AWS Architecture Blog
Identification of replication bottlenecks when using AWS Application Migration Service
Enterprises frequently begin their journey by re-hosting (lift-and-shift) their on-premises workloads into AWS and running Amazon Elastic Compute Cloud (Amazon EC2) instances. A simpler way to re-host is by using AWS Application Migration Service (Application Migration Service), a cloud-native migration service.
To streamline and expedite migrations, automate reusable migration patterns that work for a wide range of applications. Application Migration Service is the recommended migration service to lift-and-shift your applications to AWS.
In this blog post, we explore key variables that contribute to server replication speed when using Application Migration Service. We will also look at tests you can run to identify these bottlenecks and, where appropriate, include remediation steps.
Overview of migration using Application Migration Service
Figure 1 depicts the end-to-end data replication flow from source servers to a target machine hosted on AWS. The diagram is designed to help visualize potential bottlenecks within the data flow, which are denoted by a black diamond.
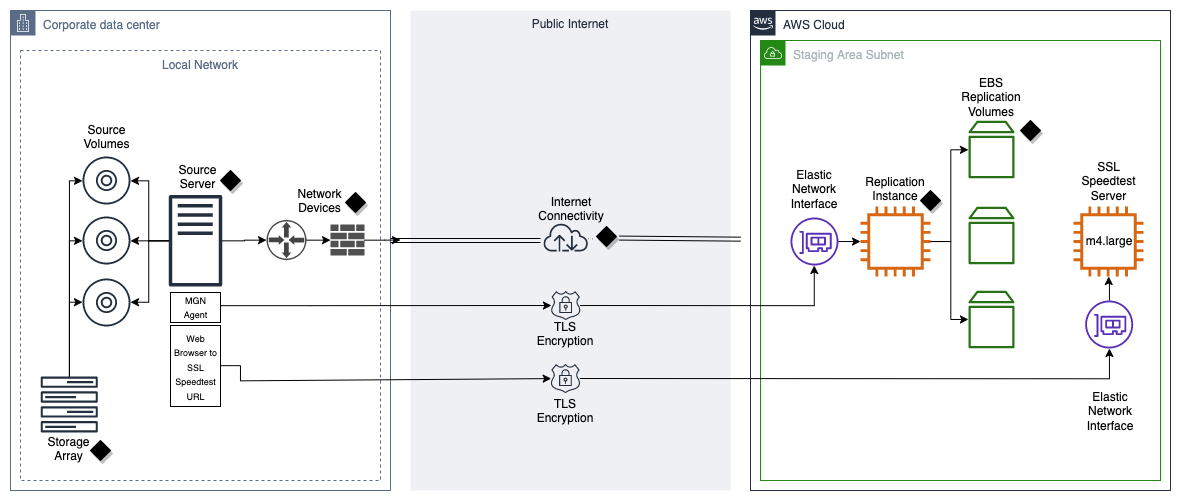
Figure 1. Data flow when using AWS Application Migration Service (black diamonds denote potential points of contention)
Baseline testing
To determine a baseline replication speed, we recommend performing a control test between your target AWS Region and the nearest Region to your source workloads. For example, if your source workloads are in a data center in Rome and your target Region is Paris, run a test between eu-south-1 (Milan) and eu-west-3 (Paris). This will give a theoretical upper bandwidth limit, as replication will occur over the AWS backbone. If the target Region is already the closest Region to your source workloads, run the test from within the same Region.
Network connectivity
There are several ways to establish connectivity between your on-premises location and AWS Region:
- Public internet
- VPN
- AWS Direct Connect
This section pertains to options 1 and 2. If facing replication speed issues, the first place to look is at network bandwidth. From a source machine within your internal network, run a speed test to calculate your bandwidth out to the internet; common test providers include Cloudflare, Ookla, and Google. This is your bandwidth to the internet, not to AWS.
Next, to confirm the data flow from within your data center, run a traceroute (Windows) or tracert (Linux). Identify any network hops that are unusual or potentially throttling bandwidth (due to hardware limitations or configuration).
To measure the maximum bandwidth between your data center and the AWS subnet that is being used for data replication, while accounting for Security Sockets Layer (SSL) encapsulation, use the CloudEndure SSL bandwidth tool (refer to Figure 1).
Source storage I/O
The next area to look for replication bottlenecks is source storage. The underlying storage for servers can be a point of contention. If the storage is maxing-out its read speeds, this will impact the data-replication rate. If your storage I/O is heavily utilized, it can impact block replication by Application Migration Service. In order to measure storage speeds, you can use the following tools:
- Windows: WinSat (or other third-party tooling, like AS SSD Benchmark)
- Linux: hdparm
We suggest reducing read/write operations on your source storage when starting your migration using Application Migration Service.
Application Migration Service EC2 replication instance size
The size of the EC2 replication server instance can also have an impact on the replication speed. Although it is recommended to keep the default instance size (t3.small), it can be increased if there are business requirements, like to speed up the initial data sync. Note: using a larger instance can lead to increased compute costs.

Common replication instance changes include:
- Servers with <26 disks: change the instance type to m5.large. Increase the instance type to m5.xlarge or higher, as needed.
- Servers with <26 disks (or servers in AWS Regions that do not support m5 instance types): change the instance type to m4.large. Increase to m4.xlarge or higher, as needed.
Note: Changing the replication server instance type will not affect data replication. Data replication will automatically pick up where it left off, using the new instance type you selected.
Application Migration Service Elastic Block Store replication volume
You can customize the Amazon Elastic Block Store (Amazon EBS) volume type used by each disk within each source server in that source server’s settings (change staging disk type).
By default, disks <500GiB use Magnetic HDD volumes. AWS best practice suggests not change the default Amazon EBS volume type, unless there is a business need for doing so. However, as we aim to speed up the replication, we actively change the default EBS volume type.
There are two options to choose from:
- The lower cost, Throughput Optimized HDD (st1) option utilizes slower, less expensive disks.

-
- Consider this option if you(r):
- Want to keep costs low
- Large disks do not change frequently
- Are not concerned with how long the initial sync process will take
- Consider this option if you(r):
- The faster, General Purpose SSD (gp2) option utilizes faster, but more expensive disks.

-
- Consider this option if you(r):
- Source server has disks with a high write rate, or if you need faster performance in general
- Want to speed up the initial sync process
- Are willing to pay more for speed
- Consider this option if you(r):
Source server CPU
The Application Migration Service agent that is installed on the source machine for data replication uses a single core in most cases (agent threads can be scheduled to multiple cores). If core utilization reaches a maximum, this can be a limitation for replication speed. In order to check the core utilization:
- Windows: Launch the Task Manger application within Windows, and click on the “CPU” tab. Right click on the CPU graph (this is currently showing an average of cores) > select “Change graph to” > “Logical processors”. This will show individual cores and their current utilization (Figure 2).
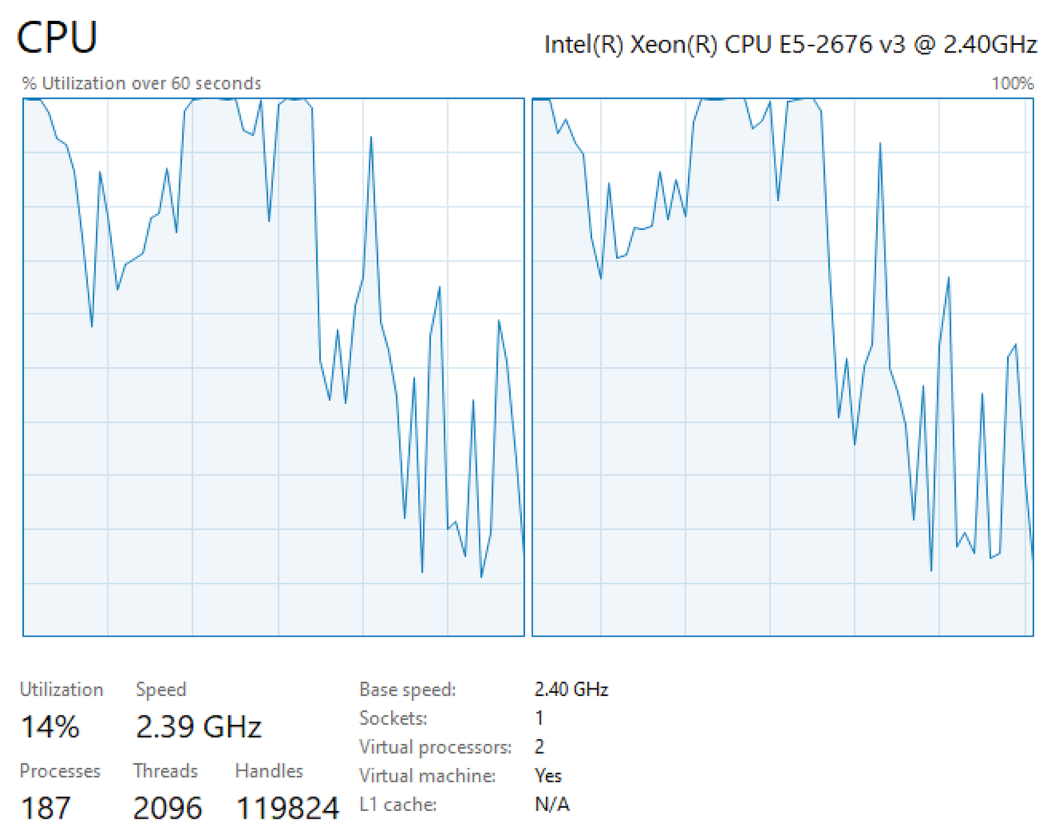
Figure 2. Logical processor CPU utilization
Linux: Install htop and run from the terminal. The htop command will display the Application Migration Service/CE process and indicate the CPU and memory utilization percentage (this is of the entire machine). You can check the CPU bars to determine if a CPU is being maxed-out (Figure 3).

Figure 3. AWS Application Migration Service/CE process to assess CPU utilization
Conclusion
In this post, we explored several key variables that contribute to server replication speed when using Application Migration Service. We encourage you to explore these key areas during your migration to determine if your replication speed can be optimized.