AWS News Blog
How CyberGRX cut ML processing time from 8 days to 56 minutes with AWS Step Functions Distributed Map

|
Last December, Sébastien Stormacq wrote about the availability of a distributed map state for AWS Step Functions, a new feature that allows you to orchestrate large-scale parallel workloads in the cloud. That’s when Charles Burton, a data systems engineer for a company called CyberGRX, found out about it and refactored his workflow, reducing the processing time for his machine learning (ML) processing job from 8 days to 56 minutes. Before, running the job required an engineer to constantly monitor it; now, it runs in less than an hour with no support needed. In addition, the new implementation with AWS Step Functions Distributed Map costs less than what it did originally.
What CyberGRX achieved with this solution is a perfect example of what serverless technologies embrace: letting the cloud do as much of the undifferentiated heavy lifting as possible so the engineers and data scientists have more time to focus on what’s important for the business. In this case, that means continuing to improve the model and the processes for one of the key offerings from CyberGRX, a cyber risk assessment of third parties using ML insights from its large and growing database.
What’s the business challenge?
CyberGRX shares third-party cyber risk (TPCRM) data with their customers. They predict, with high confidence, how a third-party company will respond to a risk assessment questionnaire. To do this, they have to run their predictive model on every company in their platform; they currently have predictive data on more than 225,000 companies. Whenever there’s a new company or the data changes for a company, they regenerate their predictive model by processing their entire dataset. Over time, CyberGRX data scientists improve the model or add new features to it, which also requires the model to be regenerated.
The challenge is running this job for 225,000 companies in a timely manner, with as few hands-on resources as possible. The job runs a set of operations for each company, and every company calculation is independent of other companies. This means that in the ideal case, every company can be processed at the same time. However, implementing such a massive parallelization is a challenging problem to solve.
First iteration
With that in mind, the company built their first iteration of the pipeline using Kubernetes and Argo Workflows, an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. These were tools they were familiar with, as they were already using them in their infrastructure.
But as soon as they tried to run the job for all the companies on the platform, they ran up against the limits of what their system could handle efficiently. Because the solution depended on a centralized controller, Argo Workflows, it was not robust, and the controller was scaled to its maximum capacity during this time. At that time, they only had 150,000 companies. And running the job with all of the companies took around 8 days, during which the system would crash and need to be restarted. It was very labor intensive, and it always required an engineer on call to monitor and troubleshoot the job.
The tipping point came when Charles joined the Analytics team at the beginning of 2022. One of his first tasks was to do a full model run on approximately 170,000 companies at that time. The model run lasted the whole week and ended at 2:00 AM on a Sunday. That’s when he decided their system needed to evolve.
Second iteration
With the pain of the last time he ran the model fresh in his mind, Charles thought through how he could rewrite the workflow. His first thought was to use AWS Lambda and Amazon Simple Queue Service (Amazon SQS), but he realized that he needed an orchestrator in that solution. That’s why he chose Step Functions, a serverless service that helps you automate processes, orchestrate microservices, and create data and ML pipelines; plus, it scales as needed.
Charles got the new version of the workflow with Step Functions working in about 2 weeks. The first step he took was adapting his existing Docker image to run in Lambda using Lambda’s container image packaging format. Because the container already worked for his data processing tasks, this update was simple. He scheduled Lambda provisioned concurrency to make sure that all functions he needed were ready when he started the job. He also configured reserved concurrency to make sure that Lambda would be able to handle this maximum number of concurrent executions at a time. In order to support so many functions executing at the same time, he raised the concurrent execution quota for Lambda per account.
And to make sure that the steps were run in parallel, he used Step Functions and the map state. The map state allowed Charles to run a set of workflow steps for each item in a dataset. The iterations run in parallel. Because Step Functions map state offers 40 concurrent executions and CyberGRX needed more parallelization, they created a solution that launched multiple state machines in parallel; in this way, they were able to iterate fast across all the companies. Creating this complex solution, required a preprocessor that handled the heuristics of the concurrency of the system and split the input data across multiple state machines.
This second iteration was already better than the first one, as now it was able to finish the execution with no problems, and it could iterate over 200,000 companies in 90 minutes. However, the preprocessor was a very complex part of the system, and it was hitting the limits of the Lambda and Step Functions APIs due to the amount of parallelization.

Third and final iteration
Then, during AWS re:Invent 2022, AWS announced a distributed map for Step Functions, a new type of map state that allows you to write Step Functions to coordinate large-scale parallel workloads. Using this new feature, you can easily iterate over millions of objects stored in Amazon Simple Storage Service (Amazon S3), and then the distributed map can launch up to 10,000 parallel sub-workflows to process the data.
When Charles read in the News Blog article about the 10,000 parallel workflow executions, he immediately thought about trying this new state. In a couple of weeks, Charles built the new iteration of the workflow.
Because the distributed map state split the input into different processors and handled the concurrency of the different executions, Charles was able to drop the complex preprocessor code.
The new process was the simplest that it’s ever been; now whenever they want to run the job, they just upload a file to Amazon S3 with the input data. This action triggers an Amazon EventBridge rule that targets the state machine with the distributed map. The state machine then executes with that file as an input and publishes the results to an Amazon Simple Notification Service (Amazon SNS) topic.
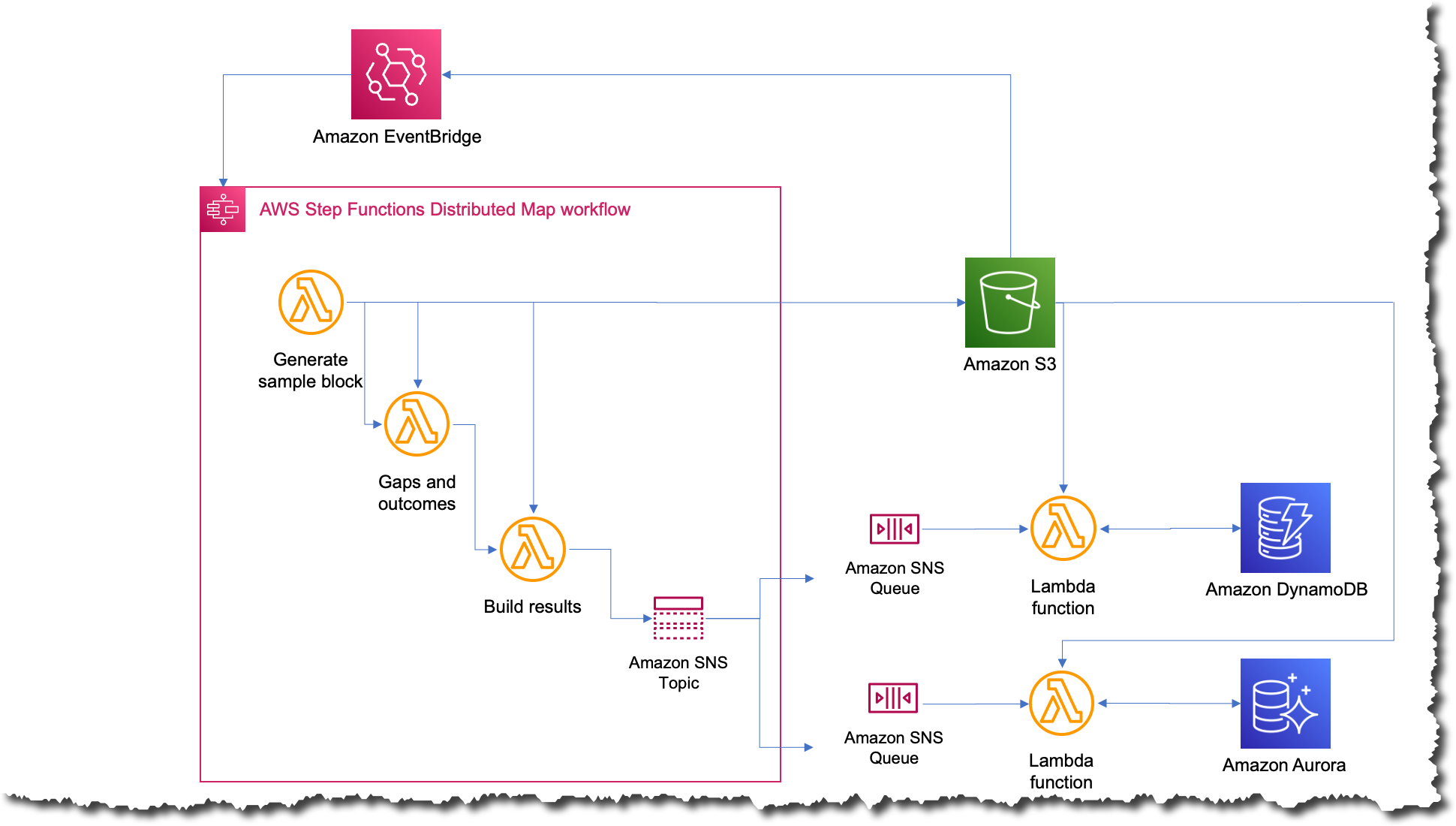
What was the impact?
A few weeks after completing the third iteration, they had to run the job on all 227,000 companies in their platform. When the job finished, Charles’ team was blown away; the whole process took only 56 minutes to complete. They estimated that during those 56 minutes, the job ran more than 57 billion calculations.

The following image shows an Amazon CloudWatch graph of the concurrent executions for one Lambda function during the time that the workflow was running. There are almost 10,000 functions running in parallel during this time.

Simplifying and shortening the time to run the job opens a lot of possibilities for CyberGRX and the data science team. The benefits started right away the moment one of the data scientists wanted to run the job to test some improvements they had made for the model. They were able to run it independently without requiring an engineer to help them.
And, because the predictive model itself is one of the key offerings from CyberGRX, the company now has a more competitive product since the predictive analysis can be refined on a daily basis.
Learn more about using AWS Step Functions:
You can also check the Serverless Workflows Collection that we have available in Serverless Land for you to test and learn more about this new capability.
— Marcia