このコンテンツはいかがでしたか?
- 学ぶ
- Widebot がアラビア語の感情分析に Amazon SageMaker を活用する方法
Widebot がアラビア語の感情分析に Amazon SageMaker を活用する方法
スタートアップは、優れたカスタマーエクスペリエンスを生み出すことの重要性をよく知っています。そのためのツールの 1 つが感情分析です。テキスト分析や自然言語処理 (NLP) などの機械学習技術に基づいて、データをポジティブ、ネガティブ、ニュートラルに分類します。企業は感情分析を使用して、対象となる製品やサービスに対する顧客の満足度を測定します。
アラビア語のエンドユーザーの場合、感情分析を行うのは特に困難な場合があります。中東および北アフリカ (MENA) 地域の人々はアラビア語の方言を 20 種類以上話し、その中で最も一般的な言語は現代標準アラビア語です。
このブログ記事では、Widebot が Amazon Sagemaker を使用して感情分類機能を正常に実装する方法を説明しています。Widebot は MENA 地域のアラビア語に焦点を当てた主要な会話型人工知能 (AI) チャットボットプラットフォームの 1 つです。同社の感情分類機能は、現代標準アラビア語だけでなく、エジプトの方言アラビア語もサポートしており、さまざまなドメインの複数のデータセットによるテストの結果、高い精度を示しています。
Widebot のモデルは、新しいドメインやデータセットからのサンプルが数百に及んだとしても、簡単に調整できます。そのため、このソリューションは汎用性があり、さまざまなドメインやユースケースに適応できます。
優れたチャットボットの特徴
チャットボットは、カスタマーエクスペリエンスの管理と改善に役立つだけでなく、タスクを自動化して従業員が会社の使命にとって重要な仕事に集中できるようにする便利なツールです。特に Startups は、成功のために最も重要なタスクに時間を割けるようにマネージドサービスを利用することの価値をよく知っています。
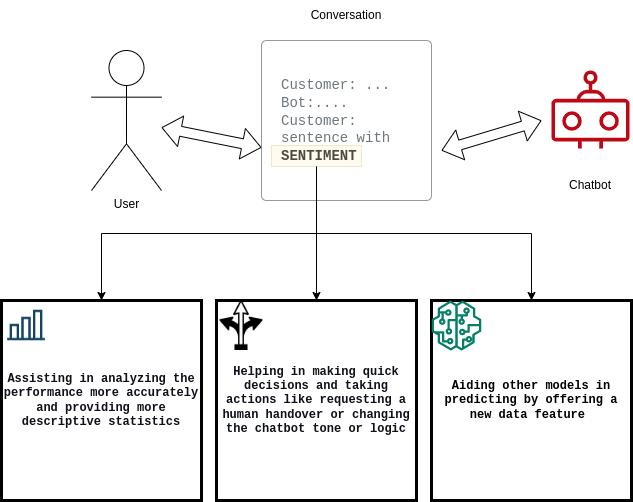
チャットボットにとって重要なのは、満足している顧客と満足していない顧客を数値化し、満足度から不満度 (またはその逆) への変換率を文書化することです。これらの要件を満たすため、Widebot のソリューションは、
- ユーザーがチャットボットシステムのパフォーマンスを分析するのに役立ちます
- チャットボットの意思決定を改善します
- 他のダウンストリーム機械学習 (ML) モデルを支援します
感情分析を構築する際の技術的課題
Widebot のデータサイエンティストは、顧客の高まる期待に応えるために、深層学習モデルの強化と最適化のイノベーションを常に行っています。アラビア語のチャットボットの顧客により良いサービスを提供するため、彼らはアラビア語の感情分析深層学習モデル用の新しいソリューションの開発に取り組みました。
これには以下のような課題がありました。
- モデルスケーラビリティ
- 応答時間
- 大量の同時実行リクエスト
- ランニングコスト
多くのスタートアップがそうであるように、当初は、このモデルをセルフマネージド型インフラストラクチャと汎用サーバーにデプロイしていました。しかし、スタートアップが成長するにつれ、増え続けるデータと同時リクエストの急増に対応できるようにモデルを効率的にスケールすることができなくなりました。
Widebot は、基盤となるインフラストラクチャと機械学習オペレーション (MLOps) ワークフローの管理とスケーリングに過度の時間を費やすことなく、モデルの迅速な構築に集中できるソリューションを探し始めました。
Amazon SageMaker へのモデルのデプロイ
Widebot が SageMaker を選択したのは、すべての機械学習推論ニーズを満たすための ML インフラストラクチャとモデルデプロイのオプションを幅広く提供しているからです。SageMaker により、スタートアップは ML モデルを最高のコストパフォーマンスで簡単にデプロイできます。
Widebot の共同創設者兼最高技術責任者 (CTO) である Mohamed Mostafa 氏は、「幸いにも、Amazon SageMaker により、モデル開発のライフサイクル全体を通じて完全な所有権と制御が実現できることがわかりました。SageMaker のシンプルで強力なツールにより、MLOps のプラクティスを自動化および標準化して、セルフマネージド型インフラストラクチャと比較して、より簡単かつ迅速にモデルを構築、トレーニング、デプロイ、管理できるようになりました」と述べています。
これにより、Widebot チームは顧客の期待に応える ML モデルの構築と強化に集中できるようになり、SageMaker はインスタンスの設定と管理、ソフトウェアバージョンの互換性、バージョンへのパッチの適用を行っています。また、SageMaker には、モデルの状態とパフォーマンスを継続的に監視するための、エンドポイント用のメトリクスおよびログも組み込まれています。
Amazon SageMaker Inference Recommender により、Widebot は ML モデルをデプロイするための最適なコンピューティングインスタンスと構成を選択し、最適な推論パフォーマンスとコストを実現することができるようになりました。これにより、コンピューティングインスタンスタイプ、インスタンス数、コンテナパラメータ、モデル最適化を推論対象として自動的に選択し、パフォーマンスを最大化し、コストを最小限に抑えることができます。
Widebot はまた、Amazon Simple Storage Service (Amazon S3)、AWS Lambda、Amazon API Gateway、Amazon Elastic Container Registry (ECR) など、さまざまな AWS サービスを使用してアーキテクチャを構築しています。
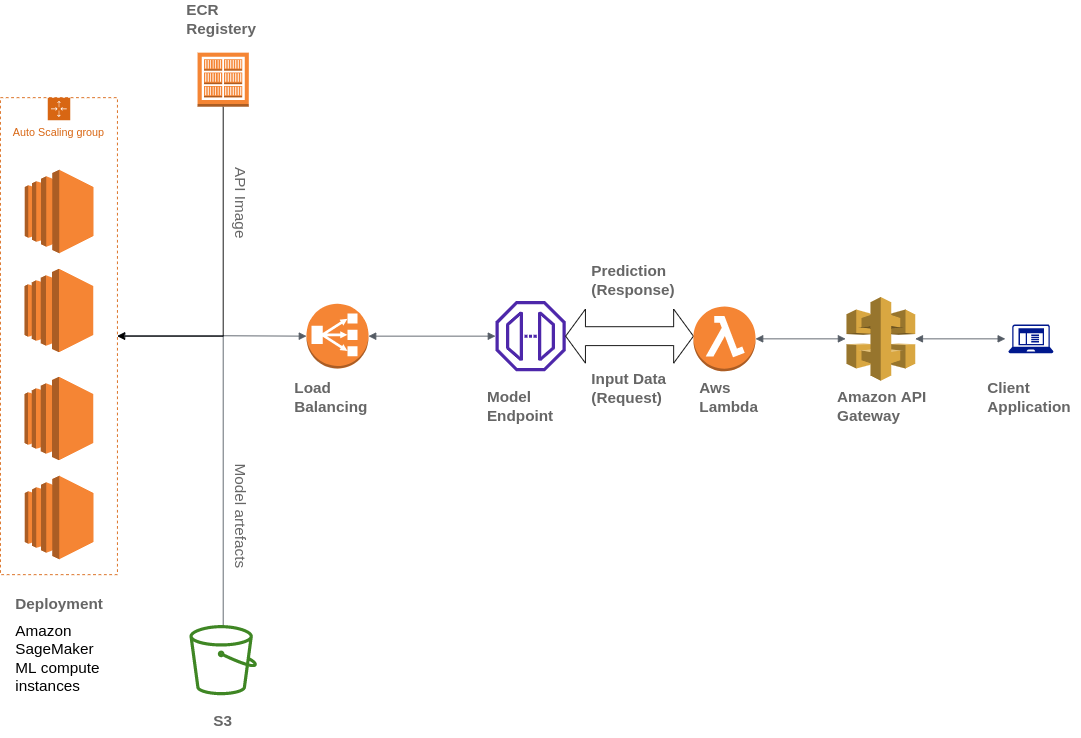
Widebot は、顧客向けに開発した ML モデルを API エンドポイントとして安全に公開するソリューションを探していました。同社は、SageMaker にデプロイされた ML モデルの API エンドポイントを公開、保守、監視、保護するために、フルマネージドサービスである API Gateway を使用しました。API Gateway は SageMaker エンドポイントの外部向け単一エントリポイントとして使用されているため、クライアントから簡単かつ安全にアクセスできます。
クライアントは API リクエストを API Gateway エンドポイントに送信することで SageMaker 推論エンドポイントとやりとりします。API Gateway はクライアント要求を対応する SageMaker 推論エンドポイントにマッピングし、エンドポイントを呼び出してモデルから推論を取得します。その後、API Gateway は SageMaker エンドポイントからレスポンスを受け取り、それをマッピングしてクライアントに送信するレスポンスとして返します。
ソリューションの概要
Widebot はどのようにしてアラビア語の感情分析深層学習モデル用の新しいソリューションを構築し、成功を収めたのでしょうか。彼らがたどった手順は以下のとおりです。
データセットの収集と準備
さまざまなデータソース (公開および社内の両方) から何万ものデータサンプルを収集します。
データセットを注意深く確認し、データラベリングを適用し、無関係なサンプルを削除してデータ品質を向上させます。
データチームは、Amazon SageMaker Ground Truth を使用して、使用するデータセットを充実させるために、さまざまなドメインや記述スタイルからの十分な数のサンプルに注釈を付ける、アノテーション処理を行います。
前処理パイプラインにサンプルを送信してから、深層学習を使用してモデルをトレーニングし、入力テキストをポジティブ、ネガティブ、またはニュートラルに、それぞれの確率で分類します。
モデルの構築とトレーニング
Keras と TensorFlow を使用してトレーニングされた畳み込みニューラルネットワーク (CNN) モデルを使用します。
さまざまなサンプルデータセットとさまざまなドメインで最良の結果が得られるアーキテクチャに到達するまで、さまざまな前処理パイプライン、アーキテクチャ、トークナイザーを何度も繰り返しテストします。
社内で開発されたネイティブの前処理パイプラインを使用して、日付、URL、メンション、電子メールアドレス、句読点 (「!?」を除く)、数字などの不要な情報をテキストから削除します。
アラビア語のテキスト正規化手順を適用します。たとえば、発音区別符号を削除したり、(ء أ ئ ؤ إ) や yaa (ي ى) や他の文字など、ユーザーが置き換えて使用していた文字を正規化したりします。
テキストに軽いステミングを適用して、一部の接尾辞や接頭辞を削除し、膨らんだ単語を語幹に減らします ((التعيينات) を (تعيين) に減らすなど)。
シリアル化を使用して、モデル、プリプロセッサ、ハイパーパラメータ、トークナイザーを保存し、.h5 ファイルおよび .pickle ファイルとしてエクスポートします。
Amazon SageMaker へのモデルのデプロイ
モデルを API (予測エンドポイント) にラップします。このエンドポイントはエンドユーザーからの JSON 入力を受け入れ、データをより簡単なデータ構造に変換してクリーンアップし、入力データの感情結果を返します。
あらゆる環境でコンポーネントをビルドして実行するために必要なコード、すべての依存関係、および命令を含む Docker イメージを作成します。
モデルアーティファクトを Amazon S3 バケットにアップロードし、Docker イメージを Amazon ECR にアップロードします。
SageMaker を使用してモデルをデプロイし、Amazon ECR 内のイメージの場所と Amazon S3 バケット内のアーティファクト URI を選択します。
SageMaker を使用してエンドポイントを作成し、API Gateway を利用してエンドポイントをクライアントに公開します。
データの種類と量
モデルを構築するための Widebot のデータは、トレーニング用の約 100,000 種類のメッセージと、検証とテスト用の 20,000 のメッセージで構成されています。メッセージは以下のとおりです。
- e コマース、食品、飲料、金融サービスなど、さまざまな業界に及びます。
- さまざまなサービスや製品のレビューが含まれています。たとえば、ホテルのレビュー、予約のレビュー、レストランのレビュー、会社のレビューなどです。
- 非常に形式的な言葉からひどく下品な言葉まで、口調は多岐にわたります。
- エジプトの方言と現代標準アラビア語の両方で書かれています。
- ネガティブ、ニュートラル、ポジティブの 3 つのクラスのいずれかに分類されます。
以下の表は、メッセージのサンプルを示しています。
| 例 | 感情 | 信頼性 |
| الخدمة لديكم مناسبة 「良いサービスです」 | ポジティブ | 0.8471 |
| شكرا لحسن تعاونكم 「ご協力ありがとうございます」 | ポジティブ | 0.9688 |
| الخدمة والتعامل لديكم دون المستوى 「標準以下のサービスです」 | ネガティブ | 0.8982 |
| حالة الجو سيئة جدا 「天気がとても悪いです」 | ネガティブ | 0.9737 |
| سأعاود الإتصال بكم وقت لاحق 「後ほどご連絡します」 | ニュートラル | 0.8255 |
| أريد الإستعلام عن الخدمات 「サービスについて問い合わせたいです」 | ニュートラル | 0.9728 |
結果の概要
Widebot は、さまざまな方言のさまざまなアラビア語のテキストデータセットに対してモデルをテストしました。これらのメトリクスは、何千ものサンプルを含むデータセットを使用して測定されています。F1 スコアは、さまざまなデータセットにおけるモデルの精度を測定するために使用されます。F1 スコアのマクロ平均と加重平均を使用して、全体的な精度とパフォーマンスを測定します。
モデルの精度
テストデータセット (20,679 サンプルで 5004:1783:13892 の比率)
| ネガティブ F1 | ニュートラル F1 | ポジティブ F1 | 全体的な精度 | マクロ平均 | 加重平均 |
| 89.9 | 79.4 | 95.1 | 92.5 | 88.1 | 92.5 |
モデルの応答時間
Widebot は、応答あたりの平均秒数 (AVG)、最小秒数 (MIN)、最大秒数 (MAX) を使用して応答時間を測定しました (秒/応答)。
- 平均: 0.106 秒/応答
- 最小: 0.088 秒/応答
- 最大: 0.957 秒/応答
平均ペイロードサイズが 2 KB の同じデータセットをデプロイする際の、汎用コンピューティングプラットフォームを使用する場合と、モデルホスティングに Amazon SageMaker を使用する場合の応答時間メトリクスの比較を以下に示しています。
| 合計応答時間 | 合計応答時間 汎用コンピューティングプラットフォーム (EC2 インスタンス: p2.xlarge) | Amazon SageMaker (SageMaker インスタンス: ml.m4.xlarge) |
| 平均 | 0.202 秒/応答 | 0.106 秒/応答 |
| 最小 | 0.097 秒/応答 | 0.088 秒/応答 |
| 最大 | 8.458 秒/応答 | 0.957 秒/応答 |
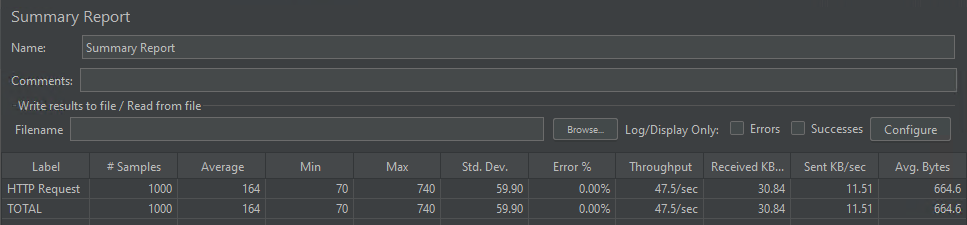
モデルの同時実行性
このモデルは、平均 164 ミリ秒で処理された 1,000 件の同時リクエストを処理できました。
まとめ
この記事では、Widebot が SageMaker でホストされている深層学習モデルを使用して、さまざまなアラビア語の方言の会話テキストから感情を抽出する包括的なソリューションを構築するのに AWS のサービスがどのように役立ったかを紹介しています。
SageMaker により、Widebot のイノベーションは加速し、感情分類機能をデプロイできるようになりました。これにより、アラビア語の会話テキストから感情を抽出するという複雑な機械学習問題を解決し、公開 RESTful エンドポイントとして公開してクライアントが API Gateway 経由で簡単かつ安全にアクセスできるようになりました。
このアプローチは、顧客が SageMaker で ML モデルを構築、トレーニング、デプロイし、API Gateway を使用してシンプルかつ安全な方法でその顧客向けにモデル推論エンドポイントを公開したい場合など、多くの同様のユースケースに役立つ可能性があります。
言語の多様性や、Amazon SageMaker で事前にトレーニングされたトランスフォーマーベースの言語モデルを微調整する方法について詳しく知りたい場合は、このブログ投稿をご覧ください。

Mohamed Mostafa
Mohamed Mostafa 氏は WideBot の共同創業者兼 CTO です。最新のエンジニアリング手法を適用し、高品質のソフトウェアを開発して、ユーザーエクスペリエンスを改善することに情熱を傾けています。

Ahmed Azzam
Ahmed Azzam は Senior Solutions Architect であり、UAE のドバイに所在しています。スタートアップがスケーラブルなアプリケーションを設計および開発するだけでなく、AWS のサービスを利用した革新的なソリューションについて深く考えるのをサポートすることに情熱を傾けています。
このコンテンツはいかがでしたか?