AWS Big Data Blog
A Zero-Administration Amazon Redshift Database Loader
Ian Meyers is a Solutions Architecture Senior Manager with AWS
With this new AWS Lambda function, it’s never been easier to get file data into Amazon Redshift. You simply push files into a variety of locations on Amazon S3 and have them automatically loaded into your Amazon Redshift clusters.
Using AWS Lambda with Amazon Redshift
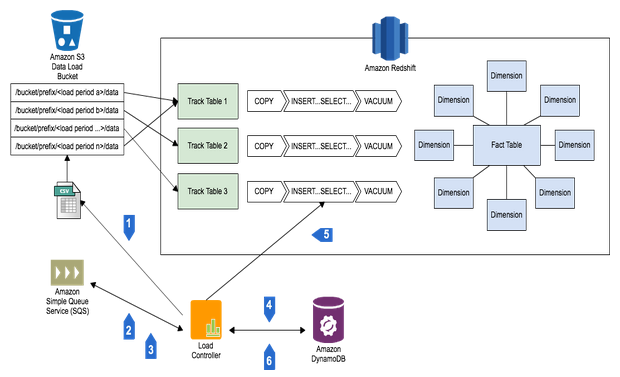
Amazon Redshift is a fully managed, petabyte-scale data warehouse available for less than $1000/TB/YR that provides AWS customers with an extremely powerful way to analyze their applications and businesses as a whole. To load clusters, customers ingest data from a large number of sources,such as FTP locations managed by third parties, or internal applications generating load files. The best practice for loading Amazon Redshift is to use the COPY command, which loads data in parallel from Amazon S3, Amazon DynamoDB or an HDFS file system on Amazon EMR.
Whatever the input, customers must run servers that look for new data on the file system, and manage the workflow of loading new data and dealing with any issues that might arise. That’s why we created the AWS Lambda-based Amazon Redshift loader (http://github.com/awslabs/aws-lambda-redshift-loader), to offer you the ability to drop files into S3 and load them into any number of database tables in multiple Amazon Redshift clusters automatically, with no servers to maintain. This is possible because AWS Lambda provides an event-driven, zero-administration compute service. It allows developers to create applications that are automatically hosted and scaled, while providing you with a fine-grained pricing structure.

The function maintains a list of all the files to be loaded from S3 into an Amazon Redshift cluster with DynamoDB. This list ensures that a file is loaded only one time, and allows you to determine when a file was loaded and into which table. Files found in Input locations are buffered up to a specified batch size that you control, or you can specify a time-based threshold that triggers a load.
You can specify any of the many COPY options available, and we support loading both CSV files (of any delimiter), as well as JSON files (with or without JSON path specifications). All passwords and access keys are encrypted for security. With AWS Lambda, you get automatic scaling, high availability, and built-in Amazon CloudWatch logging.
Finally, we’ve provided tools to manage the status of your load processes, with built-in configuration management and the ability to monitor batch status and troubleshoot issues. We also support sending notifications of load status through Amazon SNS, so you have visibility into how your loads are progressing over time.
Accessing the AWS Lambda Amazon Redshift Database Loader
You can download this AWS Lambda function today from AWSLabs: http://github.com/awslabs/aws-lambda-redshift-loader. For example, perform the following steps to complete local setup:
git clone https://github.com/awslabs/aws-lambda-redshift-loader.git cd aws-lambda-redshift-loader npm install
Getting Started: Preparing your Amazon Redshift Cluster
In order to load a cluster, we’ll have to enable AWS Lambda to connect. To do this, we must enable the cluster security group to allow access from the public internet. In the future, AWS Lambda will support presenting the service as though it was inside your own VPC.
To configure your cluster security group for access:
- Log in to the Amazon Redshift console.
- Select Security in the navigation pane on the left.
- Choose the cluster security group in which your cluster is configured.
- Add a new Connection Type of CIDR/IP and enter the value 0.0.0.0/0.
- Select Authorize to save your changes.
We recommend granting Amazon Redshift users only INSERT rights on tables to be loaded. Create a user with a complex password using the CREATE USER command, and grant INSERT using GRANT.
Getting Started: Deploying the AWS Lambda Function
To deploy the function:
- Go to the AWS Lambda console in the same region as your S3 bucket and Amazon Redshift cluster.
- Select Create a Lambda function and enter the name MyLambdaDBLoader (for example).
- Under Code entry type, select Upload a zip file and upload the AWSLambdaRedshiftLoader-1.1.zip from GitHub.
- Use the default values of index.js for the filename and handler for the handler, and follow the wizard for creating the AWS Lambda execution role. We also recommend using the max timeout for the function, which is 60 seconds in preview.
Next, configure an event source, which delivers S3 PUT events to your AWS Lambda function.
- On the deployed function, select Configure Event Source and select the bucket you want to use for input data. Select either the lambda_invoke_role or use the Create/Select function to create the default invocation role.
- Click Submit to save the changes.
When you’re done, you’ll see that the AWS Lambda function is deployed and you can submit test events and view the CloudWatch Logs log streams.
A Note on Versions
We previously released version 1.0 in distribution AWSLambdaRedshiftLoader.zip. This version didn’t use the Amazon Key Management Service for encryption. If you’ve previously deployed and used version 1.0 and want to upgrade to version 1.1, do the following:
- Recreate your configuration by running node setup.js.
- Re-enter the previous values, including connection password and S3 secret key.
- Upgrade the IAM policy for the AWS Lambda Execution Role as described in the next section, because it now has permissions to talk to the Key Management Service.
Getting Started: Lambda Execution Role
You also need to add an IAM policy as shown below to the role that AWS Lambda uses when it runs. After your function is deployed, add the following policy to the lambda_exec_role to enable AWS Lambda to call SNS, use DynamoDB, and perform encryption with the AWS Key Management Service.
Getting Started: Support for Notifications
This function can send notifications on completion of batch processing, if required. Using SNS, you can receive notifications through email and HTTP Push to an application, or put them into a queue for later processing. If you would like to receive SNS notifications for succeeded loads, failed loads, or both, create SNS topics and take note of their IDs in the form of Amazon Resource Notations (ARN).Getting Started: Entering the Configuration
Now that your function is deployed, you need to create a configuration which tells it how and if files should be loaded from S3. Install AWS SDK for JavaScript and configure it with credentials as outlined in the Getting Started with the SDK in Node.js tutorial and the Configuring the SDK in Node.js tutorial. You’ll also need a local instance of Node.js and to install dependencies using the following command:cd aws-lambda-redshift-loader && npm install
Note: To ensure communication with the correct AWS Region, you’ll need to set an environment variable AWS_REGION to the desired location. For example, for US East use us-east=1, and for EU West 1 use eu-west-1.
export AWS_REGION=eu-central-1
Next, run the setup.js script by entering node setup.js. The script asks questions about how the load should be done, including those outlined in the setup appendix as the end of this document. The database password, as well as the secret key used by Amazon Redshift to access S3 will be encrypted by the Amazon Key Management Service. Setup will create a new Customer Master Key with an alias named `alias/LambaRedshiftLoaderKey`.
Viewing Previous Batches & Status
If you ever need to see what happened to batch loads into your cluster, you can use the queryBatches.js script to look into the LambdaRedshiftBatches DynamoDB table . It takes the following arguments:
- region: The region in which the AWS Lambda function is deployed
- status: The status you are querying for, including ‘error’, ‘complete’, ‘pending’, or ‘locked’
- date: Optional date argument to use as a start date for querying batches
Running node queryBatches.js eu-west-1 error would return a list of all batches with a status of error in the EU (Ireland) region, such as:
[
{
"s3Prefix": "lambda-redshift-loader-test/input",
"batchId": "2588cc35-b52f-4408-af89-19e53f4acc11",
"lastUpdateDate": "2015-02-26-16:50:18"
},
{
"s3Prefix": "lambda-redshift-loader-test/input",
"batchId": "2940888d-146c-47ff-809c-f5fa5d093814",
"lastUpdateDate": "2015-02-26-16:50:18"
}
]
If you require more detail on a specific batch, you can use describeBatch.js to show all detail for a batch. It takes the following arguments:
- region: The region in which the AWS Lambda function is deployed
- batchId: The batch you would like to see the detail for
- s3Prefix: The S3 prefix the batch was created for
These arguments return the batch information as it is stored in DynamoDB:
{
"batchId": {
"S": "7325a064-f67e-416a-acca-17965bea9807"
},
"manifestFile": {
"S": "my-bucket/manifest/manifest-2015-02-06-16:20:20-2081"
},
"s3Prefix": {
"S": "input"
},
"entries": {
"SS": [
"input/sample-redshift-file-for-lambda-loader.csv",
"input/sample-redshift-file-for-lambda-loader1.csv",
"input/sample-redshift-file-for-lambda-loader2.csv",
"input/sample-redshift-file-for-lambda-loader3.csv",
"input/sample-redshift-file-for-lambda-loader4.csv",
"input/sample-redshift-file-for-lambda-loader5.csv"
]
},
"lastUpdate": {
"N": "1423239626.707"
},
"status": {
"S": "complete"
}
}
Clearing Processed Files
We’ll only load a file one time by default, but in certain rare cases you might want to re-process a file, such as when a batch goes into error state for some reason. If so, use the processedFiles.js script to query or delete processed files entries. The script takes an operation type and filename as arguments. Use -q to query if a file has been processed, and -d to delete a file entry. Below is an example of the processed files store:

Reprocessing a Batch
If you need to reprocess a batch, for example if it failed to load the required files for some reason, you can use the reprocessBatch.js script. This takes the same arguments as describeBatch.js (region, batch ID and input location). The original input batch is not affected; instead, each of the input files that were part of the batch are removed from the LambdaRedshiftProcessedFiles table, and then the script forces an S3 event to be generated for the file location in S3. This will be captured and reprocessed by the function as it was originally. You can only reprocess batches that are not in “open” status.
Ensuring Periodic Loads
If you have a prefix that doesn’t receive files very often, and want to ensure that files are loaded every N minutes, use the following process to force periodic loads.
When you create the configuration, add a filenameFilterRegex such as .*.csv, which only loads CSV files that are put into the specified S3 prefix. Then every N minutes, schedule the included dummy file generator through a cron job.
./path/to/function/dir/generate-dummy-file.py <region> <input bucket> <input prefix> <local working directory>
- region: The region in which the input bucket for loads resides
- input bucket: The bucket that is configured as an input location
- input prefix: The prefix that is configured as an input location
- local working directory: The location where the stub dummy file will be kept prior to upload into S3
This writes a file called lambda-redshift-trigger-file.dummy to the configured input prefix, which causes your deployed function to scan the open pending batch and load the contents if the timeout seconds limit has been reached.
Reviewing Logs
Under normal operations, you won’t have to do anything from an administration perspective. Files placed into the configured S3 locations will be loaded when the number of new files equals the configured batch size. You may want to create an operational process to deal with failure notifications, but you can also just view the performance of your loader by looking at Amazon CloudWatch. Open the CloudWatch console and then click Logs in the navigation pane on the left. You can then select the log group for your function, with a name such as /aws/lambda/<My Function>.

Each of the above log streams were created by an AWS Lambda function invocation and will be rotated periodically. You can see the last ingestion time, which is when AWS Lambda last pushed events into CloudWatch Logs.
You can then review each log stream, and see events where your function simply buffered a file:

Or where it performed a load:

Extending and Building New Features
We’re excited to offer this AWS Lambda function under the Amazon Software License. The GitHub repository does not include all the dependencies for Node.js, so in order to build and run locally please install the following modules with npm install:
- Java: Bridge API to connect with existing Java APIs (https://www.npmjs.com/package/java & `npm install java`) – requires a default path entry for libjvm.so and an installed ‘javac’
- JDBC: Node Module JDBC wrapper (https://www.npmjs.com/package/jdbc & `npm install jdbc`)
- Async: Higher-order functions and common patterns for asynchronous code (https://www.npmjs.com/package/async & `npm install async`)
- Node UUID: Rigorous implementation of RFC4122 (v1 and v4) UUIDs (https://www.npmjs.com/package/node-uuid & ‘npm install node-uuid`)
Appendix: A Sample Loader
In the project GitHub we’ve included a sample directory which will help you give this function a try. This sample includes the setup scripts to configure your database for loads of the sample data, as well as the script to create a sample configuration.
To get started, deploy the AWSLambdaRedshiftLoader-1.1.zip from the GitHub ‘dist’ folder as outlined in the Getting Started section, and install the dependent modules (npm install java jdbc async node-uuid). You’ll also need to have an Amazon Redshift cluster set up, and have the cluster endpoint address, port, the database name in which you want to run the sample, and the username and password of a database user that can create a user specifically used for the sample. You’ll also need to have the PostgreSQL command line client and a bash terminal.
When you are ready, just run the configureSample.sh in the sample/scripts directory using a terminal such as PUTTY. This requires arguments of the cluster endpoint address, port, db name and db user, in that order, and will prompt for your DB user password. This script then:
- Creates a database user called test_lambda_load_user, which you can drop after you are finished with the sample
- Creates a database table owned by this new user called lambda_redshift_sample, which just has three integer columns
- Runs the configuration script which will further prompt for required configuration values such as the S3 bucket you want to use for the sample, and access key information
You are now set to try out loading the database. Simply transfer the files from the sample/data directory to the input prefix in the S3 bucket you provided to the setup script. For example (using the AWS CLI):
aws s3 sync ../data s3://<my bucket>/input –region <region for my bucket>
You can then go into your deployed AWS Lambda function and review the CloudWatch Logs log streams that will show two loaded batches of two files each, and one file in an open batch.
To clean up the demo loader, just run cleanup.sh with the same arguments. The Amazon Redshift table and user will be deleted and the configuration tables in DynamoDB will also be removed.
If you have questions or suggestions, please leave a comment at the end of this post.
Appendix: Setup Notes and Configuration Reference
The following table provides guidance on the supported configuration options.
For items such as the batch size, please keep in mind that in Preview the Lambda function timeout is 60 seconds. This means that your COPY command must complete in less than ~ 50 seconds so that the Lambda function has time to finish writing batch metadata. The COPY time is a function of file size, the number of files to be loaded, the size of the cluster, and how many other processes might be consuming WorkLoadManagement queue slots.
| Item | Required | Notes |
|---|---|---|
| Enter the Region for the Redshift Load Configuration |
Y |
Any AWS region from http://docs.aws.amazon.com/general/latest/gr/rande.html, using the short name (for example us-east-1 for US East N. Virginia) |
| Enter the S3 Bucket & Prefix to watch for files |
Y |
An S3 path in format <bucket name>/<prefix>. Prefix is optional |
| Enter a Filename Filter Regex |
N |
A regular expression used to filter files which appeared in the input prefix before they are processed. |
| Enter the Cluster Endpoint |
Y |
The Amazon Redshift endpoint address for the cluster to be loaded. |
| Enter the Cluster Port |
Y |
The port on which you have configured your Amazon Redshift cluster to run. |
| Enter the Database Name |
Y |
The database name in which the target table resides. |
| Enter the Database Username |
Y |
The username that should be used to connect to perform the COPY. Only table owners can perform COPY, so this should be the schema in which the target table resides. |
| Enter the Database Password |
Y |
The password for the database user. This will be encrypted before storage in DynamoDB. |
| Enter the Table to be Loaded |
Y |
The table name to be loaded with the input data. |
| Should the Table be Truncated before Load? (Y/N) |
N |
Option to truncate the table prior to loading. Use this option if you will subsequently process the input data and only want to see ‘new’ data with this ELT process. |
| Enter the Data Format (CSV or JSON) |
Y |
Determines whether the data format is character separated values or JSON data. See Amazon Redshift documentation for more information. |
| If CSV, Enter the CSV Delimiter |
Yes if Data Format = CSV |
Single-character delimiter value, such as ‘,’ (comma) or ‘|’ (pipe). |
| If JSON, Enter the JSON Paths File Location on S3 (or NULL for Auto) |
Yes if Data Format = JSON |
Location of the JSON paths file to use to map the file attributes to the database table. If not filled, the COPY command uses option ‘json = auto’ and the file attributes must have the same name as the column names in the target table. |
| Enter the S3 Bucket for Redshift COPY Manifests |
Y |
The S3 bucket in which to store the manifest files used to perform the COPY. This should not be the input location for the load. |
| Enter the Prefix for Redshift COPY Manifests |
Y |
The prefix for COPY manifests. |
| Enter the Prefix to use for Failed Load Manifest Storage |
N |
If the COPY, fails you can have the manifest file copied to an alternative location. Enter that prefix, which will be in the same bucket as the rest of your COPY manifests. |
| Enter the Access Key used by Redshift to get data from S3 |
Y |
Amazon Redshift must provide credentials to S3 to be allowed to read data. Enter the access key for the account or IAM user that Amazon Redshift should use. |
| Enter the Secret Key used by Redshift to get data from S3 |
Y |
The secret Key for the access key used to get data from S3. This will be encrypted prior to storage in DynamoDB. |
| Enter the SNS Topic ARN for Failed Loads |
N |
If you want notifications to be sent to an SNS topic on successful load, enter the ARN here. This would be in format ‘arn:aws:sns:<region>:<account number>:<topic name>. |
| Enter the SNS Topic ARN for Successful Loads |
N |
SNS Topic ARN for notifications when a batch COPY fails. |
| How many files should be buffered before loading? |
Y |
Enter the number of files placed into the input location before a COPY of the current open batch should be performed. Recommended to be an even multiple of the number of CPU’s in your cluster. You should set the multiple such that this count causes loads to be every 2-5 minutes. |
| How old should we allow a Batch to be before loading (seconds)? |
N |
AWS Lambda will attempt to sweep out ‘old’ batches using this value as the number of seconds old a batch can be before loading. This ‘sweep’ is on every S3 event on the input location, regardless of whether it matches the Filename Filter Regex. Not recommended to be below 120. |
| Additional Copy Options to be added |
N |
Enter any additional COPY options that you would like to use, as outlined at (http://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html). Please also see http://blogs.aws.amazon.com/bigdata/post/Tx2ANLN1PGELDJU/Best-Practices-for-Micro-Batch-Loading-on-Amazon-Redshift for information on good practices for COPY options in high frequency load environments. |
Appendix: Github Table of Contents
The following files are included with the distribution:
|
Filename |
Arguments |
Purpose |
| index.js | Main method of the AWS Lambda function, which exports the handler method invoked by AWS Lambda. | |
| constants.js | Constant values used by the function and scripts, such as console application exit codes and table names. | |
| common.js | Exported JavaScript methods for validating end user input, methods for date handling, etc. | |
| processedFiles.js | region, process option (-d for delete, -q for query), filename | Script that queries or deletes files from the LambdaRedshiftProcessedFiles table. Use this script to reprocess a single input file processed by a batch previously. |
| describeBatch.js | region, batch ID, input prefix | Script that outputs the status of a given batch. |
| queryBatches.js | region, batch status (complete, error, locked, open) and optionally a search date | Script that outputs a list of batches within a period, and for a specific batch status |
| unlockBatch.js | region, batch ID, input prefix | Script that transitions a locked batch to open status. This should never be required for normal operation, and would only be required if the function instance that was processing an input batch failed during modification of the batch state. |
| reprocessBatch.js | region, batch ID, input prefix | Script that causes all input events for a batch to be reprocessed as new. |
| test.js | Test harness that enables you to locally test your function by typing in the contents of the event to supply and then invoking the AWS Lambda function handler. | |
| generate-trigger-file.py | region, input bucket, input prefix, local directory for temp file | Python script that generates a ‘lambda-redshift-trigger-file.dummy’ file to a specified input location. Use this script as part of a scheduled task (such as a cron job) to ensure that low frequency loads occur when required. |
Do more with Amazon Redshift:
Best Practices for Micro-batch Loading on Amazon Redshift
Using Amazon Redshift to Analyze your ELB Traffic Logs
Using Attunity Cloudbeam at UMUC to Replicate Data to Amazon RDS and Amazon Redshift
