AWS Partner Network (APN) Blog
Building Serverless Data Pipelines on Amazon Redshift By Writing SQL with Datacoral
By Raghu Murthy, CEO and Founder at Datacoral
 |
 |
 |
Amazon Redshift is a powerful yet affordable data warehouse, and while getting data out of Redshift is easy, getting data into and around Redshift can pose problems as the warehouse grows.
Data ingestion issues start to emerge when organizations outgrow the COPY command that imports CSV files from Amazon Simple Storage Service (Amazon S3) buckets. And, of course, these issues take shape at the worst possible time—when the warehouse becomes popular with analysts and data scientists as they increase demand for more data, sources, and targets.
When this happens, data engineers jump forward with myriad solutions that can be built. Complex data pipelines are constructed from a combination of Amazon Web Services (AWS) and open source tools, and for a few weeks it all works fine.
Then, in order to satisfy increasing requests for changes, new sources, and fixes to what’s been built, your data engineer may start asking for more resources than your data science team has to offer.
This is when you realize you are the proud owner of a brittle, complicated data infrastructure that no one can maintain—not even its architect.
As the CEO and Founder of Datacoral, a company that automates data pipelines for resource-starved organizations to make data scientists self-sufficient, I have actually seen this happen to my customers. In fact, I was one of those data engineers, too, working for more than 15 years on data infrastructure and distributed systems at 21st-century unicorns Yahoo! and Facebook.
While Datacoral, an AWS Partner Network (APN) Advanced Technology Partner, handles both direct connections to cloud sources and data ingestions into Redshift, its real power is in managing metadata changes, data transformations, and orchestrating pipelines for data consumers.
If you are a data scientist, you’re probably wondering why (or have accepted the fact that) it takes a long time to create and manage data pipelines. You work on plumbing rather than the business logic applied to the data itself.
In this post, I will present an option where you can just write SQL (Redshift SQL) to represent data flow. Then I’ll describe how serverless data pipelines get automatically generated for that data flow. You will have full visibility into the freshness of the data in each of the tables in the data flow, and have a clear understanding of the provenance of each of the tables in the data flow.
Data Pipeline Help for Data Scientists Working in Redshift
Data scientists typically find the time it takes to hand-code data pipelines to manage transformations of data will overshadow the time they spend working on the transformations themselves.
I like Amazon Redshift because it’s a powerful SQL database. Redshift’s columnar architecture makes it really well suited for ad-hoc business intelligence queries, but most of its use cases involve old-century extract, transform, load (ETL) processing of data prior to loading it into Redshift for ad-hoc analysis. Fortunately for us, we have found Redshift is a good solution to build ELT pipelines on structured data.
To begin, Datacoral’s data infrastructure-as-a-service (IaaS) includes more than 70 connectors to pull data from different sources, as well as publish the data once it has been transformed. We’ve built a connector framework and software developer kit (SDK) to expedite creation and support for more of them, and we turn out new connectors with each bi-monthly update to our platform.
These connectors operate in a batch processing model where new batches of data are received or pulled every so often. Customers use Datacoral’s Data Programming Language (DPL), an extended SQL-based language, to ingest data from different sources into Redshift raw tables.
Once the raw table is populated, Datacoral allows you to write SQL queries to build a pipeline of transformations over them, resulting in user-ready materialized views. Users can also publish data from Redshift back into production databases, and tools like Salesforce, also writing DPL.
In production, Datacoral’s platform automatically generates a serverless data pipeline which can ingest data from different sources, convert the Redshift views into tables, and keep those tables up-to-date whenever the raw data tables are updated. We handle changes, impact analysis, data provenance, and pipeline orchestration automatically.
Ultimately, Datacoral also publishes data from Redshift into tools and databases, creating a fully managed, end-to-end automated data pipeline infrastructure. Our customers, who are mostly data-driven startups like us, think this saves them 2-3 years of time, annually.
Example of a Data Pipeline
To set the stage for our example, the goal of this post will be to calculate an up-to-date customer health score so that our data scientists can work to better predict troubled customers and alert our account management team.
Our data will come from the following serverless microservices, called slices, that collect data from production systems:
- webevents: batched every 30 minutes
- deviceevents: batched every 30 minutes
- zendesk: brought in every hour
- billing: billing data from a MySQL database brought in every two hours
A set of queries on raw tables like the ones in the boxes below automatically generate a pipeline that creates an up-to-date customer_health table, with the health score for each customer based on the different signals about the customer behavior.
billingdb/lifetime_value.dpl
zendesk/satisfaction.dpl
events/engagement.dpl
public/customer_health.dpl
Datacoral would then compile these queries into a Directed Acyclic Graph (DAG) of dependencies, as shown below.
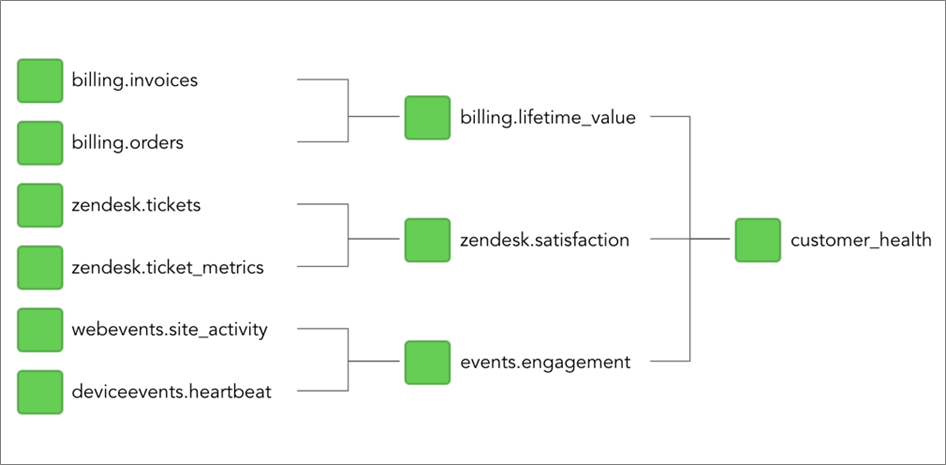
Figure 1 – Directed, acyclic graph (DAG) of dependencies defines each stage in the data pipeline.
In addition to the schema-based DAG, Datacoral also figures out how to synchronize the execution of the queries based on the size of the batch that each query is processing. For example, since customer_health needs to be updated every four hours, Datacoral automatically determines that interval before the customer_health query runs.
Datacoral compiles the set of queries into a serverless pipeline with the proper dependencies automatically assigned.
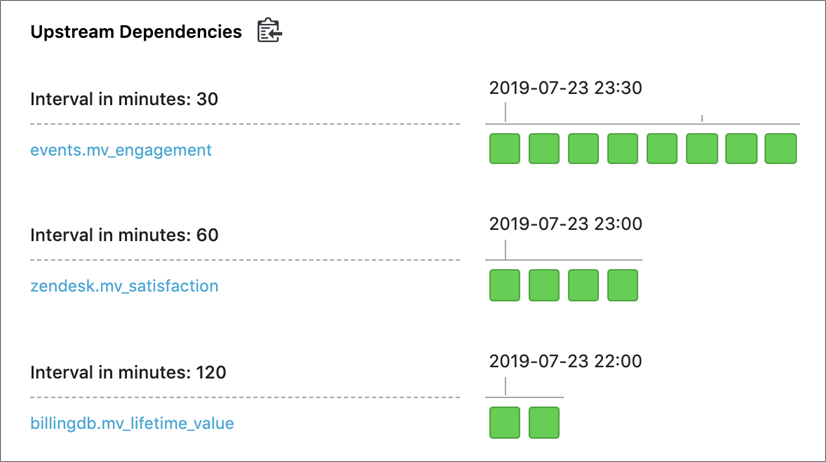
Figure 2 – Query execution happens at regular intervals in micro-batches, each of which receives its own time label.
Once the pipeline is running, Datacoral’s monitoring interface can be used to see the progress of the queries. Schema-level lineage is automatically inferred.
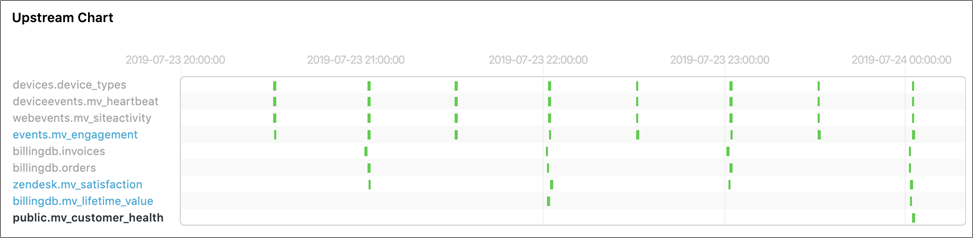
Figure 3 – Each query builds a materialized view at each time interval when its upstream predecessor succeeds.
In addition to providing an automated way of building a pipeline with just SQL, Datacoral offers a unique “compile step” to the pipeline that checks the integrity of the pipeline. Each query result’s schema forms the data interface for the downstream queries. When you modify any of the queries in the DAG, Datacoral checks if the change can break any of the downstream queries.
This is similar to a situation where a compiler errors out when you change the signature of a function and don’t change all the call-sites of the function in other parts of the code. You can then make several changes into one consistent update-set. This update-set can be applied to the DAG with a guarantee there will not be any breakages in the data flow due to schema changes.
Figure 4 – Datacoral publishes data to analytic, ml, or operational systems like this Salesforce dashboard.
To complete the loop, Datacoral offers the ability to publish data to AWS-based and third-party systems so they, too, may harness the results of the transformations.
In this example, we can set the final stage of this data pipeline to include an update to Salesforce to update the customer_health_score in the account object in the CRM system. The ability to publish data to systems, analytic tools, and warehouses such as an Amazon Athena-accessible data lake completes the example of an end-to-end, serverless data pipeline from Datacoral.
Conclusion
In this post, I have shown how a data scientist can create an end-to-end pipeline that consolidates data from accounting, customer support, and marketing systems. I’ve presented materialized views to Amazon Redshift users, and updated the customer health score in Salesforce.
All of this was accomplished by just writing SQL queries, and the advantages of this approach include:
- Not having to worry about programming orchestration logic.
- Compile step to allow for changes to be made in a consistent manner.
- Impact analysis of upstream and downstream schema changes with an illustrated dependency graph.
- Legible, maintainable transformation pipeline because it’s SQL.
- Data flows that take less than an hour to create, update, or maintain, and expedites future analytic and data science experiments and implementations.
One Last Thing: Security!
If this all sounds too good to be true, there is one last thing I failed to mention—security.
We designed Datacoral as a serverless data infrastructure service that runs in your Amazon Virtual Private Cloud (VPC), not ours. In fact, all of our in-transit activities are secured with your account keys.
While we do have access to this network through a datacoral_user account, that is again secured with your keys, not ours. We use that account to make sure your data pipelines are running, without seeing the data values themselves. Only you see and manipulate your data, not us, so we are able to support environments that carry sensitive data.
For more information, visit us at datacoral.com and ask for a demo or a data pipeline assessment.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

Datacoral – APN Partner Spotlight
Datacoral is an APN Advanced Technology Partner and serverless data platform that runs securely in your Amazon VPC. Datacoral offers a full data infrastructure stack to collect, organize, and harness data, so you focus on delivering value through insights and models rather than pipeline orchestration.
Contact Datacoral | Solution Overview | AWS Marketplace
*Already worked with Datacoral? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.