AWS Big Data Blog
Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning
Air travel can be stressful due to the many factors that are simply out of airline passengers’ control. As passengers, we want to minimize this stress as much as we can. We can do this by using past data to make predictions about how likely a flight will be delayed based on the time of day or the airline carrier.
In this post, we generate a predictive model for flight delays that can be used to help us pick the flight least likely to add to our travel stress. To accomplish this, we will use Apache Spark running on Amazon EMR for extracting, transforming, and loading (ETL) the data, Amazon Redshift for analysis, and Amazon Machine Learning for creating predictive models. This solution gives a good example of combining multiple AWS services to build a sophisticated analytical application in the AWS Cloud.
Architecture
At a high level, our solution includes the following steps:
Step 1 is to ingest datasets:
- We will download publicly available Federal Aviation Administration (FAA) flight data and National Oceanic and Atmospheric Administration (NOAA) weather datasets and stage them in Amazon S3.
- Note: A typical big data workload consists of ingesting data from disparate sources and integrating them. To mimic that scenario, we will store the weather data in an Apache Hive table and the flight data in an Amazon Redshift cluster.
Step 2 is to enrich data by using ETL:
- We will transform the maximum and minimum temperature columns from Celsius to Fahrenheit in the weather table in Hive by using a user-defined function in Spark.
- We enrich the flight data in Amazon Redshift to compute and include extra features and columns (departure hour, days to the nearest holiday) that will help the Amazon Machine Learning algorithm’s learning process.
- We then combine both the datasets in the Spark environment by using the spark-redshift package to load data from Amazon Redshift cluster to Spark running on an Amazon EMR cluster. We write the enriched data back to a Amazon Redshift table using the spark-redshift package.
Step 3 is to perform predictive analytics:
- In this last step, we use Amazon Machine Learning to create and train a ML model using Amazon Redshift as our data source. The trained Amazon ML model is used to generate predictions for the test dataset, which are output to an S3 bucket.
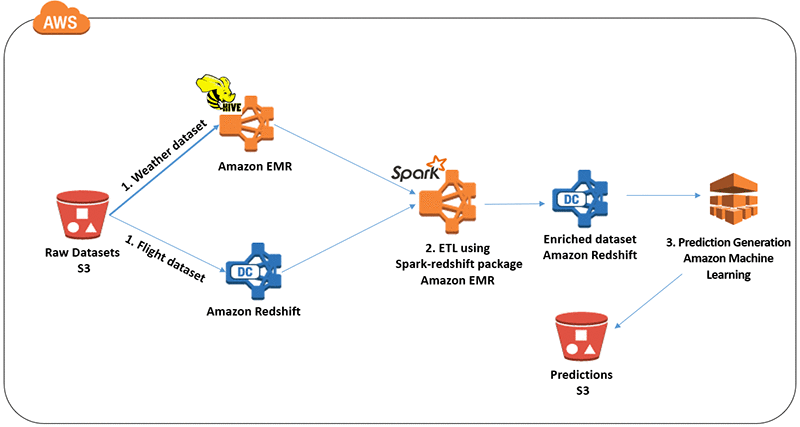
Building the solution
In this example, we use historical weather data for Chicago’s O’Hare International Airport station from 2013 to 2014.
Dataset Download instructions
FAA Data
From the Bureau of Transporation Statistics’ On-Time-Performance data page:
- Set the “Filter Year” to 2013 and “Filter Period” to December.
- You can optionally omit some fields as well. Here are the fields we used for this blog post:
- YEAR
- QUARTER
- MONTH
- DAY_OF_MONTH
- DAY_OF_WEEK
- FL_DATE
- UNIQUE_CARRIER
- AIRLINE_ID
- CARRIER
- TAIL_NUM
- FL_NUM
- ORIGIN_AIRPORT_ID
- ORIGIN
- ORIGIN_CITY_NAME
- ORIGIN_STATE_ABR
- ORIGIN_STATE_NM
- ORIGIN_WAC
- DEST_AIRPORT_ID
- DEST
- DEST_CITY_NAME
- DEST_STATE_ABR
- DEST_STATE_NM
- DEST_WAC
- CRS_DEP_TIME
- DEP_TIME
- DEP_DELAY
- DEP_DELAY_NEW
- DEP_DEL15
- DEP_DELAY_GROUP
- DEP_TIME_BLK
- TAXI_OUT
- TAXI_IN
- CRS_ARR_TIME
- ARR_TIME
- ARR_DELAY
- ARR_DELAY_NEW
- ARR_DEL15
- ARR_DELAY_GROUP
- ARR_TIME_BLK
- CANCELLED
- DIVERTED
- CRS_ELAPSED_TIME
- ACTUAL_ELAPSED_TIME
- AIR_TIME
- FLIGHTS
- DISTANCE
- DISTANCE_GROUP
- CARRIER_DELAY
- WEATHER_DELAY
- NAS_DELAY
- SECURITY_DELAY
- LATE_AIRCRAFT_DELAY
- Click on “Download” on the right hand side.
Weather Data
From the NOAA Climate Data Online: Dataset Discovery page:
- Expand “Daily Summaries” and click on “Search Tool”.
- In the “Climate Data Online Search” form, select a data range (Jan 1st 2013 to Dec 31st 2014).
- Leave “Search For” as Stations.
- Use OHare as the search term. As the blog indicates, we are only interested in weather for flights originating in Chicago’s O’Hare International Airport. Click on “Search”.
- Add the result set to the cart.
- In the cart options, choose “Custom GHCN-Daily CSV” and click on “Continue”.
- Check “Geographic location”.
- In the “Select data types for custom output”, we selected everything for “Precipitation” except “Snow Depth” (SNWD), “Air Temperature”, and just “Average Wind Speed” (AWND) in the wind section.
- You will have to provide an email address to submit the order.
- Once the order is ready, you can download the csv file.
Working with datasets
Let’s begin by launching an EMR cluster with Apache Hive and Apache Spark. We use the following Hive script to create the raw weather table, for which we load the weather data from an S3 bucket in the next step.
CREATE EXTERNAL TABLE IF NOT EXISTS weather_raw (
station string,
station_name string,
elevation string,
latitude string,
longitude string,
wdate string,
prcp decimal(5,1),
snow int,
tmax string,
tmin string,
awnd string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'
LOCATION 's3://<your-bucket>/weather/'
TBLPROPERTIES("skip.header.line.count"="1");
CREATE TABLE weather AS SELECT station, station_name, elevation, latitude, longitude,
cast(concat(
substr(wdate,1,4), '-',
substr(wdate,5,2), '-',
substr(wdate,7,2)
) AS date) AS dt, prcp, snow, tmax, tmin, awnd FROM weather_raw;
set hive.cli.print.header=true;
select * from weather limit 10;Next, we create a single-node Amazon Redshift cluster and copy the flight data from the S3 bucket. Make sure to associate the Amazon Redshift cluster with an AWS Identity and Access Management (IAM) role, which will allow Amazon Redshift to assume a role when reading data from S3.
aws redshift create-cluster \
--cluster-identifier demo \
--db-name demo \
--node-type dc1.large \
--cluster-type single-node \
--iam-roles "arn:aws:iam::YOUR-AWS-ACCOUNT:role/<redshift-iam-role>" \
--master-username master \
--master-user-password REDSHIFT-MASTER-PASSWORD \
--publicly-accessible \
--port 5439
In this example, we will load flight data for flights originating in Chicago’s O’Hare International Airport from 2013 to 2014. You can use most SQL client tools with Amazon Redshift JDBC or ODBC drivers to connect to an Amazon Redshift cluster. For instructions on installing SQL Workbench/J for this use, see the Amazon Redshift documentation.
First, we create a table with data for all flights originating in Chicago in December 2013.
create table ord_flights
(
ID bigint identity(0,1),
YEAR smallint,
QUARTER smallint,
MONTH smallint,
DAY_OF_MONTH smallint,
DAY_OF_WEEK smallint,
FL_DATE date,
UNIQUE_CARRIER varchar(10),
AIRLINE_ID int,
CARRIER varchar(4),
TAIL_NUM varchar(8),
FL_NUM varchar(4),
ORIGIN_AIRPORT_ID smallint,
ORIGIN varchar(5),
ORIGIN_CITY_NAME varchar(35),
ORIGIN_STATE_ABR varchar(2),
ORIGIN_STATE_NM varchar(50),
ORIGIN_WAC varchar(2),
DEST_AIRPORT_ID smallint,
DEST varchar(5),
DEST_CITY_NAME varchar(35),
DEST_STATE_ABR varchar(2),
DEST_STATE_NM varchar(50),
DEST_WAC varchar(2),
CRS_DEP_TIME smallint,
DEP_TIME varchar(6),
DEP_DELAY numeric(22,6),
DEP_DELAY_NEW numeric(22,6),
DEP_DEL15 numeric(22,6),
DEP_DELAY_GROUP smallint,
DEP_TIME_BLK varchar(15),
TAXI_OUT numeric(22,6),
TAXI_IN numeric(22,6),
CRS_ARR_TIME numeric(22,6),
ARR_TIME varchar(6),
ARR_DELAY numeric(22,6),
ARR_DELAY_NEW numeric(22,6),
ARR_DEL15 numeric(22,6),
ARR_DELAY_GROUP smallint,
ARR_TIME_BLK varchar(15),
CANCELLED numeric(22,6),
DIVERTED numeric(22,6),
CRS_ELAPSED_TIME numeric(22,6),
ACTUAL_ELAPSED_TIME numeric(22,6),
AIR_TIME numeric(22,6),
FLIGHTS numeric(22,6),
DISTANCE numeric(22,6),
DISTANCE_GROUP numeric(22,6),
CARRIER_DELAY numeric(22,6),
WEATHER_DELAY numeric(22,6),
NAS_DELAY numeric(22,6),
SECURITY_DELAY numeric(22,6),
LATE_AIRCRAFT_DELAY numeric(22,6),
primary key (id)
);
Next, we ensure that the flight data residing in the S3 bucket is in the same region as the Amazon Redshift cluster. We then run the following copy command.
-- Copy all flight data for Dec 2013 and 2014 from S3 bucket
copy ord_flights
FROM 's3://<path-to-your-faa-data-bucket>/T_ONTIME.csv' credentials 'aws_iam_role=arn:aws:iam::YOUR-AWS-ACCOUNT:role/<RedshiftIAMRole>' csv IGNOREHEADER 1;Data enrichment
Businesses have myriad data sources to integrate, normalize, and make consumable by downstream analytic processes. To add to the complications, ingested data is rarely useful in its original form for analysis. Workflows often involve using either open source tools such as Spark or commercially available tools to enrich the ingested data. In this example, we will perform simple transformations on the weather data to convert the air temperature (tmax and tmin) from Celsius to Fahrenheit using a user-defined function (UDF) in the Spark environment.
Spark
// Read weather table from hive
val rawWeatherDF = sqlContext.table("weather")
// Retrieve the header
val header = rawWeatherDF.first()
// Remove the header from the dataframe
val noHeaderWeatherDF = rawWeatherDF.filter(row => row != header)
// UDF to convert the air temperature from celsius to fahrenheit
val toFahrenheit = udf {(c: Double) => c * 9 / 5 + 32}
// Apply the UDF to maximum and minimum air temperature
val weatherDF = noHeaderWeatherDF.withColumn("new_tmin", toFahrenheit(noHeaderWeatherDF("tmin")))
.withColumn("new_tmax", toFahrenheit(noHeaderWeatherDF("tmax")))
.drop("tmax")
.drop("tmin")
.withColumnRenamed("new_tmax","tmax")
.withColumnRenamed("new_tmin","tmin")Data manipulation also consists of excluding or including data fields and columns that are meaningful to the analysis being performed. Because our analysis tries to predict whether a flight will be delayed or not, we will include only columns that help make that determination.
To that end, we will snip a few columns from the flight table and add ‘departure hour’ and ‘days from the nearest holiday’ columns for data on items that might contribute to flight delay. You can compute the ‘days from the nearest holiday’ by using Amazon Redshift’s user-defined functions (UDFs), which will allow you to write a scalar function in Python 2.7. We also use the Pandas library’s USFederalHolidayCalendar to create a list of federal holidays for the years used in this example (see the code snippet following).
Amazon Redshift UDF
First, create a Python UDF to compute number of days before or after the nearest holiday.
create or replace function f_days_from_holiday (year int, month int, day int)
returns int
stable
as $$
import datetime
from datetime import date
import dateutil
from dateutil.relativedelta import relativedelta
fdate = date(year, month, day)
fmt = '%Y-%m-%d'
s_date = fdate - dateutil.relativedelta.relativedelta(days=7)
e_date = fdate + relativedelta(months=1)
start_date = s_date.strftime(fmt)
end_date = e_date.strftime(fmt)
"""
Compute a list of holidays over a period (7 days before, 1 month after) for the flight date
"""
from pandas.tseries.holiday import USFederalHolidayCalendar
calendar = USFederalHolidayCalendar()
holidays = calendar.holidays(start_date, end_date)
days_from_closest_holiday = [(abs(fdate - hdate)).days for hdate in holidays.date.tolist()]
return min(days_from_closest_holiday)
$$ language plpythonu;We are now ready to combine the weather data in Hive table with the flights data in our Amazon Redshift table using the spark-redshift package, to demonstrate the data enrichment process.
Working with the spark-redshift package
Databrick’s spark-redshift package is a library that loads data into Spark SQL DataFrames from Amazon Redshift and also saves DataFrames back into Amazon Redshift tables. The library uses the Spark SQL Data Sources API to integrate with Amazon Redshift. This approach makes it easy to integrate large datasets from a Amazon Redshift database with datasets from other data sources and to interoperate seamlessly with disparate input sources like Hive tables, as in this use case, or columnar Parquet files on HDFS or S3, and many others.
The following is an illustration of spark-redshift’s load and save functionality:

Prerequisites
To work with spark-redshift package, you will need to download the following .jar files onto your EMR cluster running spark. Alternatively, you can clone the git repository and build the .jar files from the sources. For this example, we ran EMR version 5.0 with Spark 2.0. Ensure that you download the right versions of the .jar files based on the version of Spark you use.
spark-redshift jar
wget http://repo1.maven.org/maven2/com/databricks/spark-redshift_2.10/2.0.0/spark-redshift_2.10-2.0.0.jarspark-avro jar
wget http://repo1.maven.org/maven2/com/databricks/spark-avro_2.11/3.0.0/spark-avro_3.0.0.jarminimal-json.jar
wget https://github.com/ralfstx/minimal-json/releases/download/0.9.4/minimal-json-0.9.4.jarIn addition to the .jar file described preceding, you will also need the Amazon Redshift JDBC driver to connect to the Amazon Redshift cluster. Fortunately, the driver is already included in EMR version 4.7.0 and above.
Connecting to Amazon Redshift cluster from your Spark environment
Launch spark-shell with the prerequisites downloaded from the previous section.
spark-shell --jars spark-redshift_2.10-2.0.0.jar,/usr/share/aws/redshift/jdbc/RedshiftJDBC41.jar,minimal-json-0.9.4.jar,spark-avro_2.11-3.0.0.jarOnce in spark-shell, we run through the following steps to connect to our Amazon Redshift cluster.
/**
* Example to demonstrate combining tables in Hive and Amazon Redshift for data enrichment.
*/
import org.apache.spark.sql._
import com.amazonaws.auth._
import com.amazonaws.auth.AWSCredentialsProvider
import com.amazonaws.auth.AWSSessionCredentials
import com.amazonaws.auth.InstanceProfileCredentialsProvider
import com.amazonaws.services.redshift.AmazonRedshiftClient
import _root_.com.amazon.redshift.jdbc41.Driver
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.SQLContext
// Instance Profile for authentication to AWS resources
val provider = new InstanceProfileCredentialsProvider();
val credentials: AWSSessionCredentials = provider.getCredentials.asInstanceOf[AWSSessionCredentials];
val token = credentials.getSessionToken;
val awsAccessKey = credentials.getAWSAccessKeyId;
val awsSecretKey = credentials.getAWSSecretKey
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._;
// Read weather table from hive
val rawWeatherDF = sqlContext.table("weather")
// Retrieve the header
val header = rawWeatherDF.first()
// Remove the header from the dataframe
val noHeaderWeatherDF = rawWeatherDF.filter(row => row != header)
// UDF to convert the air temperature from celsius to fahrenheit
val toFahrenheit = udf {(c: Double) => c * 9 / 5 + 32}
// Apply the UDF to maximum and minimum air temperature
val weatherDF = noHeaderWeatherDF.withColumn("new_tmin", toFahrenheit(noHeaderWeatherDF("tmin")))
.withColumn("new_tmax", toFahrenheit(noHeaderWeatherDF("tmax")))
.drop("tmax")
.drop("tmin")
.withColumnRenamed("new_tmax","tmax")
.withColumnRenamed("new_tmin","tmin")
// Provide the jdbc url for Amazon Redshift
val jdbcURL = "jdbc:redshift://<redshift-cluster-name>:<port/<database-name>?user=<dbuser>&password=<dbpassword>"
// Create and declare an S3 bucket where the temporary files are written
val s3TempDir = "s3://<S3TempBucket>/"Reading from Amazon Redshift
To read from Amazon Redshift, spark-redshift executes a Amazon Redshift UNLOAD command that copies a Amazon Redshift table or results from a query to a temporary S3 bucket that you provide. Then spark-redshift reads the temporary S3 input files and generates a DataFrame instance that you can manipulate in your application.
In this case, we will issue a SQL query against the ord_flights table in the Amazon Redshift cluster from Spark to read only the columns we are interested in. Notice that during this process, we are computing the days_to_holiday column using the Amazon Redshift UDF that we discussed in the earlier section.
// Query against the ord_flights table in Amazon Redshift
val flightsQuery = """
select ORD_DELAY_ID, DAY_OF_MONTH, DAY_OF_WEEK, FL_DATE, f_days_from_holiday(year, month, day_of_month) as DAYS_TO_HOLIDAY, UNIQUE_CARRIER, FL_NUM, substring(DEP_TIME, 1, 2) as DEP_HOUR, cast(DEP_DEL15 as smallint),
cast(AIR_TIME as integer), cast(FLIGHTS as smallint), cast(DISTANCE as smallint)
from flights where origin='ORD' and cancelled = 0
"""
// Create a Dataframe to hold the results of the above query
val flightsDF = sqlContext.read.format("com.databricks.spark.redshift")
.option("url", jdbcURL)
.option("tempdir", s3TempDir)
.option("query", flightsQuery)
.option("temporary_aws_access_key_id", awsAccessKey)
.option("temporary_aws_secret_access_key", awsSecretKey)
.option("temporary_aws_session_token", token).load()It’s join time!
// Join the two dataframes
val joinedDF = flightsDF.join(weatherDF, flightsDF("fl_date") === weatherDF("dt"))
Now that we have unified the data, we can write it back to another table in our Amazon Redshift cluster. After that is done, the table can serve as a datasource for advanced analytics, such as for developing predictive models using the Amazon Machine Learning service.
Writing to Amazon Redshift
To write to Amazon Redshift, the spark-redshift library first creates a table in Amazon Redshift using JDBC. Then it copies the partitioned DataFrame as AVRO partitions to a temporary S3 folder that you specify. Finally, it executes the Amazon Redshift COPY command to copy the S3 contents to the newly created Amazon Redshift table. You can also use the append option with spark-redshift to append data to an existing Amazon Redshift table. In this example, we will write the data to a table named ‘ord_flights’ in Amazon Redshift.
joinedDF.write
.format("com.databricks.spark.redshift")
.option("temporary_aws_access_key_id", awsAccessKey)
.option("temporary_aws_secret_access_key", awsSecretKey)
.option("temporary_aws_session_token", token)
.option("url", jdbcURL)
.option("dbtable", "ord_flights")
.option("aws_iam_role", "arn:aws:iam::<AWS-account>:role/<redshift-role>")
.option("tempdir", s3TempDir)
.mode("error")
.save()
Let us derive a couple of tables in Amazon Redshift from ord_flights to serve as the training and test input datasets for Amazon ML.
-- Derived table for training data
create table train_ord_flights
as
(select * from ord_flights where year = 2013);
select count(*) from train_ord_flights;
-- Derived table for test data
create table test_ord_flights
as
(select * from ord_flights where year = 2013);
select count(*) from test_ord_flights;
Connecting Amazon Redshift to Amazon ML
With processed data on hand, we can perform advanced analytics, such as forecasting future events or conducting what-if analysis to understand their effect on business outcomes.
We started with a goal of predicting flight delays for future flights. However, because future flight data is not available, we will use the unified flight and weather data for December 2013 to create and train a predictive model using Amazon ML. We’ll then use December 2014 data as our test dataset, on which we apply the predictive model to get the batch predictions. We can then compare the generated batch predictions against the actual delays (because we already know the 2014 delays) and determine the accuracy of the model that we have developed.
The predictive model creation here will use the AWS Management Console, but you can also use the AWS CLI or one of the AWS SDKs to accomplish the same thing.
Create an Amazon ML Datasource
The first step in developing an Amazon ML model is creation of a datasource object. We will create a datasource object in Amazon ML by issuing a query against the Amazon Redshift cluster to use December 2013 data as our training dataset. Amazon ML automatically infers the schema based on the values of the columns in the query. You can optionally specify a schema if you want.
In our case, we select departure delay (dep_del15) as the target attribute to predict. When the datasource object is created, Amazon ML shows the target distribution, missing values, and statistics for each of attributes for the datasource object you just created.

Create an Amazon Machine Learning Model
After creating the datasource object, we are ready to create and train an ML model. Select the datasource you just created in previous section and follow the instructions to create the model.
When the model is successfully created, choose Latest evaluation result to learn how the model scored. Amazon ML provides an industry standard accuracy metric for binary classification models called “Area Under the (Receiver Operating Characteristic) Curve (AUC).”

For insights into prediction accuracy, see performance visualization, where the effect of choosing the cut-off score (threshold) can be understood. The prediction score for each record is a numeric value between 0 and 1. The closer to 1, the more likely the prediction should be set to Yes; the further away, the more likely is No. A prediction falls into one of the four cases: a) True-positive (TP)—correctly classified as Yes; b) True-negative (TN)—correctly classified as No; c) False-positive (FP)—wrongly classified as Yes; d) False-negative (TN)—wrongly classified as No.
In this example, False positive indicates flights that are not delayed are reported as delayed, which may cause passengers to miss their flight. False negative means flights that are delayed are classified as being not delayed, which is just an annoyance. We want to minimize the false positives in this model by simply adjusting the threshold to a higher value.

Generate batch predictions
To generate batch predictions, take the two steps following.
Create a Datasource object for the test dataset
Repeat the datasource object creation in Amazon ML as we did in the earlier section to create a test dataset on which model will be deployed. Make sure to use the December 2014 data for the Amazon Redshift query.
Create batch predictions
From the Amazon Machine Learning console, choose Batch Predictions and follow the instructions to create batch predictions by applying the model we created in the last section on the test dataset. Predictions can be located in the “Output S3 URL” path on the summary page. The predictions can be copied back to a Amazon Redshift table and correlated with other flight data to produce visualizations. Such visualizations provide insights such as days and times when the flights are most delayed, carriers that have had delays during holidays, and so on.

Congratulations! You have successfully generated a flight delay forecast for December 2014!
Conclusion
In this post, we built an end-to-end solution for predicting flight delays by combining multiple AWS services—Apache Spark on Amazon EMR, Amazon Redshift, and Amazon ML. We started out with raw data, combined data in Spark with Amazon Redshift using the spark-redshift package, processed data using constructs such as UDFs, and developed a forecasting model for flight delays using Amazon ML. This ability to seamlessly integrate these services truly empowers users to build sophisticated analytical applications on the AWS cloud. We encourage you to build your own and share your experience with us!
About the Authors
 Radhika Ravirala is a Solutions Architect at Amazon Web Services where she helps customers craft distributed, robust cloud applications on the AWS platform. Prior to her cloud journey, she worked as a software engineer and designer for technology companies in Silicon Valley. She enjoys spending time with her family, walking her dog, warrior xfit and an occasional hand at Smash bros.
Radhika Ravirala is a Solutions Architect at Amazon Web Services where she helps customers craft distributed, robust cloud applications on the AWS platform. Prior to her cloud journey, she worked as a software engineer and designer for technology companies in Silicon Valley. She enjoys spending time with her family, walking her dog, warrior xfit and an occasional hand at Smash bros.

Wangechi Doble is a Solutions Architect with a focus on Big Data & Analytics at AWS. She helps customers architect and build out high performance, scalable and secure cloud-based solutions on AWS. In her spare time, she enjoys spending time with her family, reading and traveling to exotic places.
Related
Serving Real-Time Machine Learning Predictions on Amazon EMR
