AWS News Blog
New P2 Instance Type for Amazon EC2 – Up to 16 GPUs

|
I like to watch long-term technology and business trends and watch as they shape the products and services that I get to use and to write about. As I was preparing to write today’s post, three such trends came to mind:
- Moore’s Law – Coined in 1965, Moore’s Law postulates that the number of transistors on a chip doubles every year.
- Mass Market / Mass Production – Because all of the technologies that we produce, use, and enjoy every day consume vast numbers of chips, there’s a huge market for them.
- Specialization – Due to the previous trend, even niche markets can be large enough to be addressed by purpose-built products.
As the industry pushes forward in accord with these trends, a couple of interesting challenges have surfaced over the past decade or so. Again, here’s a quick list (yes, I do think in bullet points):
- Speed of Light – Even as transistor density increases, the speed of light imposes scaling limits (as computer pioneer Grace Hopper liked to point out, electricity can travel slightly less than 1 foot in a nanosecond).
- Semiconductor Physics – Fundamental limits in the switching time (on/off) of a transistor ultimately determine the minimum achievable cycle time for a CPU.
- Memory Bottlenecks – The well-known von Neumann Bottleneck imposes limits on the value of additional CPU power.
 The GPU (Graphics Processing Unit) was born of these trends, and addresses many of the challenges! Processors have reached the upper bound on clock rates, but Moore’s Law gives designers more and more transistors to work with. Those transistors can be used to add more cache and more memory to a traditional architecture, but the von Neumann Bottleneck limits the value of doing so. On the other hand, we now have large markets for specialized hardware (gaming comes to mind as one of the early drivers for GPU consumption). Putting all of this together, the GPU scales out (more processors and parallel banks of memory) instead of up (faster processors and bottlenecked memory). Net-net: the GPU is an effective way to use lots of transistors to provide massive amounts of compute power!
The GPU (Graphics Processing Unit) was born of these trends, and addresses many of the challenges! Processors have reached the upper bound on clock rates, but Moore’s Law gives designers more and more transistors to work with. Those transistors can be used to add more cache and more memory to a traditional architecture, but the von Neumann Bottleneck limits the value of doing so. On the other hand, we now have large markets for specialized hardware (gaming comes to mind as one of the early drivers for GPU consumption). Putting all of this together, the GPU scales out (more processors and parallel banks of memory) instead of up (faster processors and bottlenecked memory). Net-net: the GPU is an effective way to use lots of transistors to provide massive amounts of compute power!
With all of this as background, I would like to tell you about the newest EC2 instance type, the P2. These instances were designed to chew through tough, large-scale machine learning, deep learning, computational fluid dynamics (CFD), seismic analysis, molecular modeling, genomics, and computational finance workloads.
New P2 Instance Type
This new instance type incorporates up to 8 NVIDIA Tesla K80 Accelerators, each running a pair of NVIDIA GK210 GPUs. Each GPU provides 12 GiB of memory (accessible via 240 GB/second of memory bandwidth), and 2,496 parallel processing cores. They also include ECC memory protection, allowing them to fix single-bit errors and to detect double-bit errors. The combination of ECC memory protection and double precision floating point operations makes these instances a great fit for all of the workloads that I mentioned above.
Here are the instance specs:
| Instance Name | GPU Count | vCPU Count | Memory | Parallel Processing Cores
|
GPU Memory
|
Network Performance
|
| p2.xlarge | 1 | 4 | 61 GiB | 2,496 | 12 GiB | High |
| p2.8xlarge | 8 | 32 | 488 GiB | 19,968 | 96 GiB | 10 Gigabit |
| p2.16xlarge | 16 | 64 | 732 GiB | 39,936 | 192 GiB | 20 Gigabit |
All of the instances are powered by an AWS-Specific version of Intel’s Broadwell processor, running at 2.7 GHz. The p2.16xlarge gives you control over C-states and P-states, and can turbo boost up to 3.0 GHz when running on 1 or 2 cores.
The GPUs support CUDA 7.5 and above, OpenCL 1.2, and the GPU Compute APIs. The GPUs on the p2.8xlarge and the p2.16xlarge are connected via a common PCI fabric. This allows for low-latency, peer to peer GPU to GPU transfers.
All of the instances make use of our new Enhanced Network Adapter (ENA – read Elastic Network Adapter – High Performance Network Interface for Amazon EC2 to learn more) and can, per the table above, support up to 20 Gbps of low-latency networking when used within a Placement Group.
Having a powerful multi-vCPU processor and multiple, well-connected GPUs on a single instance, along with low-latency access to other instances with the same features creates a very impressive hierarchy for scale-out processing:
- One vCPU
- Multiple vCPUs
- One GPU
- Multiple GPUs in an instance
- Multiple GPUs in multiple instances within a Placement Group
P2 instances are VPC only, require the use of 64-bit, HVM-style, EBS-backed AMIs, and you can launch them today in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) regions as On-Demand Instances, Spot Instances, Reserved Instances, or Dedicated Hosts.
Here’s how I installed the NVIDIA drivers and the CUDA toolkit on my P2 instance, after first creating, formatting, attaching, and mounting (to /ebs) an EBS volume that had enough room for the CUDA toolkit and the associated samples (10 GiB is more than enough):
$ cd /ebs
$ sudo yum update -y
$ sudo yum groupinstall -y "Development tools"
$ sudo yum install -y kernel-devel-`uname -r`
$ wget http://us.download.nvidia.com/XFree86/Linux-x86_64/352.99/NVIDIA-Linux-x86_64-352.99.run
$ wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
$ chmod +x NVIDIA-Linux-x86_64-352.99.run
$ sudo ./NVIDIA-Linux-x86_64-352.99.run
$ chmod +x cuda_7.5.18_linux.run
$ sudo ./cuda_7.5.18_linux.run # Don't install driver, just install CUDA and sample
$ sudo nvidia-smi -pm 1
$ sudo nvidia-smi -acp 0
$ sudo nvidia-smi --auto-boost-permission=0
$ sudo nvidia-smi -ac 2505,875
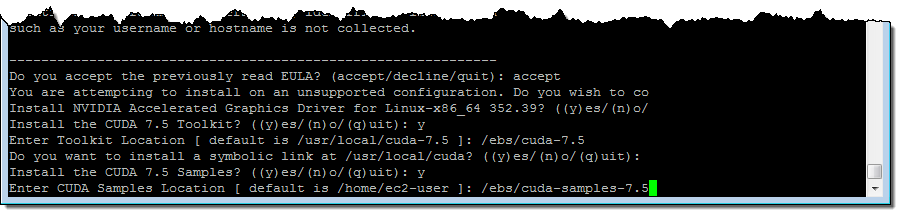
Note that NVIDIA-Linux-x86_64-352.99.run and cuda_7.5.18_linux.run are interactive programs; you need to accept the license agreements, choose some options, and enter some paths. Here’s how I set up the CUDA toolkit and the samples when I ran cuda_7.5.18_linux.run:
P2 and OpenCL in Action
With everything set up, I took this Gist and compiled it on a p2.8xlarge instance:
[ec2-user@ip-10-0-0-242 ~]$ gcc test.c -I /usr/local/cuda/include/ -L /usr/local/cuda-7.5/lib64/ -lOpenCL -o testHere’s what it reported:
[ec2-user@ip-10-0-0-242 ~]$ ./test
1. Device: Tesla K80
1.1 Hardware version: OpenCL 1.2 CUDA
1.2 Software version: 352.99
1.3 OpenCL C version: OpenCL C 1.2
1.4 Parallel compute units: 13
2. Device: Tesla K80
2.1 Hardware version: OpenCL 1.2 CUDA
2.2 Software version: 352.99
2.3 OpenCL C version: OpenCL C 1.2
2.4 Parallel compute units: 13
3. Device: Tesla K80
3.1 Hardware version: OpenCL 1.2 CUDA
3.2 Software version: 352.99
3.3 OpenCL C version: OpenCL C 1.2
3.4 Parallel compute units: 13
4. Device: Tesla K80
4.1 Hardware version: OpenCL 1.2 CUDA
4.2 Software version: 352.99
4.3 OpenCL C version: OpenCL C 1.2
4.4 Parallel compute units: 13
5. Device: Tesla K80
5.1 Hardware version: OpenCL 1.2 CUDA
5.2 Software version: 352.99
5.3 OpenCL C version: OpenCL C 1.2
5.4 Parallel compute units: 13
6. Device: Tesla K80
6.1 Hardware version: OpenCL 1.2 CUDA
6.2 Software version: 352.99
6.3 OpenCL C version: OpenCL C 1.2
6.4 Parallel compute units: 13
7. Device: Tesla K80
7.1 Hardware version: OpenCL 1.2 CUDA
7.2 Software version: 352.99
7.3 OpenCL C version: OpenCL C 1.2
7.4 Parallel compute units: 13
8. Device: Tesla K80
8.1 Hardware version: OpenCL 1.2 CUDA
8.2 Software version: 352.99
8.3 OpenCL C version: OpenCL C 1.2
8.4 Parallel compute units: 13
As you can see, I have a ridiculous amount of compute power available at my fingertips!
New Deep Learning AMI
As I said at the beginning, these instances are a great fit for machine learning, deep learning, computational fluid dynamics (CFD), seismic analysis, molecular modeling, genomics, and computational finance workloads.
In order to help you to make great use of one or more P2 instances, we are launching a Deep Learning AMI today. Deep learning has the potential to generate predictions (also known as scores or inferences) that are more reliable than those produced by less sophisticated machine learning, at the cost of a most complex and more computationally intensive training process. Fortunately, the newest generations of deep learning tools are able to distribute the training work across multiple GPUs on a single instance as well as across multiple instances each containing multiple GPUs.
The new AMI contains the following frameworks, each installed, configured, and tested against the popular MNIST database:
MXNet – This is a flexible, portable, and efficient library for deep learning. It supports declarative and imperative programming models across a wide variety of programming languages including C++, Python, R, Scala, Julia, Matlab, and JavaScript.
Caffe – This deep learning framework was designed with expression, speed, and modularity in mind. It was developed at the Berkeley Vision and Learning Center (BVLC) with assistance from many community contributors.
Theano – This Python library allows you define, optimize, and evaluate mathematical expressions that involve multi-dimensional arrays.
TensorFlow™ – This is an open source library for numerical calculation using data flow graphs (each node in the graph represents a mathematical operation; each edge represents multidimensional data communicated between them).
Torch – This is a GPU-oriented scientific computing framework with support for machine learning algorithms, all accessible via LuaJIT.
Consult the README file in ~ec2-user/src to learn more about these frameworks.
AMIs from NVIDIA
You may also find the following AMIs to be of interest:
- Windows Server 2012 with the NVIDIA Driver.
- NVIDIA CUDA Toolkit 7.5 on Amazon Linux.
- NVIDIA DIGITS 4 on Ubuntu 14.04.
— Jeff;