AWS News Blog
New EC2 Instance Type – The Cluster GPU Instance

|
If you have a mid-range or high-end video card in your desktop PC, it probably contains a specialized processor called a GPU or Graphics Processing Unit. The instruction set and memory architecture of a GPU are designed to handle the types of operations needed to display complex graphics at high speed. The instruction sets typically include instructions for manipulating points in 2D or 3D space and for performing advanced types of calculations. The architecture of a GPU is also designed to handle long streams (usually known as vectors) of points with great efficiency. This takes the form of a deep pipeline and wide, high-bandwidth access to memory.
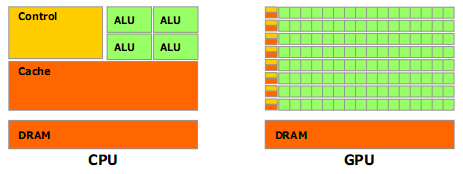 A few years ago advanced developers of numerical and scientific application started to use GPUs to perform general-purpose calculations, termed GPGPU, for General-Purpose computing on Graphics Processing Units. Application development continued to grow as the demands of many additional applications were met with advances in GPU technology, including high performance double precision floating point and ECC memory. However, accessibility to such high-end technology, particularly on HPC cluster infrastructure for tightly coupled applications, has been elusive for many developers. Today we are introducing our latest EC2 instance type (this makes eleven, if you are counting at home) called the Cluster GPU Instance. Now any AWS user can develop and run GPGPU on a cost-effective, pay-as-you-go basis.
A few years ago advanced developers of numerical and scientific application started to use GPUs to perform general-purpose calculations, termed GPGPU, for General-Purpose computing on Graphics Processing Units. Application development continued to grow as the demands of many additional applications were met with advances in GPU technology, including high performance double precision floating point and ECC memory. However, accessibility to such high-end technology, particularly on HPC cluster infrastructure for tightly coupled applications, has been elusive for many developers. Today we are introducing our latest EC2 instance type (this makes eleven, if you are counting at home) called the Cluster GPU Instance. Now any AWS user can develop and run GPGPU on a cost-effective, pay-as-you-go basis.
Similar to the Cluster Compute Instance type that we introduced earlier this year, the Cluster GPU Instance (cg1.4xlarge if you are using the EC2 APIs) has the following specs:
- A pair of NVIDIA Tesla M2050 “Fermi” GPUs.
- A pair of quad-core Intel “Nehalem” X5570 processors offering 33.5 ECUs (EC2 Compute Units).
- 22 GB of RAM.
- 1690 GB of local instance storage.
- 10 Gbps Ethernet, with the ability to create low latency, full bisection bandwidth HPC clusters.
Each of the Tesla M2050s contains 448 cores and 3 GB of ECC RAM and are designed to deliver up to 515 gigaflops of double-precision performance when pushed to the limit. Since each instance contains a pair of these processors, you can get slightly more than a trillion FLOPS per Cluster GPU instance. With the ability to cluster these instances over 10Gbps Ethernet, the compute power delivered for highly data parallel HPC, rendering, and media processing applications is staggering. I like to think of it as a nuclear-powered bulldozer that’s about 1000 feet wide that you can use for just $2.10 per hour!
Each AWS account can use up to 8 Cluster GPU instances by default with more accessible by contacting us. Similar to Cluster Compute instances, this default setting exists to help us understand your needs for the technology early on and is not a technology limitation. For example, we have now removed this default setting on Cluster Compute instances and have long had users running clusters up through and above 128 nodes as well as running multiple clusters at once at varied scale.
You’ll need to develop or leverage some specialized code in order to achieve optimal GPU performance, of course. The Tesla GPUs implements the CUDA architecture. After installing the latest NVIDIA driver on your instance, you can make use of the Tesla GPUs in a number of different ways:

- You can write directly to the low-level CUDA Driver API.
- You can use higher-level functions in the C Runtime for CUDA.
- You can use existing higher-level languages such as FORTRAN, Python, C, C++, Java, or Ruby.
- You can use CUDA versions of well-established packages such as CUBLAS (BLAS), CUFFT (FFT), and LAPACK.
- You can build new applications in OpenCL (Open Compute Language), a new cross-vendor standard for heterogeneous computing.
- You can run existing applications that have been adapted to make use of CUDA.
Elastic MapReduce can now take advantage of the Cluster Compute and Cluster GPU instances, giving you the ability to combine Hadoop’s massively parallel processing architecture with high performance computing. You can focus on your application and Elastic MapReduce will handle workload parallelization, node configuration, scaling, and cluster management.
Here are some resources to help you to learn more about GPUs and GPU programming:
- NVIDIA GPU Computing Developer Home Page.
- CUDA Toolkit Download.
- CUDA By Example, published earlier this year.
- Programming Massively Parallel Processors, also published this year.
- The gpgpu.org site has a lot of interesting articles.
–Jeff;