widebot:
- Benutzern helfen, die Leistung ihres Chatbot-Systems zu analysieren
- Die Entscheidungsfindung des Chatbots verbessern
- Andere Downstream-Modelle für Machine Learning (ML) unterstützen
Technische Herausforderungen bei der Erstellung von Stimmungsanalysen
Widebot-Datenwissenschaftler arbeiten ständig an Innovationen, die ihre Deep-Learning-Modelle verbessern und optimieren, um mit den wachsenden Erwartungen ihrer Kunden Schritt zu halten. Um ihre arabischen Chatbot-Kunden besser bedienen zu können, arbeiteten sie an der Entwicklung einer neuen Lösung für Deep-Learning-Modelle zur arabischen Stimmungsanalyse.
Zu den Herausforderungen, die sich daraus ergeben, gehörten:
- Skalierbarkeit des Modells
- Reaktionszeit
- Massive Parallelitätsanfragen
- Die laufenden Kosten
Wie bei vielen Startups wurde das Modell zunächst auf einer selbstverwalteten Infrastruktur und auf Allzweckservern eingesetzt. Mit dem Wachstum ihres Startups konnten sie das Modell jedoch nicht effizient skalieren, um den wachsenden Datenmengen und Spitzen bei gleichzeitigen Anfragen Rechnung zu tragen.
Widebot begann mit der Suche nach einer Lösung, mit der sie sich auf die schnelle Erstellung der Modelle konzentrieren konnten, ohne übermäßig viel Zeit für die Verwaltung und Skalierung der zugrunde liegenden Infrastruktur und der Workflows für Machine-Learning-Vorgänge (MLOps) aufzuwenden.
Modellbereitstellung in Amazon SageMaker
Widebot entschied sich für SageMaker, weil es eine breite Auswahl an ML-Infrastruktur- und Modellbereitstellungsoptionen bietet, um alle Anforderungen an ML-Inferenz zu erfüllen. SageMaker macht es Startups leicht, ML-Modelle zum besten Preis-Leistungs-Verhältnis bereitzustellen.
„Glücklicherweise haben wir festgestellt, dass Amazon SageMaker uns die volle Verantwortung und Kontrolle über den gesamten Lebenszyklus der Modellentwicklung gibt. Die einfachen und leistungsstarken Tools von SageMaker ermöglichen es uns, die MLOps-Praxis zu automatisieren und zu standardisieren, um Modelle einfacher und schneller zu erstellen, zu trainieren, bereitzustellen und zu verwalten, als dies mit unserer selbstverwalteten Infrastruktur möglich war“ sagt Mohamed Mostafa, Mitbegründer und Chief Technology Officer (CTO) von Widebot.
Das Widebot-Team kann sich nun auf die Entwicklung und Verbesserung seiner ML-Modelle konzentrieren, um die Erwartungen seiner Kunden zu erfüllen, während SageMaker sich um die Einrichtung und Verwaltung von Instances, Softwareversionskompatibilitäten und das Patchen von Versionen kümmert. SageMaker bietet auch integrierte Metriken und Protokolle für Endpunkte, um den Zustand und die Leistung des Modells kontinuierlich zu überwachen.
Amazon SageMaker Inference Recommender half Widebot bei der Auswahl der besten Datenverarbeitungs-Instance und Konfiguration für die Bereitstellung seiner ML-Modelle für optimale Inferenzleistung und Kosten. SageMaker Inference Recommender wählt automatisch den Typ der Datenverarbeitungs-Instance, die Anzahl der Instances, die Container-Parameter und die Modelloptimierungen für Inferenz aus, um die Leistung zu maximieren und die Kosten zu minimieren.
Widebot verwendet auch verschiedene AWS-Services, um seine Architektur aufzubauen, darunter Amazon Simple Storage Service (Amazon S3), AWS Lambda, Amazon API Gateway und Amazon Elastic Container Registry(ECR):
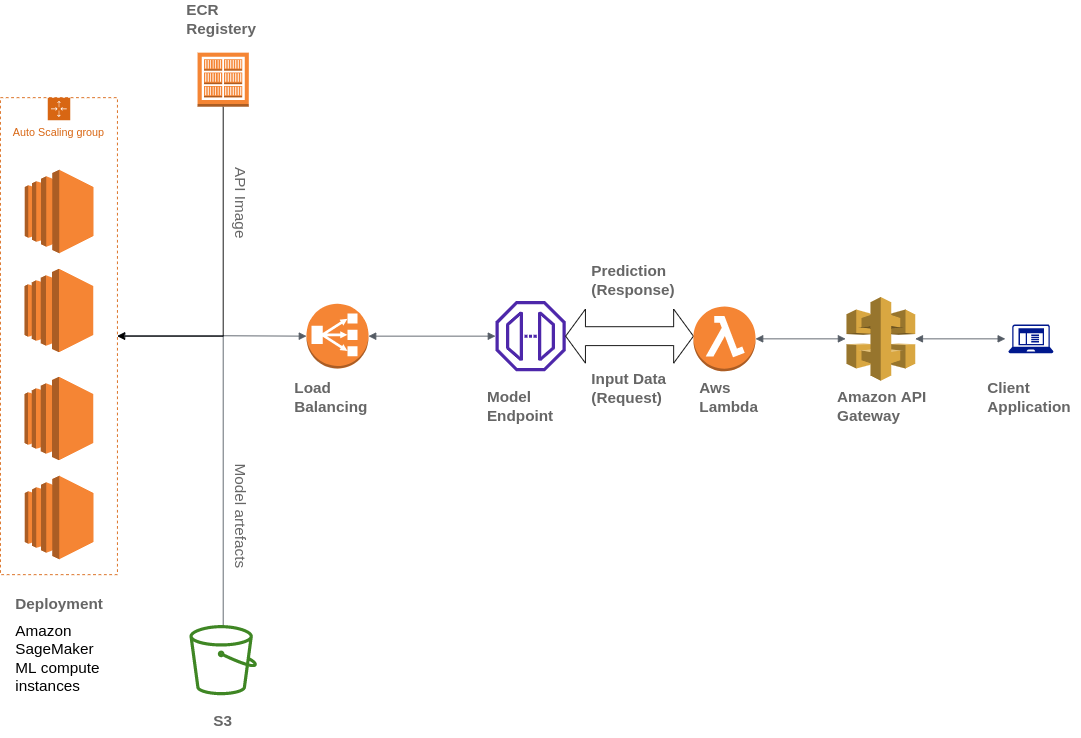
Widebot war auf der Suche nach einer Lösung, um die ML-Modelle, die sie für ihre Kunden entwickelt hatten, sicher als API-Endpunkt zu veröffentlichen. Sie nutzten API Gateway, einen vollständig verwalteten Service, um die API-Endpunkte der auf SageMaker bereitgestellten ML-Modelle zu veröffentlichen, zu verwalten, zu überwachen und zu sichern. API Gateway wird als nach außen gerichteter, zentraler Zugangspunkt für SageMaker-Endgeräte verwendet, sodass diese von Kunden aus einfach und sicher zugänglich sind.
Clients interagieren mit dem SageMaker-Inferenzendpunkt, indem sie eine API-Anforderung an den API-Gateway-Endpunkt senden. Das API Gateway ordnet Client-Anfragen dem entsprechenden SageMaker-Inferenzendpunkt zu und ruft den Endpunkt auf, um eine Inferenz aus dem Modell zu erhalten. Anschließend empfängt das API Gateway die Antwort vom SageMaker-Endpunkt und ordnet sie in einer an den Client gesendeten Antwort zurück.
Lösung im Überblick
Wie hat Widebot eine erfolgreiche neue Lösung für Deep-Learning-Modelle zur arabischen Stimmungsanalyse entwickelt? Hier sind die Schritte, denen sie gefolgt sind:
Erfassung und Aufbereitung von Datensätzen
Sammeln Sie Zehntausende von Datenproben aus verschiedenen Datenquellen (sowohl öffentlich als auch intern).
Überprüfen Sie die Datensätze sorgfältig, wenden Sie Daten-Labeling an und verbessern Sie die Datenqualität, indem Sie irrelevante Stichproben entfernen.
Das Datenteam führt einen Annotationsprozess durch und verwendet Amazon SageMaker Ground Truth, um genügend Proben aus verschiedenen Domains und Schreibstilen zu annotieren, um den verwendeten Datensatz anzureichern.
Senden Sie die Proben durch die Vorverarbeitungspipeline, bevor Sie das Modell mithilfe von Deep Learning trainieren, um den Eingabetext mit der jeweiligen Wahrscheinlichkeit als positiv, negativ oder neutral zu klassifizieren.
Aufbauen und Trainieren des Modells
Verwenden Sie ein Convolutional Neural Network (CNN)-Modell, das mit Keras und TensorFlow trainiert wurde.
Wenden Sie viele Iterationen an, um verschiedene Vorverarbeitungspipelines, Architekturen und Tokenizer zu testen, bis Sie die Architektur erreicht haben, die die besten Ergebnisse für verschiedene Probedatensätze und aus verschiedenen Domains liefert.
Verwenden Sie eine native, intern entwickelte Vorverarbeitungspipeline, um unnötige Informationen aus dem Text zu entfernen: Daten, URLs, Erwähnungen, E-Mail-Adressen, Satzzeichen (außer „!?“) , und Zahlen.
Wenden Sie Schritte zur Normalisierung von arabischem Text an, z. B. das Entfernen diakritischer Zeichen und das Normalisieren einiger Buchstaben, die Benutzer synonym verwendet haben, wie (ء أ ئ ؤ إ) oder yaa (ي ى) oder andere Zeichen.
Wenden Sie einen leichten Wortstamm auf den Text an, wodurch einige Suffixe und Präfixe entfernt und einige überhöhte Wörter auf ihren Wortstamm reduziert werden (z. B. (التعيينات), reduziert zu (تعيين)).
Speichern Sie das Modell, den Präprozessor, die Hyperparameter und die Tokenizer mithilfe der Serialisierung und exportieren Sie sie als.h5- und.pickle-Dateien.
Bereitstellen des Modells auf Amazon SageMaker
Binden Sie das Modell in eine API ein, den Vorhersageendpunkt. Dieser Endpunkt akzeptiert JSON-Eingaben vom Endbenutzer und wandelt Daten in eine einfachere Datenstruktur um, bereinigt sie und gibt die Stimmungsergebnisse der Eingabedaten zurück.
Erstellen Sie ein Docker-Image, das den Code, alle Abhängigkeiten und Anweisungen enthält, die zum Erstellen und Ausführen der Komponenten in einer beliebigen Umgebung erforderlich sind.
Laden Sie die Modellartefakte in einen Amazon-S3-Bucket und das Docker-Image in Amazon ECR hoch.
Stellen Sie das Modell mit SageMaker bereit und wählen Sie den Image-Speicherort in Amazon ECR und die Artefakt-URI im Amazon-S3-Bucket aus.
Erstellen Sie mit SageMaker einen Endpunkt und nutzen Sie API Gateway, um den Endpunkt für ihre Kunden zu veröffentlichen.
Art und Umfang der Daten
Um ihr Modell zu erstellen, bestehen die Daten von Widebot aus ungefähr 100 000 verschiedenen Nachrichten für das Training und 20 000 Nachrichten für die Validierung und das Testen. Die Nachrichten:
- Kamen aus verschiedenen Branchen wie E-Commerce, Lebensmittel und Getränke sowie Finanzdienstleistungen.
- Eingeschlossene Bewertungen für verschiedene Services oder Produkte. Zum Beispiel Hotelkritiken, Buchungsrezensionen, Restaurantbewertungen und Unternehmensbewertungen.
- Der Ton reichte von einer sehr formellen Sprache bis hin zur Verwendung strenger profaner Wörter.
- Wurden sowohl im ägyptischen Dialekt als auch im modernen Hocharabisch geschrieben.
- Wurden in eine von drei Klassen eingeteilt: negativ, neutral oder positiv.
Die folgende Tabelle enthält Beispielnachrichten:
| Beispiel | Stimmung | Zuverlässigkeit |
| الخدمة لديكم مناسبة „Ihr Service ist gut“ | positiv | 0,8471 |
| شكرا لحسن تعاونكم „Vielen Dank für Ihre Mitarbeit“ | positiv | 0,9688 |
| الخدمة والتعامل لديكم دون المستوى „Ihr Service ist unterdurchschnittlich“ | negativ | 0,8982 |
| حالة الجو سيئة جدا „Das Wetter ist sehr schlecht“ | negativ | 0,9737 |
| سأعاود الإتصال بكم وقت لاحق „Ich melde mich später bei Ihnen“ | neutral | 0,8255 |
| أريد الإستعلام عن الخدمات „Ich möchte mich nach den Dienstleistungen erkundigen“ | neutral | 0,9728 |
Zusammenfassung der Ergebnisse
Widebot testete sein Modell anhand verschiedener arabischer Textdatensätze in verschiedenen Dialekten. Diese Metriken wurden anhand von Datensätzen mit Tausenden von Proben gemessen. Der F1-Punktestand wird verwendet, um die Genauigkeit des Modells mit den verschiedenen Datensätzen zu messen. Das Makro und die gewichteten Durchschnittswerte des F1-Punktestands werden verwendet, um die allgemeine Präzision und Leistung zu messen.
Die Genauigkeit des Modells
Der Testdatensatz (20 679 Proben im Verhältnis 5 004:1 783:13 892)
| Negativer F1 | Neutraler F1 | Positiver F1 | Gesamte Genauigkeit | Makro-Durchschnitt | Gewichteter Durchschnitt |
| 89,9 | 79,4 | 95,1 | 92,5 | 88,1 | 92,5 |
Die Antwortzeit des Modells
Widebot hat die Antwortzeit anhand der durchschnittlichen (AVG), minimalen (MIN) und maximalen (MAX) Sekunden pro Antwort (Sekunden/Antwort) gemessen:
- Durchschnitt: 0,106 Sek./Antwort
- MIN: 0,088 Sek./Antwort
- MAX: 0,957 Sek./Antwort
Im Folgenden wird die Antwortzeitmetrik zwischen der Verwendung einer Allzweck-Rechenplattform und der Verwendung von Amazon SageMaker für das Modellhosting verglichen, wenn dieselben Datensätze mit einer durchschnittlichen Nutzlastgröße von 2 KB bereitgestellt werden.
| Gesamtantwortzeit | Gesamtantwortzeit Allgemeine Rechenplattform (EC2-Instances: p2.xlarge) | Amazon SageMaker (SageMaker-Instances: ml.m4.xlarge) |
| Durchschnittlich | 0,202 Sek./Antwort | 0,106 Sek./Antwort |
| Minimum | 0,097 Sek./Antwort | 0,088 Sek./Antwort |
| Maximum | 8,458 Sek./Antwort | 0,957 Sek./Antwort |
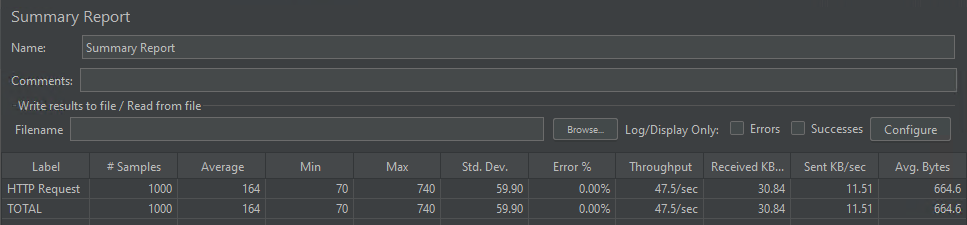
Die Modellparallelität
Das Modell war in der Lage, 1 000 gleichzeitige Anfragen zu verarbeiten, die im Durchschnitt in 164 Millisekunden bearbeitet wurden.
Fazit
Dieser Beitrag zeigt, wie AWS-Services Widebot dabei geholfen haben, mithilfe eines auf SageMaker gehosteten Deep-Learning-Modells eine umfassende Lösung zum Extrahieren von Stimmungen aus Chat-Texten in verschiedenen arabischen Dialekten zu entwickeln.
SageMaker half Widebot, Innovationen zu beschleunigen und seinen Stimmungsklassifizierer einzusetzen, um das komplexe ML-Problem der Extraktion von Stimmungen aus arabischem Konversationstext zu lösen und diesen als öffentlichen RESTful-Endpunkt zu veröffentlichen, auf den Kunden einfach und sicher über das API Gateway zugreifen können.
Dieser Ansatz könnte für viele ähnliche Anwendungsfälle nützlich sein, in denen Kunden ihr ML-Modell auf SageMaker erstellen, trainieren und bereitstellen und dann den Modellinferenzendpunkt für ihre Kunden auf einfache, aber sichere Weise mithilfe des API Gateways veröffentlichen möchten.
Wenn Sie mehr über sprachliche Vielfalt und die Feinabstimmung vorab trainierter transformatorbasierter Sprachmodelle auf Amazon SageMaker erfahren möchten, können Sie diesen Blogpost lesen.

Mohamed Mostafa
Mohamed Mostafa ist Mitgründer und CTO bei WideBot. Seine Leidenschaft gilt der Anwendung moderner Ingenieurspraktiken und der Entwicklung hochwertiger Software zur Verbesserung des Benutzererlebnisses.

Ahmed Azzam
Ahmed Azzam ist ein Senior Solutions Architect mit Sitz in Dubai, Vereinigte Arabische Emirate. Seine Leidenschaft ist es, Startups dabei zu helfen, nicht nur skalierbare Anwendungen zu entwerfen und zu entwickeln, sondern auch bei der Entwicklung innovativer Lösungen mithilfe von AWS-Services große Maßstäbe zu setzen.
Wie war dieser Inhalt?