AWS Big Data Blog
Amazon SageMaker Catalog expands discoverability and governance for Amazon S3 general purpose buckets
In July 2025, Amazon SageMaker announced support for Amazon Simple Storage Service (Amazon S3) general purpose buckets and prefixes in Amazon SageMaker Catalog that delivers fine-grained access control and permissions through S3 Access Grants. This integration addresses the challenge data teams face when manually managing data discovery and Amazon S3 permissions as separate workflows. Data consumers, such as data scientists, engineers, and business analysts, can now discover and access S3 buckets or prefixes data assets through SageMaker Catalog, while administrators can maintain granular access controls using S3 Access Grants permissions.
Building upon existing SageMaker support for structured data in Amazon S3 Tables buckets, the added support for S3 general purpose buckets makes it straightforward for teams to find, access, and collaborate on different types of data, including unstructured data such as documents, images, audio, and video, while providing access management. Data administrators and data stewards can now implement fine-grained access permissions for a bucket or a prefix using S3 Access Grants, supporting secure and appropriate data usage across their organization.
In this post, we explore how this integration addresses key challenges our customers have shared with us, and how data producers, such as administrators and data engineers, can seamlessly share and govern S3 buckets and prefixes using S3 Access Grants, while making it readily discoverable for data consumers. We walk you through a practical example of bringing Amazon S3 data into your projects and implementing effective governance for both analytics and generative AI workflows.
Challenges in working with unstructured data
Organizations face challenges in maximizing the value of their unstructured data assets. Although customers want to incorporate insights derived from unstructured data for comprehensive analysis, they often resort to building bespoke integrations to extract structured information from unstructured sources, leading to inefficient and fragmented solutions. Three critical roadblocks have historically hindered enterprises:
- Organizations struggle to maintain a catalog that offers equal discoverability for both structured and unstructured data, often resulting in separate systems for different data types.
- Data consumers throughout organizations want to analyze unstructured data using familiar tools like notebooks, just as they do with structured data, but are forced to use separate interfaces and workflows instead.
- Working with unstructured data lacks streamlined access management—users who discover relevant data can’t readily request access from owners, load information into analytics tools, or collaborate with colleagues directly from the workspaces or projects.
Amazon S3 unstructured data as a managed asset in Amazon SageMaker
SageMaker Catalog now supports S3 general purpose buckets. Data producers can publish S3 buckets and prefixes as S3 Object Collection assets, making those assets searchable and discoverable. As managed S3 Object Collection assets in SageMaker Catalog, access permissions are automatically handled using S3 Access Grants when data consumer teams subscribe to cataloged datasets, replacing bespoke data discovery and permission management workflows. Data producers can add business context to technical metadata, including glossary terms and descriptions. Data consumers can search, review, and request access to data assets through a unified workflow. Teams can then collaborate in SageMaker projects, incorporating datasets and conducting analysis while maintaining security and governance standards.The key benefits in the simplified discoverability and access to S3 data in SageMaker Catalog include:
- Seamless S3 data integration – You can use existing Amazon S3 data in SageMaker without migration or restructuring
- Enhanced cataloging and governance – SageMaker Catalog facilitates data publishing, discovery, and subscription with business metadata and security controls
- Improved data sharing – Cataloged Amazon S3 data becomes discoverable organization-wide, accelerating insights and collaboration
- Self-service data access – SageMaker provides tools for data preparation, ETL (extract, transform, and load), and connectivity from various sources, supporting faster analytics and AI solution development
With these benefits, you can accelerate time-to-insight and unlock the full potential of organizational data assets across teams.
Customer spotlight
Across industries, the true power of data emerges when organizations can seamlessly connect and analyze different types of information across their operations. Bayer, a leading pharmaceutical and biotechnology company, has vast sets of unstructured data organized across multiple S3 buckets and prefixes.
“Bringing a new drug to market is widely known across the industry to be a lengthy and expensive process, often taking 10–15 years and costing $1–2 billion on average, with a low overall success rate ranging from around 8% to 12%. SageMaker now allows us to easily discover and securely access data, structured and unstructured, while maintaining governance controls using S3 Access Grants. With SageMaker Catalog, we now have a streamlined approach to data management that enables us to combine datasets, both structured and unstructured, reducing research time and increasing productivity throughout the drug development lifecycle,” said Avinash Erupaka, Principal Engineer Lead, Bayer Pharma Drug Innovation Platform.
Solution overview
In life sciences organizations, unstructured and semi-structured data files are prevalent in research, development, bio-manufacturing, and diagnostics divisions. These might include digital pathology images, genetic sequence data, microwell plate readouts, analytical spectra, and chromatograms. Along with unstructured and semi-structured data, data engineers collect various business metadata, including study, project, laboratory protocol, and assay information, and operational metadata, including algorithmic steps, compute tasks, and process outputs.Scientists and business users can use SageMaker Catalog search for data assets using keywords that are found in the associated business metadata and operational metadata that are captured as metadata forms. For example, there might be searches for sample ID, experiment ID, group, platform, file names, dates, or keywords within the experimental description. These searches return a list of data assets that have association with those keywords, which are collections of S3 objects. Scientists and business users are given access to those collections of S3 objects.In the following sections, we walk through the setup step-by-step. We use the example of digital pathology images use case from the life sciences industry to demonstrate how researchers discover and get access to S3 objects using SageMaker.
Prerequisites
If you’re new to SageMaker, refer to the Amazon SageMaker User Guide to get started.
To follow along with this post, refer to Setting up Amazon SageMaker to set up a domain and create projects. This domain setup and project creation is a prerequisite for the other tasks in SageMaker.
Get data ready in Amazon S3
To store digital pathology images, create an S3 bucket (for example, researchdatafordigitalpathology), create a folder (for example, dpimages) under it, and upload digital pathology images. Ideally, you will have a collection of images under a given prefix, but for this example, we have chosen just one image file (dp_cancer.jpg). For instructions to create a bucket, refer to Creating a general purpose bucket.

Set up a data producer project
For data engineers, create a producer project in Amazon SageMaker Unified Studio to create digital pathology images as data assets. For more details on how to create projects, refer to Create a project. Add data engineers as members of the projects. For instructions to add members, refer to Add project members.
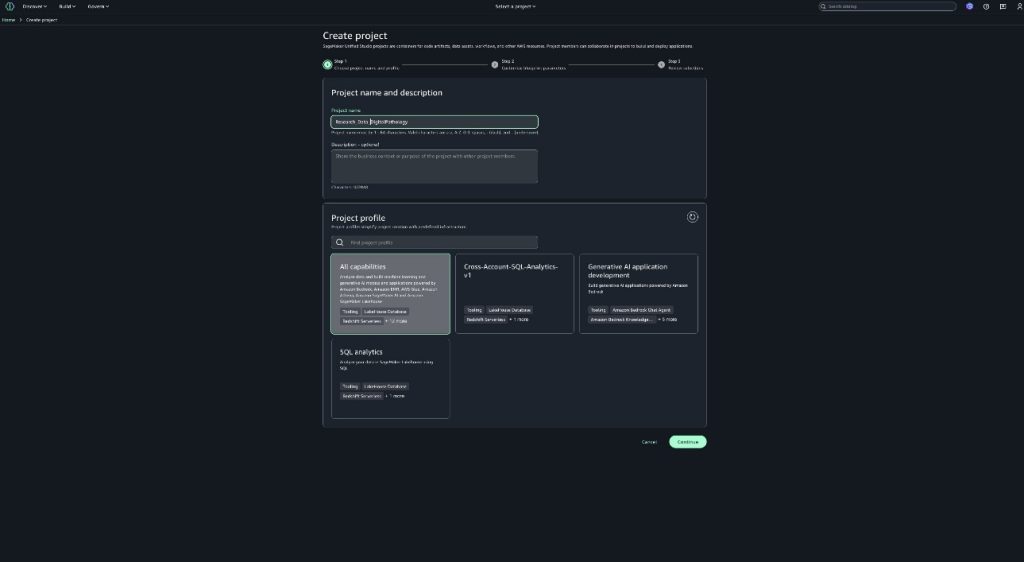
Add an Amazon S3 location
To add the collection of digital pathology images (to bring your own S3 buckets), complete the following steps:
- In SageMaker Unified Studio, go to the project where you want to add Amazon S3.
- Choose Data in the navigation pane, then choose the plus sign.
- On the Add data page, choose Add S3 location, then choose Next.
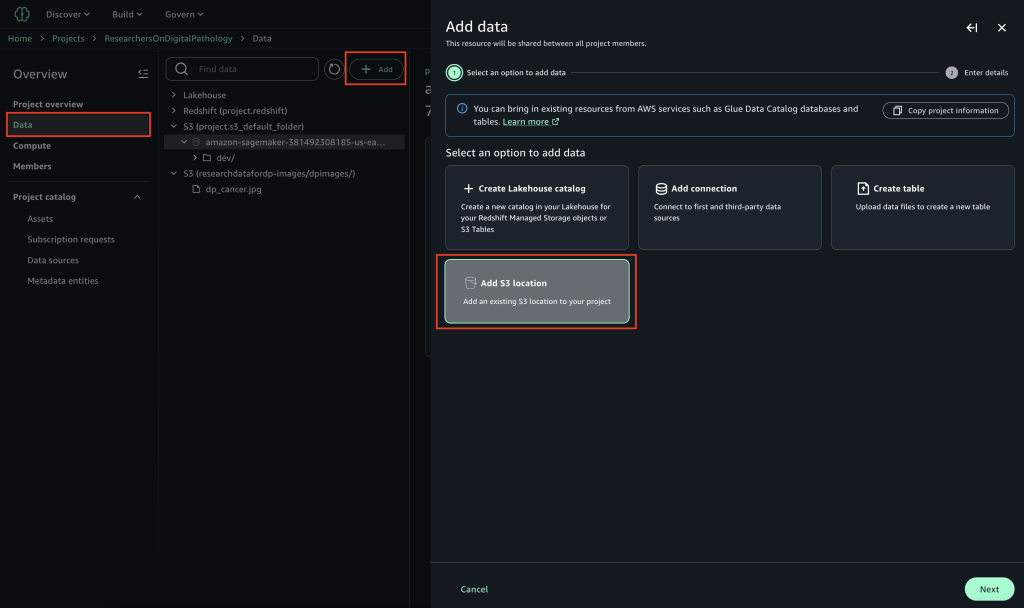
To obtain the details to create a connection, you can choose from two options:
- Using the project role:
- You, the project user, retrieves the project role and shares it with the AWS Management Console admin.
- The admin opens the AWS Identity and Access Management (IAM) console to update the project role with permissions.
- The admin opens the Amazon S3 console and adds a CORS policy to each bucket.
- Using an access role Amazon Resource Name (ARN), which is required for cross-account:
- You, the project user, shares the project ID and project role with the admin and requests access to the S3 bucket.
- The admin creates an access role (or uses an existing role) with permissions, adds a trust policy to the project, and tags it with the project ID.
- The admin opens the Amazon S3 console and adds a CORS policy to the bucket.
- The admin sends the Amazon S3 URI and access role details back to you.
After you have necessary permissions configured for the Amazon S3 location and project role, continue with the remaining steps.
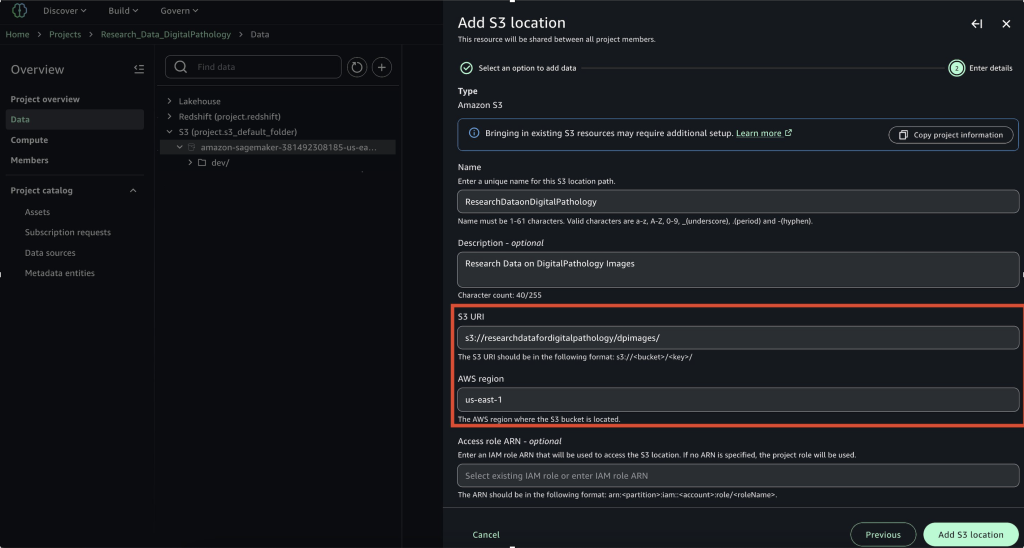
- On the Add S3 location page, enter the following details:
- Enter a name for the location path.
- (Optional) Add a description of the location path.
- Use the S3 URI and AWS Region provided by your admin.
- If your admin granted you access using an access role instead of the project role, enter the access role ARN obtained from your admin.
- Choose Add S3 location.
For more details, see Adding Amazon S3 data.
Publish data to SageMaker Catalog to make it discoverable
After you add the Amazon S3 location, complete the following steps to publish the data:
- In SageMaker Unified Studio, go to your project.
- Choose Data in the navigation pane and choose the Amazon S3 location.
- On the Actions dropdown menu, choose Publish to Catalog.
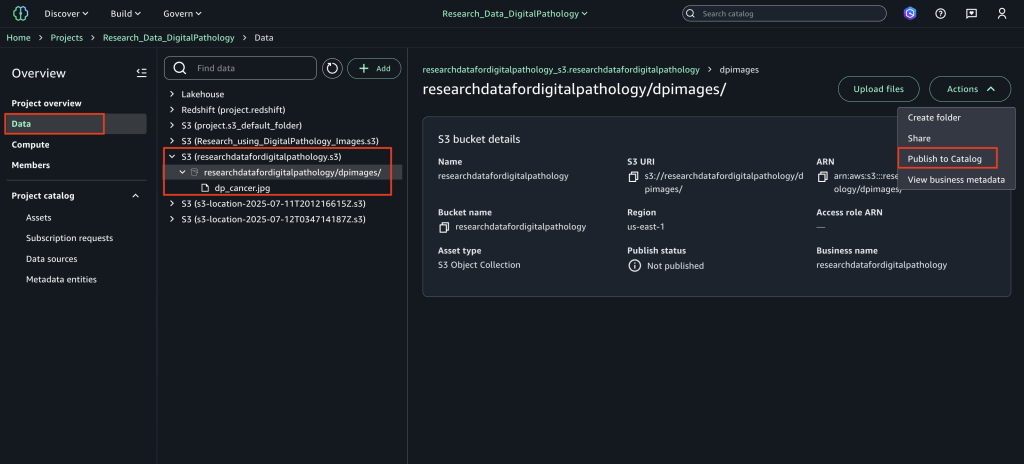
After you publish the assets, you can find the assets on the Published tab in the Assets page under Project catalog in the navigation pane.
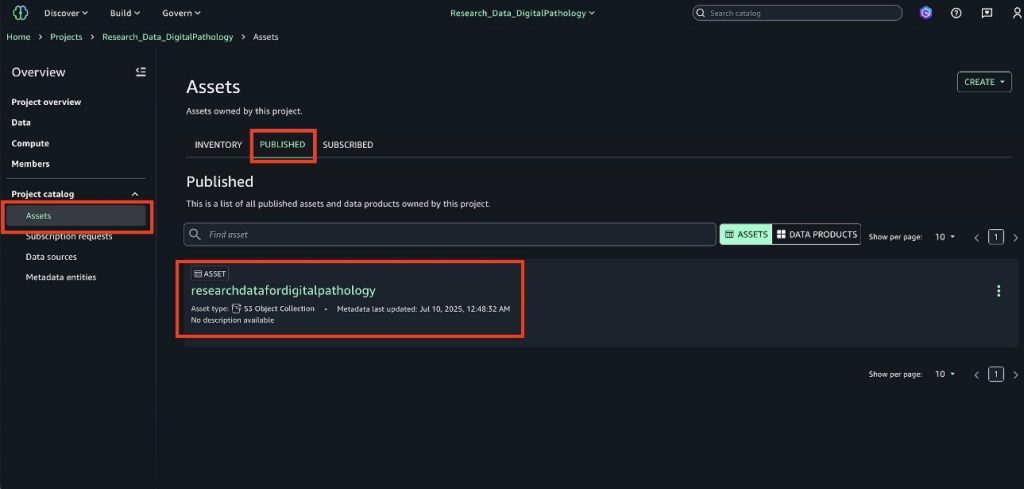
Create a consumer project
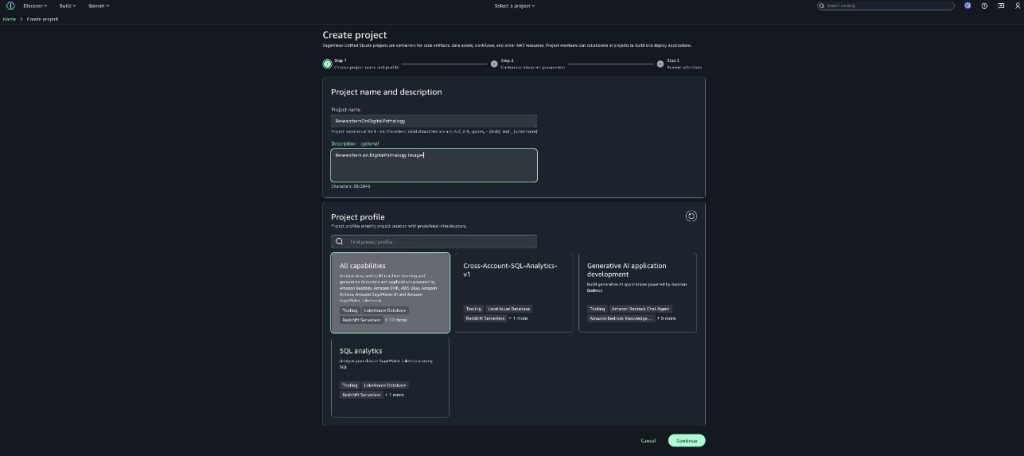
Create a consumer project for researchers to collaborate and bring necessary assets for their analysis and add researchers as members to the project. Consumers can search for available (published) data assets on digital pathology images for cancer research and then subscribe to work with it using JupyterLab notebooks in SageMaker. For more details on how to create projects, refer to Create a project. For instructions to add members, refer to Add project members.
Find relevant assets and request access
Researchers can search the SageMaker Catalog for available (published) data assets using the string digitalpathology. Complete the following steps:
- In SageMaker Unified Studio, on the Discover dropdown menu, choose Data Catalog.
- Find the asset you want to subscribe to by browsing or entering the name of the asset into the search bar.
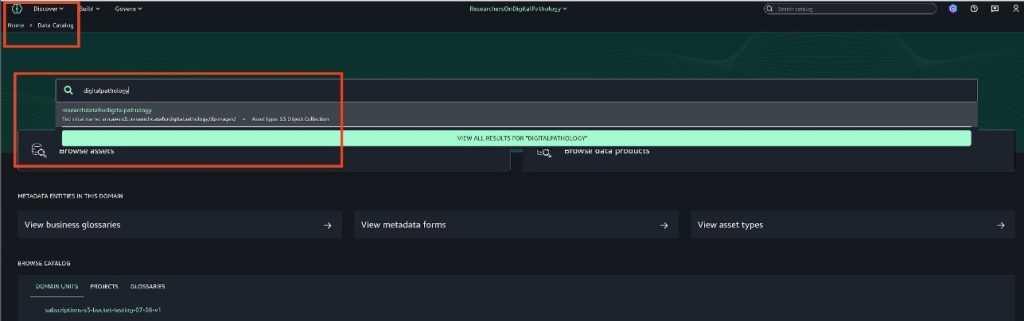
- Choose Subscribe.
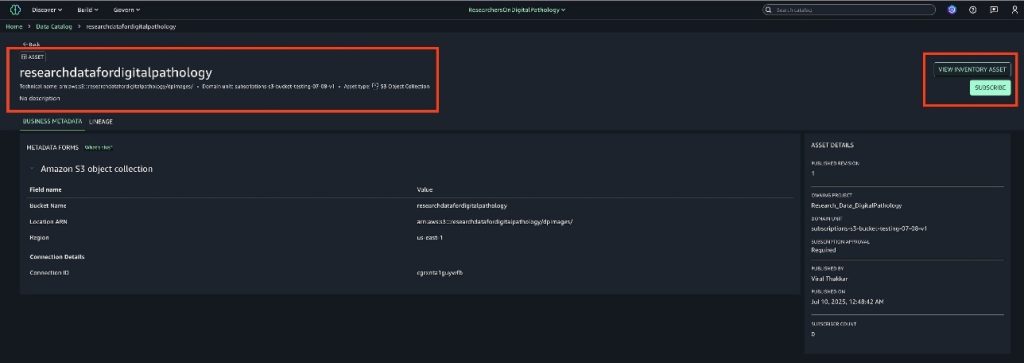
- Provide the following information:
- The project to which you want to subscribe the asset.
- A short justification for your subscription request. This information is used by the data producer to validate the request to grant access.
- Choose Request.
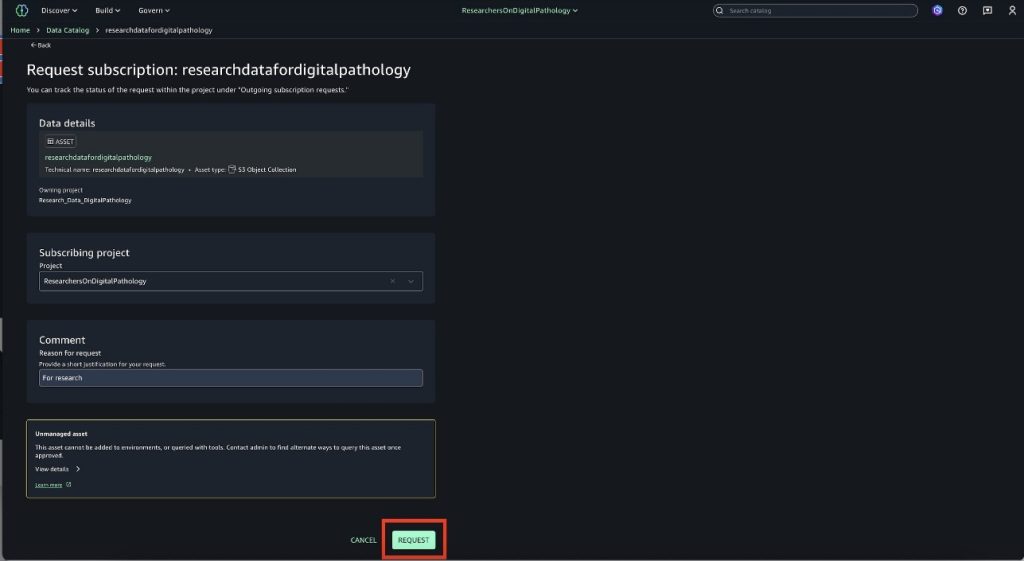
After you’re approved, the project will be subscribed to the asset and access is granted automatically. To provide access, SageMaker Catalog uses S3 Access Grants to grant read permission to the subscribing project for the specific S3 bucket or prefix.
To view the status of the subscription request, go to the project with which you subscribed to the asset. Choose Subscription requests in the navigation pane, then choose the Outgoing requests tab. This page lists the assets to which the project has requested access. You can filter the list by the status of the request.
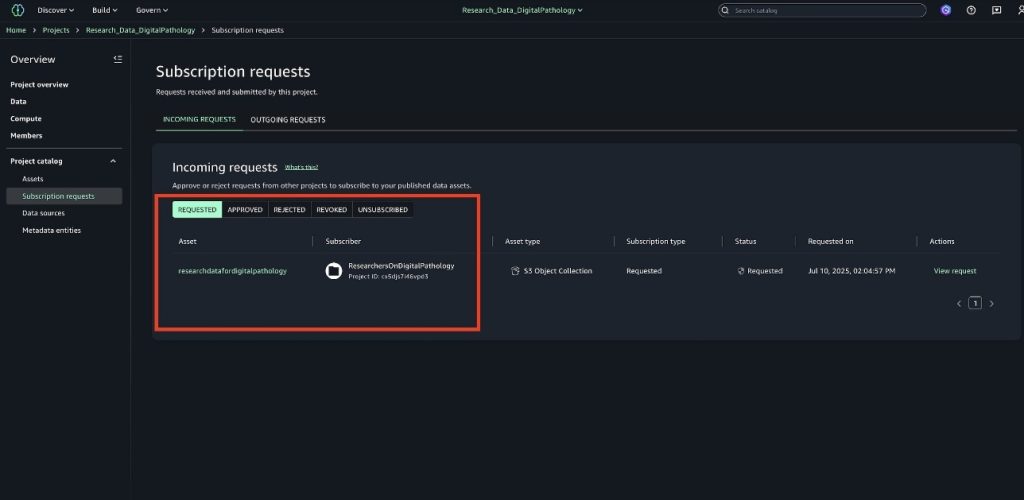
Review and approve the subscription request
The data producer or engineer of the publishing project must receive the request from the researcher and approve the request. After the request is approved, the researcher will have access to the objects for the S3 bucket (or prefix).
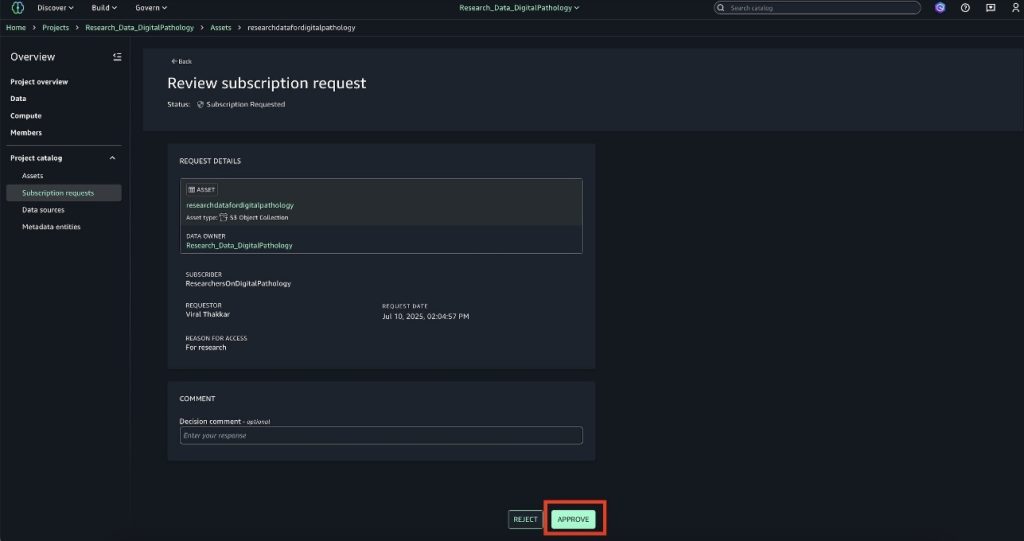
Before approving, the data producer can view the details of the subscription request to make sure they know who will get access to the data they own.
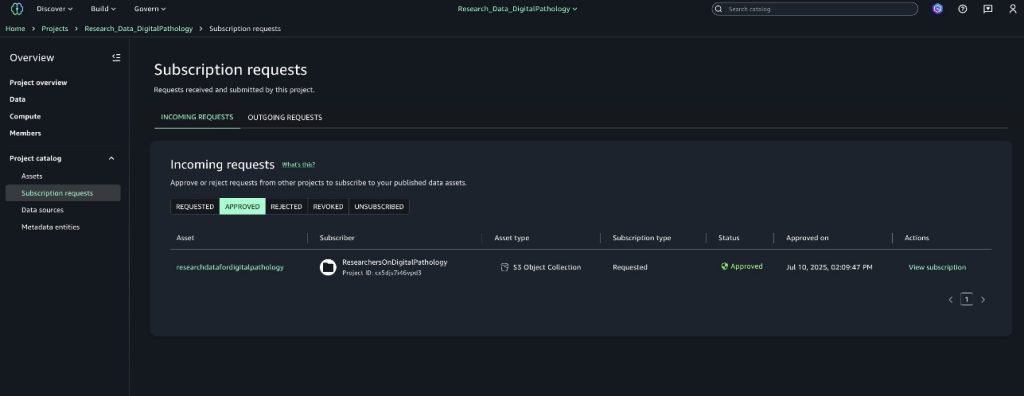
After they approve the request, the data producers can audit the different requests they have for the assets they own.
Access the subscribed data in notebooks
After the access request is approved, the researcher can open a JupyterLab notebook from SageMaker Unified Studio and access S3 objects to work on their research.To navigate to the JupyterLab notebook, complete the following steps:
- In SageMaker Unified Studio, open your project.
- On the Build dropdown menu, choose JupyterLab.
The following is sample Python code to access subscribed data. This sample code retrieves the S3 object that the researcher has been given access to and uses Matplotlib (a comprehensive 2D plotting library for Python language) to display the image in the notebook. In a real-world use case, a researcher typically uses these images for displaying or training machine learning models or performing multimodal analysis.
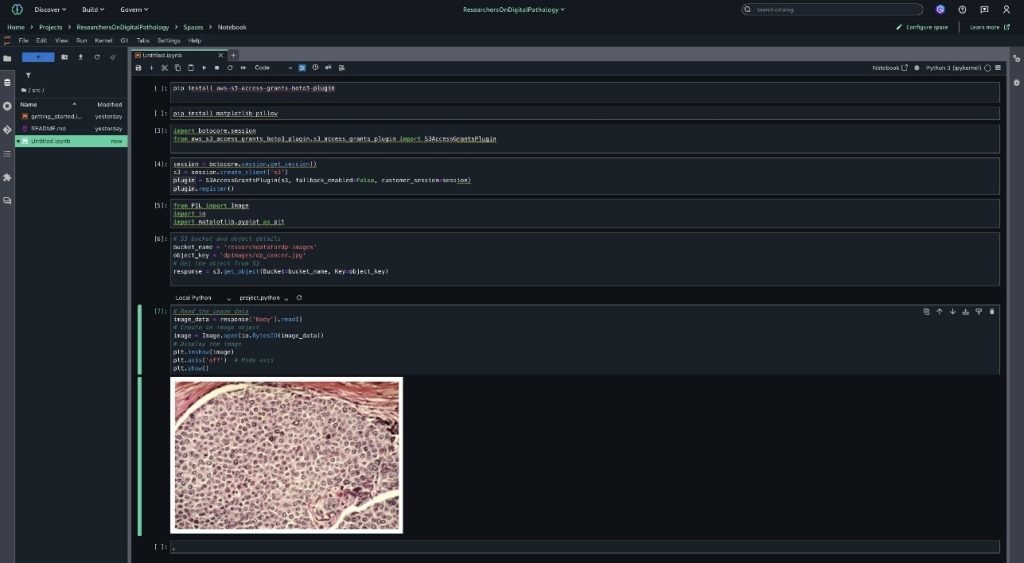
SageMaker and S3 Access Grants integrations
The SageMaker Catalog integration with S3 Access Grants facilitates secure data access across Amazon EMR Serverless, AWS Glue, Amazon EMR on Amazon EC2, and JupyterLab notebooks through simple configuration settings. By enabling S3 Access Grants with two properties ('fs.s3.s3AccessGrants.enabled': 'true' and 'fs.s3.s3AccessGrants.fallbackToIAM': 'true'), users gain streamlined access control while maintaining IAM as a fallback option. These configurations are automated in SageMaker Unified Studio. To learn more about S3 Access Grants integrations, see S3 Access Grants integrations, and for Boto3 S3 Access Grants support, refer to the following GitHub repo.
Conclusion
In this post, we discussed the added support for S3 general purpose buckets in SageMaker, and how they can be cataloged in SageMaker Catalog to help users quickly discover and securely manage access when sharing with other teams.
To learn more about SageMaker and how to get started, refer to the Amazon SageMaker User Guide and Amazon S3 data in Amazon SageMaker Unified Studio.
About the authors
 Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
 Subrat Das is a Principal Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
Subrat Das is a Principal Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
 Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon SageMaker Catalog engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon SageMaker Catalog engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
 Yuhang Huang is a Software Development Manager on the Amazon SageMaker Unified Studio team. He leads the engineering team to design, build, and operate scheduling and orchestration capabilities in SageMaker Unified Studio. In his free time, he enjoys playing tennis.
Yuhang Huang is a Software Development Manager on the Amazon SageMaker Unified Studio team. He leads the engineering team to design, build, and operate scheduling and orchestration capabilities in SageMaker Unified Studio. In his free time, he enjoys playing tennis.