AWS Big Data Blog
Author: Radhika Ravirala

Amazon EMR Serverless cost estimator
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run applications using open-source big data analytics frameworks such as Apache Spark and Hive without configuring, managing, and scaling clusters or servers. You get all the features of the latest open-source frameworks with the performance-optimized […]

Optimize performance and reduce costs for network analytics with VPC Flow Logs in Apache Parquet format
VPC Flow Logs help you understand network traffic patterns, identify security issues, audit usage, and diagnose network connectivity on AWS. Customers often route their VPC flow logs directly to Amazon Simple Storage Service (Amazon S3) for long-term retention. You can then use a custom format conversion application to convert these text files into an Apache […]

Crafting serverless streaming ETL jobs with AWS Glue
Organizations across verticals have been building streaming-based extract, transform, and load (ETL) applications to more efficiently extract meaningful insights from their datasets. Although streaming ingest and stream processing frameworks have evolved over the past few years, there is now a surge in demand for building streaming pipelines that are completely serverless. Since 2017, AWS Glue […]
Easily manage table metadata for Presto running on Amazon EMR using the AWS Glue Data Catalog
In this post, we will explore how the AWS Glue Data Catalog addresses discoverability and manageability for table metadata for Presto on Amazon EMR.
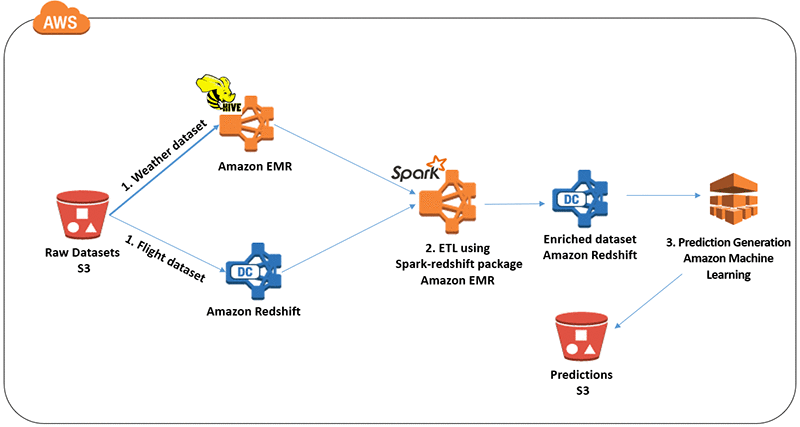
Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning
Air travel can be stressful due to the many factors that are simply out of airline passengers’ control. As passengers, we want to minimize this stress as much as we can. We can do this by using past data to make predictions about how likely a flight will be delayed based on the time of […]