AWS Türkçe Blog
Yeni – Üretken Yapay Zeka ve HPC Uygulamalarını Hızlandırmak için NVIDIA H100 Tensor Core GPU’larla Güçlendirilmiş Amazon EC2 P5 Sunucuları
Orijinal makale: Link (Channy Yun)
Mart 2023’te AWS ve NVIDIA, giderek daha karmaşık hale gelen büyük dil modellerini (LLM’ler) eğitmek ve üretken yapay zeka uygulamaları geliştirmek için optimize edilmiş en ölçeklenebilir, isteğe bağlı yapay zeka (AI) altyapısını oluşturmaya odaklanan çok parçalı bir iş birliği duyurdu.
En büyük makine öğrenimi (ML) modellerini oluşturmak ve eğitmek için 20 exaflop’a kadar işlem performansı sunacak NVIDIA H100 Tensor Core GPU’lar ve AWS’in en yeni ağ iletişimi ve ölçeklenebilirliği ile desteklenen Amazon Elastic Compute Cloud (Amazon EC2) P5 sunucularını önceden duyurduk. Bu duyuru, Cluster GPU (cg1) sunucularında (2010), G2 (2013), P2 (2016), P3 (2017), G3 (2017), P3dn (2018), G4 (2019), P4 (2020), G5 (2021) ve P4de sunucularında (2022) görsel bilgi işlem, yapay zeka ve yüksek performanslı bilgi işlem (HPC) kümeleri sunan AWS ve NVIDIA arasındaki on yılı aşkın işbirliğinin ürünüdür.
En önemlisi, makine öğrenimi model boyutları artık trilyonlarca parametreye ulaşıyor. Ancak bu karmaşıklık, müşterilerin eğitim süresini artırdı; en yeni LLM’ler artık birkaç ay boyunca eğitiliyor. HPC müşterileri de benzer eğilimler sergiliyor. HPC müşterilerinin veri toplama hızı arttıkça ve veri setleri exabyte ölçeğine ulaştıkça, müşteriler giderek daha karmaşık hale gelen uygulamalarda daha hızlı çözüme ulaşma süresi sağlamanın yollarını arıyor.
EC2 P5 Sunucuları ile tanışın
Bugün, AI/ML ve HPC iş yüklerinde yüksek performans ve ölçeklenebilirlik için bu müşteri ihtiyaçlarını karşılamak üzere yeni nesil GPU sunucuları olan Amazon EC2 P5 sunucularının genel kullanılabilirliğini duyuruyoruz. P5 sunucuları, en yeni NVIDIA H100 Tensor Core GPU’lar tarafından desteklenmektedir ve önceki nesil GPU tabanlı sunuculara kıyasla eğitim süresinde 6 kata kadar (günlerden saatlere) azalma sağlayacaktır. Bu performans artışı, müşterilerin yüzde 40’a kadar daha düşük eğitim maliyetleri görmesini sağlayacaktır.
P5 sunucuları, 640 GB yüksek bant genişliğine sahip GPU belleğine sahip 8 x NVIDIA H100 Tensor Core GPU, 3. Nesil AMD EPYC işlemciler, 2 TB sistem belleği ve 30 TB yerel NVMe depolama alanı sağlar. P5 sunucuları ayrıca GPUDirect RDMA desteğiyle 3200 Gbps toplam ağ bant genişliği sağlayarak düğümler arası iletişimde CPU’yu atlayarak daha düşük gecikme süresi ve verimli ölçeklendirme performansı sağlar.
İşte bu sunucu için teknik özellikler:
| Instance Size | vCPUs | Memory (GiB) | GPUs (H100) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | Local Storage (TB) |
| p5.48xlarge | 192 | 2048 | 8 | 3200 | 80 | 8 x 3.84 |
İşte size P5 sunucularının ve NVIDIA H100 Tensor Core GPU’ların önceki sunucularla ve işlemcilerle nasıl karşılaştırıldığını gösteren hızlı bir infografik:
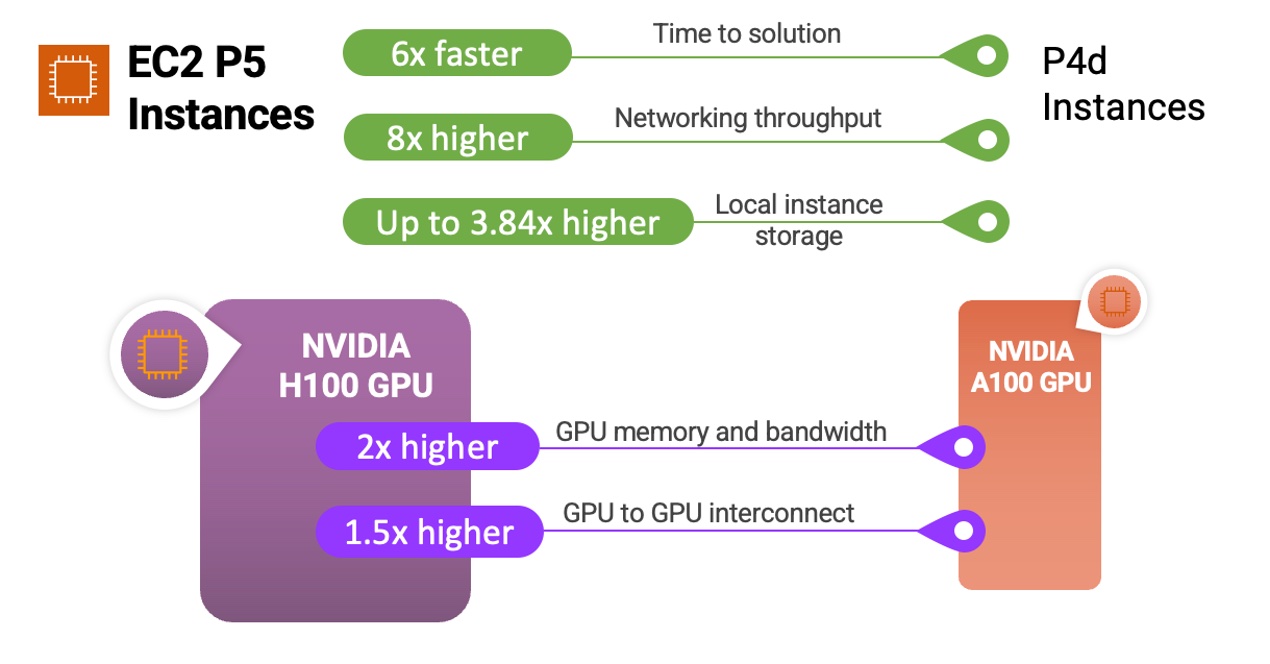
P5 sunucuları, soru yanıtlama, kod oluşturma, video ve görüntü oluşturma, konuşma tanıma ve daha fazlası dahil olmak üzere en zorlu ve hesaplama yoğun üretken yapay zeka uygulamalarının arkasındaki giderek karmaşıklaşan LLM’ler ve görüntü işleme modelleri için eğitim ve çıkarım çalıştırmak için idealdir. P5, bu uygulamalarda önceki nesil GPU tabanlı sunuculara kıyasla 6 kata kadar daha düşük eğitme süresi sağlayacaktır. İş yüklerinde, dönüştürücü model omurgası kullanan birçok dil modelinde yaygın olan daha düşük hassasiyetli FP8 veri türlerini kullanabilen müşteriler, NVIDIA dönüştürücü motoru desteği sayesinde 6 kata kadar performans artışı ile daha fazla fayda görecekler.
P5 sunucularını kullanan HPC müşterileri, ilaç keşfi, sismik analiz, hava tahmini ve finansal modelleme gibi zorlu uygulamaları daha büyük ölçekte dağıtabilir. Genom dizileme veya hızlandırılmış veri analizi gibi uygulamalar için dinamik programlama (DP) algoritmaları kullanan müşteriler de yeni DPX komut seti desteği sayesinde P5’ten daha fazla fayda görecekler.
Bu, müşterilerin daha önce ulaşılamaz görünen sorun alanlarını keşfetmelerini, çözümlerini daha hızlı bir şekilde yinelemelerini ve pazara daha hızlı bir şekilde ulaşmalarını sağlar.
Sunucu özelliklerinin ayrıntılarını ve p4d.24xlarge ile yeni p5.48xlarge arasındaki sunucu türlerinin karşılaştırmalarını aşağıda görebilirsiniz:
| Özellik | p4d.24xlarge | p5.48xlarge | Karşılaştırma |
| Hızlandırıcı Sayısı ve Türü | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| Sunucu Başına FP8 TFLOPS | – | 16,000 | 6.4x
vs.A100 FP16 |
| Sunucu Başına FP16 TFLOPS | 2,496 | 8,000 | |
| GPU Bellek | 40 GB | 80 GB | 2x |
| GPU Bellek Bant Genişliği | 12.8 TB/s | 26.8 TB/s | 2x |
| CPU Ailesi | Intel Cascade Lake | AMD Milan | – |
| vCPU’lar | 96 | 192 | 2x |
| Toplam Sistem Belleği | 1152 GB | 2048 GB | 2x |
| Ağ Verimi | 400 Gbps | 3200 Gbps | 8x |
| EBS Verimi | 19 Gbps | 80 Gbps | 4x |
| Yerel Sunucu Depolama | 8 TBs NVMe | 30 TBs NVMe | 3.75x |
| GPU – GPU Ara Bağlantısı | 600 GB/s | 900 GB/s | 1.5x |
İkinci nesil Amazon EC2 UltraClusters ve Elastic Fabric Adaptörü
P5 sunucuları, çok düğümlü dağıtılmış eğitim ve sıkı bağlanmış HPC iş yükleri için pazar lideri ölçeklendirme yeteneği sağlar. İkinci nesil Elastic Fabric Adaptor (EFA) teknolojisini kullanarak P4d sunucularına kıyasla 8 kat daha fazla, 3.200 Gbps’ye kadar ağ bağlantısı sunarlar.
Müşterilerin büyük ölçekli ve düşük gecikme süresine yönelik ihtiyaçlarını karşılamak için P5 sunucuları, artık müşterilere 20.000’den fazla NVIDIA H100 Tensor Core GPU’da daha düşük gecikme süresi sağlayan ikinci nesil EC2 UltraClusters‘ta konuşlandırılıyor. Buluttaki en büyük ML altyapısı ölçeğini sağlayan EC2 UltraClusters’daki P5 sunucuları, 20 exaflop’a kadar toplam işlem kapasitesi sunar.

EC2 UltraClusters, en popüler yüksek performanslı paralel dosya sistemi üzerine inşa edilmiş, tam olarak yönetilen paylaşılan depolama alanı olan Lustre için Amazon FSx‘i kullanır. Lustre için FSx ile devasa veri kümelerini talep üzerine ve büyük ölçekte hızlı bir şekilde işleyebilir ve milisaniyenin altında gecikme süreleri sunabilirsiniz. Lustre için FSx’in düşük gecikme süresi ve yüksek verim özellikleri, EC2 UltraCluster’lardaki derin öğrenme, üretken yapay zeka ve HPC iş yükleri için optimize edilmiştir.
Lustre için FSx, EC2 UltraCluster’lardaki GPU’ları ve makine öğrenimi hızlandırıcılarını verilerle besleyerek en zorlu iş yüklerini hızlandırır. Bu iş yükleri arasında LLM eğitimi, üretken yapay zeka çıkarımı ve genomik ve finansal risk modellemesi gibi HPC iş yükleri yer alır.
EC2 P5 Sunucularını Kullanmaya Başlarken
Başlamak için ABD Doğu (N. Virginia) ve ABD Batı (Oregon) Bölgelerindeki P5 sunucularını kullanabilirsiniz.
P5 sunucularını başlatırken, P5 sunucularını desteklemek için AWS Derin Öğrenme AMI‘lerini (DLAMI’ler) seçeceksiniz. DLAMI, ML uygulayıcılarına ve araştırmacılarına önceden yapılandırılmış ortamlarda hızla ölçeklenebilir, güvenli dağıtılmış ML uygulamaları oluşturmaları için altyapı ve araçlar sağlar.
Amazon Elastic Container Service (Amazon ECS) veya Amazon Elastic Kubernetes Service (Amazon EKS) kütüphanelerini kullanarak AWS Derin Öğrenme Container’ları ile P5 sunucuları üzerinde konteynerli uygulamalar çalıştırabileceksiniz. Daha yönetilebilir bir deneyim için P5 sunucularını, geliştiricilerin ve veri bilimcilerin kümeler ve veri hatları kurma konusunda endişelenmeden bir modeli herhangi bir ölçekte hızlı bir şekilde eğitmek için onlarca, yüzlerce veya binlerce GPU’ya kolayca ölçeklendirmelerine yardımcı olan Amazon SageMaker aracılığıyla da kullanabilirsiniz. HPC müşterileri, işleri ve kümeleri verimli bir şekilde düzenlemeye yardımcı olmak için P5 ile AWS Batch ve ParallelCluster‘dan yararlanabilirler.
Mevcut P4 müşterilerinin P5 sunucularını kullanmak için AMI’lerini güncellemeleri gerekecektir. Özellikle, AMI’lerinizi NVIDIA H100 Tensor Core GPU’ları destekleyen en son NVIDIA sürücüsünü içerecek şekilde güncellemeniz gerekecektir. Ayrıca en son CUDA sürümünü (CUDA 12), CuDNN sürümünü, çerçeve sürümlerini (ör. PyTorch, Tensorflow) ve güncellenmiş topoloji dosyalarına sahip EFA sürücüsünü yüklemeleri gerekecektir. Bu süreci sizin için kolaylaştırmak amacıyla, P5 sunucularını kutudan çıkar çıkmaz kullanmak için gerekli tüm yazılım ve çerçevelerle birlikte paketlenmiş olarak gelen yeni DLAMI’ler ve Derin Öğrenme Container’ları sağlayacağız.
Şimdi Kullanılabilir
Amazon EC2 P5 sunucuları bugün AWS Bölgelerinde kullanıma sunuldu: ABD Doğu (N. Virginia) ve ABD Batı (Oregon). Daha fazla bilgi için Amazon EC2 fiyatlandırma sayfasına bakın. Daha fazla bilgi edinmek için EC2 P5 sunucu sayfasına bakın ve AWS re:Post for EC2 adresine veya her zamanki AWS Destek irtibatlarınız aracılığıyla geri bildirim gönderin.
Üretken yapay zeka için en uygun maliyetli bulut altyapısı üzerinde çalışan, yerleşik üretken yapay zekaya sahip çok çeşitli AWS hizmetlerini seçebilirsiniz. Daha fazla bilgi edinmek için AWS’te Üretken Yapay Zeka‘yı ziyaret ederek daha hızlı inovasyon yapın ve uygulamalarınızı yeniden keşfedin.