AWS Big Data Blog
Tag: Amazon Machine Learning

Decreasing Game Churn: How Upopa used ironSource Atom and Amazon ML to Engage Users
This is a guest post by Tom Talpir, Software Developer at ironSource. ironSource is as an Advanced AWS Partner Network (APN) Technology Partner and an AWS Big Data Competency Partner. Ever wondered what it takes to keep a user from leaving your game or application after all the hard work you put in? Wouldn’t it be great […]
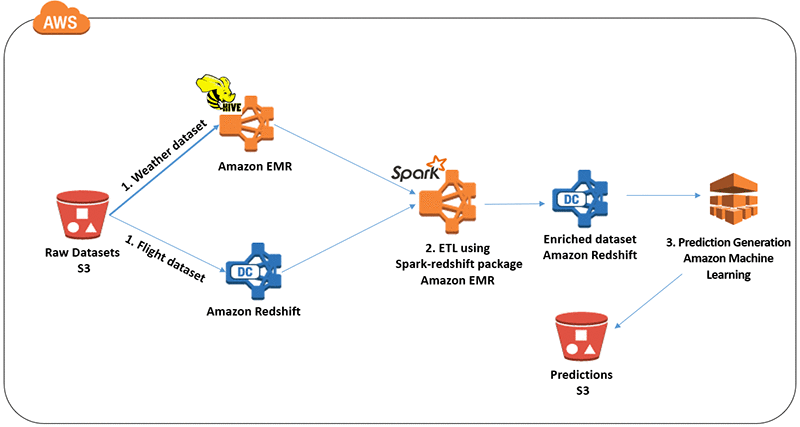
Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning
Air travel can be stressful due to the many factors that are simply out of airline passengers’ control. As passengers, we want to minimize this stress as much as we can. We can do this by using past data to make predictions about how likely a flight will be delayed based on the time of […]

Serving Real-Time Machine Learning Predictions on Amazon EMR
The typical progression for creating and using a trained model for recommendations falls into two general areas: training the model and hosting the model. Model training has become a well-known standard practice. We want to highlight one of many ways to host those recommendations (for example, see the Analyzing Genomics Data at Scale using R, […]

Readmission Prediction Through Patient Risk Stratification Using Amazon Machine Learning
In this post, I show how to apply advanced analytics concepts like pattern analysis and machine learning to do risk stratification for patient cohorts.

Large-Scale Machine Learning with Spark on Amazon EMR
This is a guest post by Jeff Smith, Data Engineer at Intent Media. Intent Media, in their own words: “Intent Media operates a platform for advertising on commerce sites. We help online travel companies optimize revenue on their websites and apps through sophisticated data science capabilities. On the data team at Intent Media, we are […]

Building a Binary Classification Model with Amazon Machine Learning and Amazon Redshift
Guy Ernest is a Solutions Architect with AWS This post builds on Guy’s earlier posts Building a Numeric Regression Model with Amazon Machine Learning and Building a Multi-Class ML Model with Amazon Machine Learning. Many decisions in life are binary, answered either Yes or No. Many business problems also have binary answers. For example: “Is […]
Building a Multi-Class ML Model with Amazon Machine Learning
Guy Ernest is a Solutions Architect with AWS This post builds on our earlier post Building a Numeric Regression Model with Amazon Machine Learning. We often need to assign an object (product, article, or customer) to its class (product category, article topic or type, or customer segment). For example, which category of products is most […]
Building a Numeric Regression Model with Amazon Machine Learning
Guy Ernest is a Solutions Architect with AWS We need to predict future values in our businesses. These predictions are important for better planning of resource allocation and making other business decisions. Often, we settle for a simplified heuristic of average values from the past and some change assumption because more accurate alternatives are too […]
Building a Recommender with Apache Mahout on Amazon Elastic MapReduce (EMR)
This is a guest post by Andrew Musselman, who as chief data scientist leads the global big data practice from the technical side at Accenture. He is a PMC member on the Apache Mahout project and is writing a book on data science for O’Reilly. Accenture is an APN Big Data Competency Partner. This post […]