AWS Partner Network (APN) Blog
Storing Multi-Tenant SaaS Data in a Serverless Environment with Amazon Keyspaces
By Tod Golding, Principal Partner Solutions Architect, AWS SaaS Factory
By Muhammad Sadiqain Tahir, Contributing Writer
With the introduction of Amazon Keyspaces (for Apache Cassandra), AWS has enabled software-as-a-service (SaaS) providers to run their Cassandra workloads using a fully managed, serverless offering.
This managed option allows you to leverage the strengths of Cassandra while still getting all the scale, cost, reliability, and operational efficiency that comes with a managed model.
The serverless nature of Amazon Keyspaces is compelling for SaaS providers, allowing them to better align consumption of resources with the activity trends of their tenants. This allows providers to avoid over-provisioning storage resources while still supporting the unpredictable loads that are often associated with multi-tenant SaaS offerings.
In this post, we’ll look at how Amazon Keyspaces can be used to store data in a multi-tenant architecture. We’ll review the common models for partitioning each tenant’s data and highlight operational, agility, and security implications of these approaches.
The Amazon Keyspaces Landscape
Before we get into the details of multi-tenancy, let’s start by looking at some of the fundamentals of the Amazon Keyspaces storage model.
Amazon Keyspaces represents a scalable, highly available, serverless data store compatible with Apache Cassandra. Figure 1 provides a conceptual view of the serverless nature of Amazon Keyspaces.

Figure 1 – The serverless Amazon Keyspaces experience.
One of the goals of the Amazon Keyspaces model is to make the transition to a serverless model as seamless as possible. Supporting this mindset, Amazon Keyspaces relies on a Cassandra driver to interact with the service.
As you can see from the diagram above, the only change here is that you must configure the service endpoint that will be referenced by the driver. Once the driver is configured, your interactions with Amazon Keyspaces will mostly align with the traditional experience you’d have with a Cassandra driver.
As part of thinking about introducing multi-tenancy into an Amazon Keyspaces environment, you need to have a good grasp of the Amazon Keyspaces storage constructs. The diagram in Figure 2 provides a conceptual view of the fundamental storage concepts that are part of Amazon Keyspaces model.
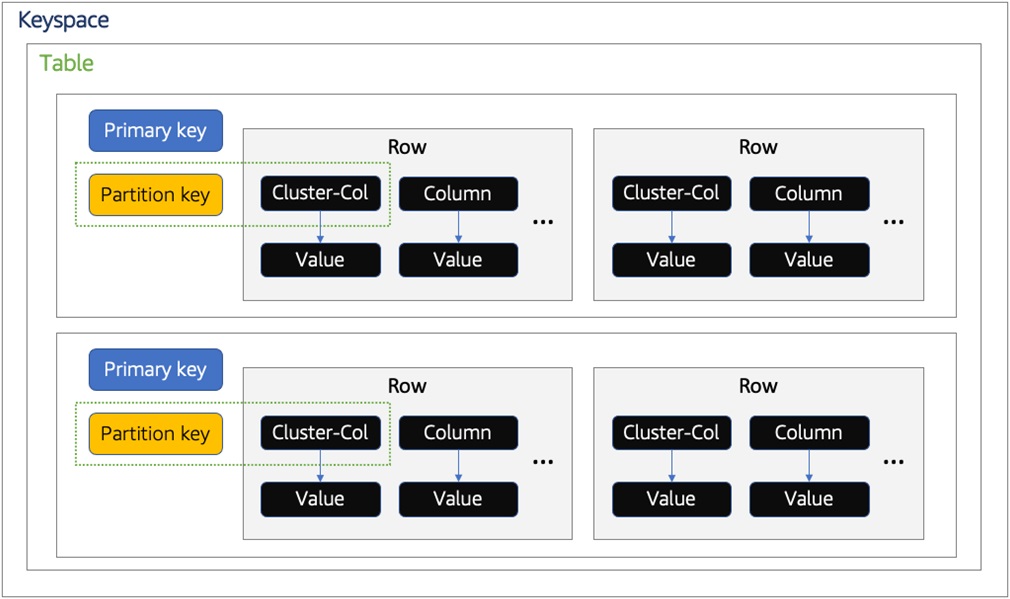
Figure 2 – Amazon Keyspaces storage model.
If we start at the outermost view of this model, you’ll see we have the notion of a keyspace. In many respects, a keyspace is analogous to a schema in a relational database. It provides a logical grouping of related tables in a cluster. A keyspace may contain one or more tables that house data within rows.
Within a table there are partition keys, which are used to logically group data within your tables. Rows also include one or more clustering columns that determine how rows are sorted within a partition.
Finally, a primary key represents the combination of Partition Key and Clustering columns to uniquely identify a row within a partition.
Amazon Keyspaces stores its data as key-value pairs in columns grouped in rows. Each row in a keyspace is treated as a first-class citizen. These rows are stored in their respective partitions determined by the partition keys, categorized in tables, and uniquely identified by primary keys. You can view each row as mapping to a “record” and each column as mapping to a “field” in a table.
A key differentiator of Amazon Keyspaces compared to Apache Cassandra is its ability to support wide partitions. Apache Cassandra has a partition size recommendation under 100 MB. Amazon Keyspaces does not suffer from this limitation because it stores partitions on multiple disks, allowing the partitions to grow in a virtually unbounded way.
Amazon Keyspaces in Multi-Tenant Environments
When we look at storing multi-tenant data in any database, we have to think about how we may want to partition the tenant data. The approach you choose will vary based on the compliance, noisy neighbor, and isolation needs of the data.
For Amazon Keyspaces, there are two different approaches you’ll want to consider when thinking about how best to map the needs of your application to the underlying representation of the data. The two main models we’ll explore are:
- Silo Model – With the silo storage model, we store tenant data in distinct storage constructs that are associated with individual tenants. Our system must map each tenant to their Amazon Keyspaces storage.
- Pooled Model – This approach comingles the data for tenants using shared resources. By placing the data in a single construct, you may get better economies of scale and reduce the overall complexity of your operational footprint.
It’s important to note these two models are not mutually exclusive. In some SaaS systems, we see scenarios where an application may support both models. There are a number of factors that may influence your selection of a silo or pool model.
Tiering, for example, can influence the silo vs. pool strategy. You may choose to offer an entirely siloed Amazon Keyspaces storage to your premium tenants while using pooled for entry-level tenant. Performance and compliance considerations could also lead to silo and pool strategies varying for each microservice in your system.
For more information on these models, you may want to look at whitepapers on data partitioning and tenant isolation.
Silo Model
Implementing the silo model in Amazon Keyspaces is achieved by provisioning a separate keyspace for each tenant. By placing tenant data in an individual keyspace, the silo model makes it simpler to isolate tenant data.
Additionally, this model helps limit noisy neighbors where one tenant may be imposing a load that could adversely impact the experience of other tenants.
Figure 3 provides a conceptual view of the silo model realized in Amazon Keyspaces.
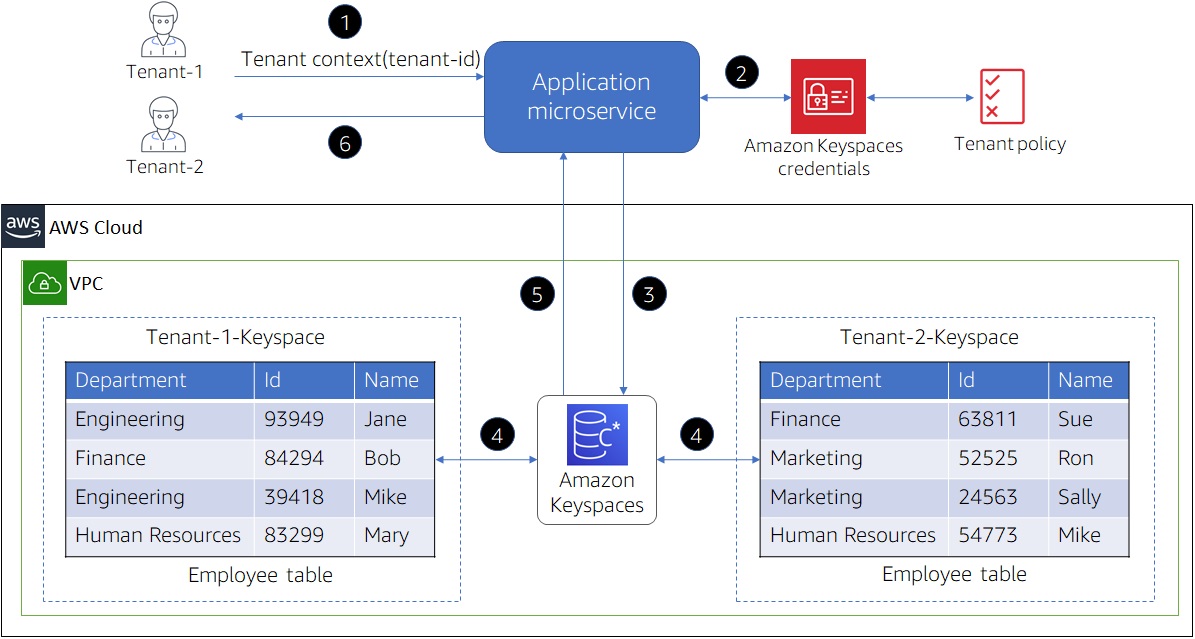
Figure 3 – Silo model in Amazon Keyspaces.
You’ll notice that our silo experience is achieved here by creating a separate keyspace for each tenant. To identify these keyspaces and map them to tenants, we have pre-pended a tenant identifier to each keyspace name.
This means the data access layer of your code will need to introduce a mechanism that resolves the current tenant request to a tenant’s keyspace name.
To get a better sense of the end-to-end experience, let’s examine each of the steps represented in the diagram above:
- A request is made to a microservice to acquire data. The request includes context of the current tenant.
- The microservice acquires tenant-specific credentials for Amazon Keyspaces. These credentials will have policies attached to restrict access to tenant specific keyspaces.
- The microservice sends the request to Amazon Keyspaces to perform the requested operation.
- If the tenant has the necessary permissions, Amazon Keyspaces performs the requested operation on the tables in the tenant’s keyspace.
- Either the result of the performed operation or an error is returned to the calling microservice.
- Finally, the results are sent back to the client.
Isolating Tenant Data in the Silo Model
With the silo model, AWS Identity and Access Management (IAM) policies are used to isolate the individual keyspaces that hold each tenant’s data. These policies prevent one tenant from accessing another tenant’s data.
Figure 4 shows a sample IAM policy used to isolate a tenant to their respective keyspace.
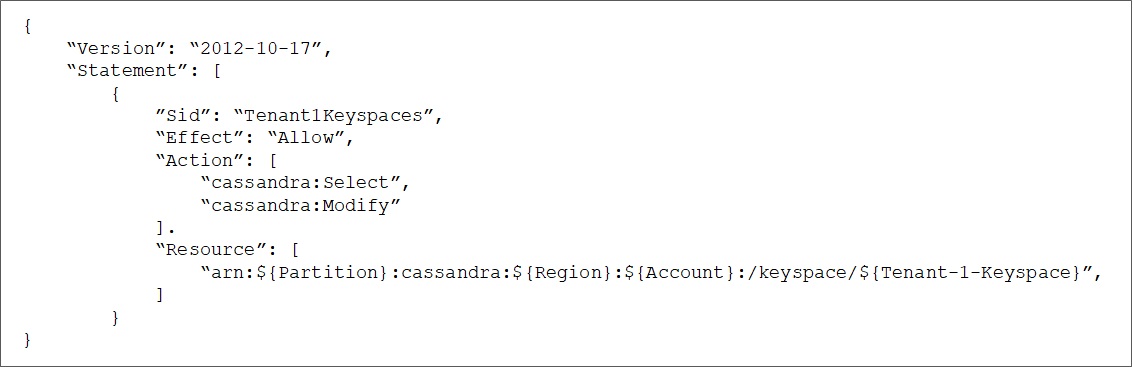
Figure 4 – IAM policy to restrict tenant access to keyspace.
With IAM identity-based policies, you can specify “allowed” or “denied” actions on the keyspace or tables within a keyspace. The “Action” element of an IAM policy describes the specific action or actions that are allowed or denied by the policy.
Actions in Amazon Keyspaces use the “cassandra” prefix before specifying the action. The example policy in Figure 4 restricts “Tenant-1” to only perform insert, update, and queries on the data stored in “Tenant-1-Keyspace” identified in the “Resource” element of IAM policy.
With this policy in effect, tenants are not allowed to create a new keyspace or modify settings on an existing keyspace.
Silo Considerations
While the siloed model’s compliance and performance are appealing, this approach can impact the agility of your SaaS environment. Having a separate keyspace for each tenant makes updates more challenging, as each tenant’s environment needs to be updated separately.
This is especially challenging when you’re rolling out features with schema changes that are not backward-compatible. The operational complexity alone can add significant overhead to the overall operational footprint of your SaaS environment.
In SaaS environments where tenants may be churning out of the system on a regular basis, you’ll want to think about how these tenants will be off-boarded from Amazon Keyspaces to free up resources.
Decommissioning can be done using one of the following strategies:
- Delete the tenant keyspace, which deletes all the data.
- Set the provisioned capacity to a small value for both reads and writes.
- Change the provisioned capacity to on-demand mode in cases where access is needed for administrative work.
Pool Model
The pool model looks very different than our silo. Here, our focus is on having all the data for tenants comingled in shared constructs. In Amazon Keyspaces, this is achieved by using shared tables within the same keyspace.
Figure 5 provides a conceptual view of how the pool model is realized within Amazon Keyspaces.
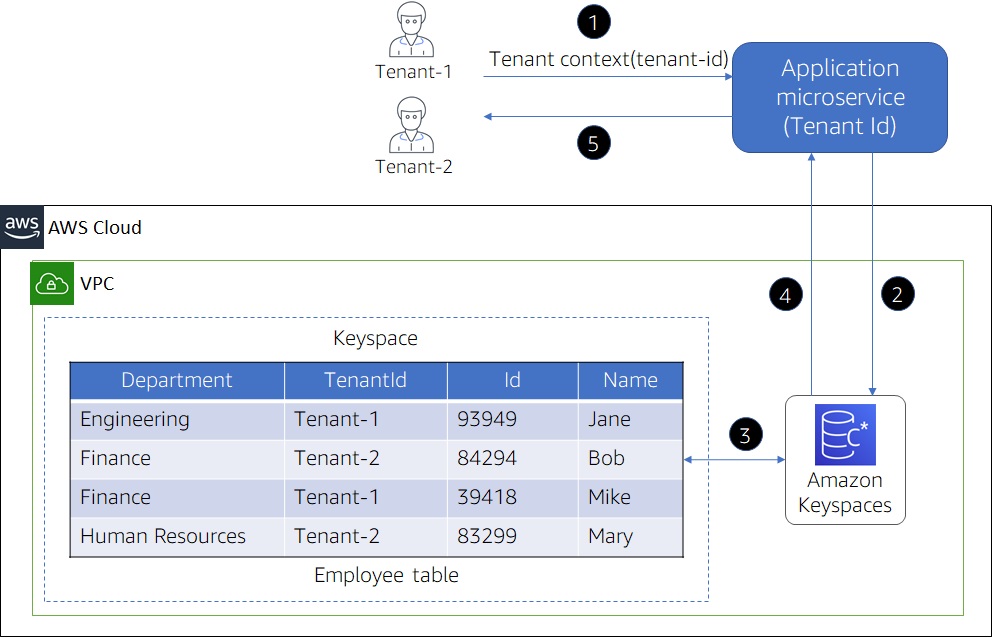
Figure 5 – Pool model in Amazon Keyspaces.
You’ll notice this model places all of our tenant data in a single table. There would also be additional tables in this keyspace that would hold different types of data that are part of our application (customers and orders, for example).
To support this comingling of data, we must add an additional clustering column to each table in the keyspace. This column stores the tenant-id, which identifies the data associated with each tenant. As your application accesses data, it will use the tenant-id to determine which items will be accessed for a given tenant.
To get a better sense of the end-to-end experience, let’s examine each of the steps represented in the preceding diagram.
- A request is sent to a microservice, passing the tenant-id in the request.
- The microservice sends the request to Amazon Keyspaces (including tenant-id) to scope the requested operation.
- Amazon Keyspaces executes the request restricting the results based on the scoping criteria.
- The result of the performed operation is returned to the microservice.
- Finally, the results are sent back to the client.
Tenant Isolation in a Pool Model
Tenant isolation is more challenging to implement in the pooled model. As of this writing, Amazon Keyspaces does not include support for a row-level isolation model that could be used to restrict access to individual rows.
Since there’s no out-of-the-box solution for row-level access control, developers need to introduce their own application libraries/policies to enforce tenant isolation boundaries.
The steps to acquire Amazon Keyspaces credentials and injecting tenant context in queries should be encapsulated within a Data Access Layer (DAL). This relieves developers from worrying about the internals of tenant isolation strategy and inadvertently making a mistake that breaches tenant boundaries.
Scaling the Pooled Model
While the pool model simplifies aspects of your application’s operational, it can also add complexity to the scaling profile of your solution. By placing all of your data into shared construct, you must now consider how/if that representation of the data could create a noisy neighbor condition.
To address this concern, you’ll want to introduce a scaling policy to address the continually changing tenant loads in your environment. Amazon Keyspaces offers different scaling policies depending on the read or write capacity modes.
One approach to solving the noisy neighbor problem is to use Amazon Keyspaces’ on-demand capacity mode. This mode will allow Amazon Keyspaces to align capacity with the fluctuating workloads of tenants. As the workloads of your system hit new peaks, the service will increase throughput capacity for your table to meet the needs of your tenant loads.
Another option would be provisioned mode, which is more flexible because it enables you to optimize the price of reads and writes by setting the min and max upfront. Provisioned capacity employs auto scaling by specifying the minimum capacity units, maximum capacity units, and target utilization percentage.
To understand this model, let’s look at a scenario where the current tenant load is 1,000 RCU (Read Capacity Units) and 1,000 WCU (Write Capacity Units), and target utilization is set to 50 percent. If we have this configuration and traffic exceeds 500 capacity units for a sustained period, the system will auto scale to increase the throughput capacity of the table.
Short bursts, however, are accommodated by the table’s built-in burst capacity. If tenant traffic builds up quickly, set the target utilization to lower values. However, if traffic increases gradually, use a higher target utilization percentage to lower cost.
Quota Considerations
There are a few quotas in place you need to be aware of when using Amazon Keyspaces in either silo or pool models.
In the silo model, you’ll want to consider how your keyspace per tenant architecture is influenced by account limits. For example, the soft limit for keyspaces within an account is 256, and the number of tables within each keyspace also has a soft limit of 256.
Even though you can always have these limits increased, it’s imperative to factor those limits into the overall architectural model and ensure tenant profiles won’t run up against them.
In a pooled model, if you have adopted a provisioned scalability strategy, be aware the maximum number of RCUs is 80,000 and the maximum number of WCU is 80,000 allocated for the account per region. In on-demand mode, the maximum read throughput per second is 40,000 read request units (RRUs), whereas the maximum write throughput per second is 40,000 write request units (WRUs) per table per region.
Conclusion
By taking advantage of the serverless nature of Amazon Keyspaces, SaaS providers can enhance the operational and agility footprint of their SaaS environments.
Amazon Keyspaces equips you with a collection of mechanisms that allow you to create an experience that aligns the consumption of tenant resources with actual tenant activity. The net effect of this is often reflected in lowered costs.
Amazon Keyspaces also enables SaaS organizations to make substantial gains in business agility. By reducing the overall management and operations overhead of our solution, you are able to focus more of your time and resources on your customers and the differentiating features of your product.

About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.