AWS Big Data Blog
Author: Kalyan Janaki
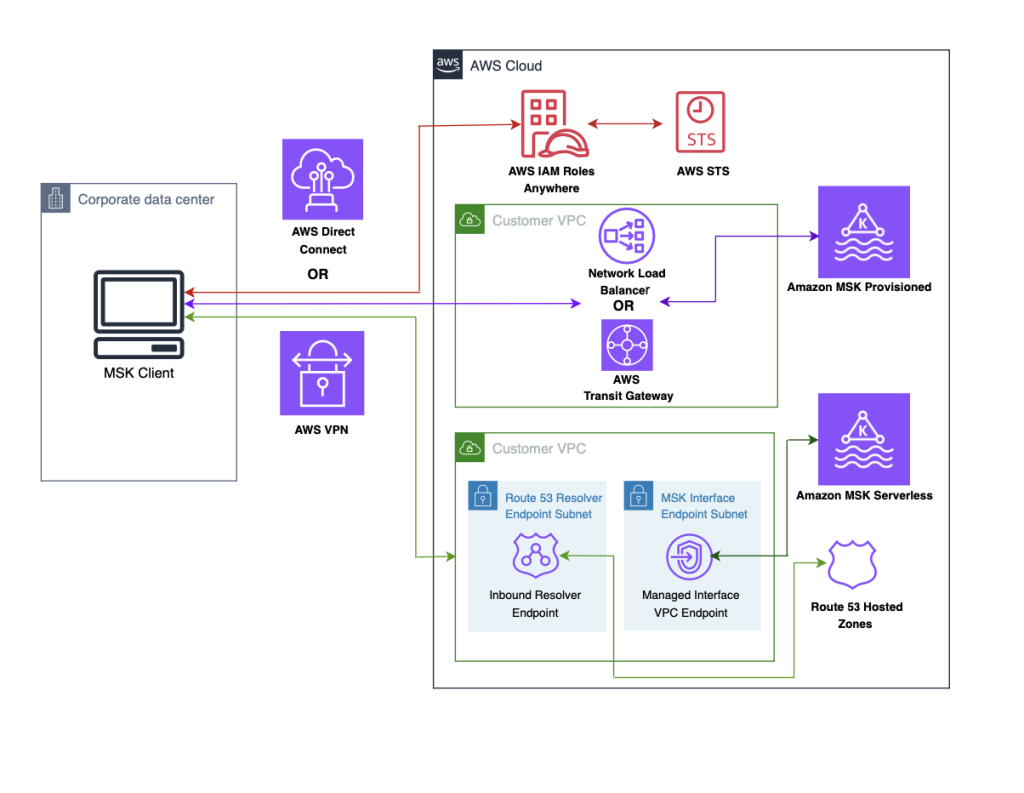
Securely connect Kafka clients running outside AWS to Amazon MSK with IAM Roles Anywhere
In this post, we demonstrate how to use AWS IAM Roles Anywhere to request temporary AWS security credentials, using x.509 certificates for client applications which enables secure interactions with an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster. The solution described in this post is compatible with both Amazon MSK Provisioned and Serverless clusters.

Simplified management of Amazon MSK with natural language using Kiro CLI and Amazon MSK MCP Server
In this post, we demonstrate how Kiro CLI and the MSK MCP server can streamline your Kafka management. Through practical examples and demonstrations, we show you how to use these tools to perform common administrative tasks efficiently while maintaining robust security and reliability.

Unify streaming and analytical data with Amazon Data Firehose and Amazon SageMaker Lakehouse
In this post, we show you how to create Iceberg tables in Amazon SageMaker Unified Studio and stream data to these tables using Firehose. With this integration, data engineers, analysts, and data scientists can seamlessly collaborate and build end-to-end analytics and ML workflows using SageMaker Unified Studio, removing traditional silos and accelerating the journey from data ingestion to production ML models.

Fitch Group achieves multi-Region resiliency for mission-critical Kafka infrastructure with Amazon MSK Replicator
In this post, we explore how Fitch Group, one of the top credit rating companies, used Amazon MSK and Amazon MSK Replicator to achieve multi-Region resiliency for their mission-critical Kafka infrastructure.

Introducing support for Apache Kafka on Raft mode (KRaft) with Amazon MSK clusters
Organizations are adopting Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to capture and analyze data in real time. Amazon MSK helps you build and run production applications on Apache Kafka without needing Kafka infrastructure management expertise or having to deal with the complex overhead associated with setting up and running Apache […]

Build an end-to-end change data capture with Amazon MSK Connect and AWS Glue Schema Registry
The value of data is time sensitive. Real-time processing makes data-driven decisions accurate and actionable in seconds or minutes instead of hours or days. Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real time to a downstream system. […]

Auditing, inspecting, and visualizing Amazon Athena usage and cost
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. It’s a serverless platform with no need to set up or manage infrastructure. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries. You […]