AWS Big Data Blog
Tag: AWS Lambda

Building serverless event streaming applications with Amazon MSK and AWS Lambda
In this post, we describe how you can simplify your event-driven application architecture using AWS Lambda with Amazon MSK. We demonstrate how to configure Lambda as a consumer for Kafka topics, including a cross-account setup and how to optimize price and performance for these applications.

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

Level up your React app with Amazon QuickSight: How to embed your dashboard for anonymous access
Using embedded analytics from Amazon QuickSight can simplify the process of equipping your application with functional visualizations without any complex development. There are multiple ways to embed QuickSight dashboards into application. In this post, we look at how it can be done using React and the Amazon QuickSight Embedding SDK. Dashboard consumers often don’t have […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Synchronize and control your Amazon Redshift clusters maintenance windows
Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Amazon Redshift to run mission-critical business intelligence dashboards, analyze real-time streaming data, and run predictive analytics jobs. Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and […]
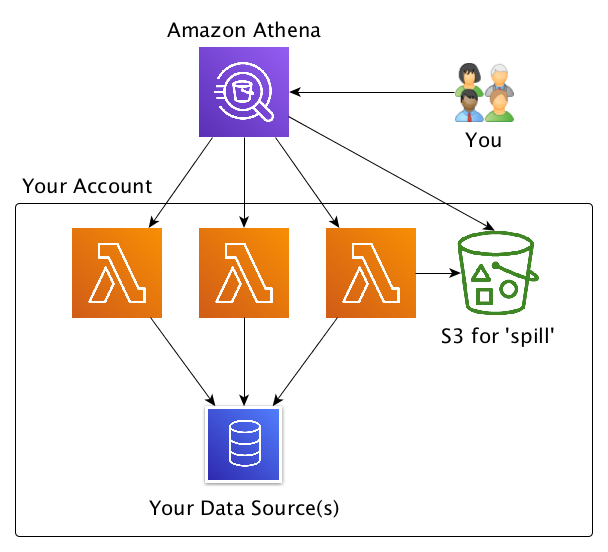
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]
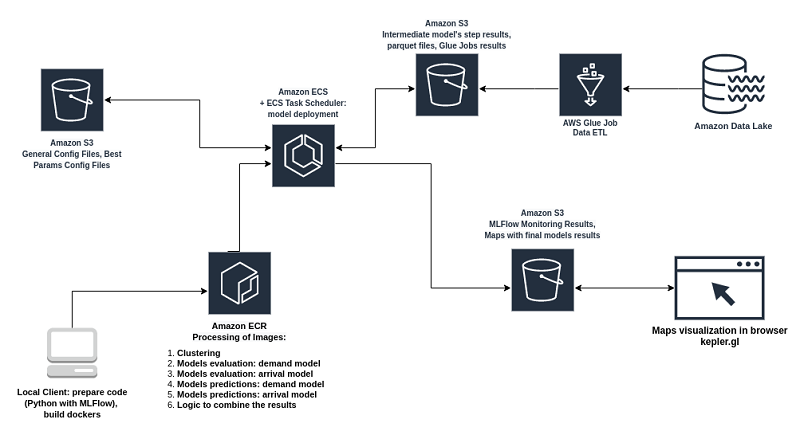
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.

Ingest Excel data automatically into Amazon QuickSight
Amazon QuickSight is a fast, cloud-powered, business intelligence (BI) service that makes it easy to deliver insights to everyone in your organization. This post demonstrates how to build a serverless data ingestion pipeline to automatically import frequently changed data into a SPICE (Super-fast, Parallel, In-memory Calculation Engine) dataset of Amazon QuickSight dashboards. It is sometimes […]

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]