AWS Big Data Blog
Decreasing Game Churn: How Upopa used ironSource Atom and Amazon ML to Engage Users
This is a guest post by Tom Talpir, Software Developer at ironSource. ironSource is as an Advanced AWS Partner Network (APN) Technology Partner and an AWS Big Data Competency Partner.
Ever wondered what it takes to keep a user from leaving your game or application after all the hard work you put in? Wouldn’t it be great to get a chance to interact with the users before they’re about to leave?
Finding these users can be difficult, mainly because most churn happens within the first few minutes or hours of a user’s gameplay. However, machine learning (ML) can make this possible by providing insights to help developers identify these users and engage with them to decrease the churn rate.
Upopa is a gaming studio that creates cool games (that you should definitely check out), and they were a great fit for our new project, leveraging Amazon Machine Learning (Amazon ML) to offer game developers an ability to predict the future actions of their players, and ultimately reduce churn without having to learn the complex ML algorithms.

Upopa sends all their data to Amazon Redshift, using ironSource Atom, a data flow management solution that allows developers to send data from their application into many different types of data targets (including Amazon Redshift, Amazon S3, Amazon OpenSearch, and other relational databases) with great ease.
Amazon ML turned out to be the right solution for Upopa, because it integrates easily with Amazon Redshift, and makes everything much easier with visualization tools and wizards that guides you through the process of creating ML models.
Building a model
First and foremost, Upopa needed to define the training data — data that the ML algorithm can learn from. Defining this training data for building a model happened to be the hardest part, for several reasons.
To predict the churn, the training data needed was both the user’s data from the game (games played, games lost, victories, purchases, and so on), and a correct “answer” for each user (that is, did the user end up leaving the game or not). After examining historic data with Upopa’s developers and data analysts, we decided that every user who hasn’t played for more than 14 days is considered a user who left. This raises another question: what’s the minimum amount of data that we need to gather on each user so that we have enough data to make a prediction? Again, after consulting with Upopa’s developers and data analysts, we decided that 3 hours of data should suffice.
The data in Amazon Redshift was saved as raw events, directly from the game using ironSource Atom. This meant that every action the user makes is stored as a single row. But for training data on the other hand, we needed data to be about every user. So, we needed to aggregate the data, and make it about every interesting action a user takes in the game — their total number of victories, purchases, time spent playing, etc.
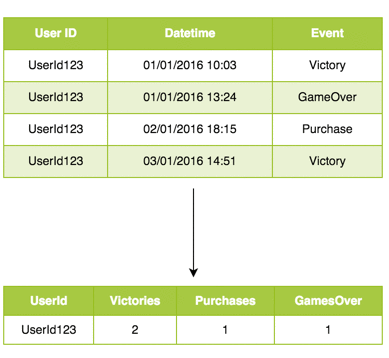
Generating training data
With the training dataset defined, aggregating data was an engineering task, for which we ended up using our experience with SQL. For example, calculating the actions that a player makes was done using a simple trick combining mathematical functions with a CASE clause:
SELECT
sum(CASE WHEN event = 'Victory'
THEN 1
ELSE 0
END) AS wins,
sum(CASE WHEN event = 'GameOver'
THEN 1
ELSE 0
END) AS losses,
max(CASE WHEN event = 'GameLevel'
THEN level
ELSE 0
END) AS max_level
Calculations that involved dates and times, on the other hand, were a bit trickier. To simplify the SQL queries and reuse calculations, extensive use of the WITH clause was made. For example, the first event for every user was defined using the WITH clause:
WITH users_first_event AS (
SELECT
udid,
min(datetime) AS first_event_time
FROM game_events
GROUP BY udid
)
The above example shows how we used the time of the first event (calculated in the previous example), to calculate the amount of time spent in-game by the user, in only the first three hours!
WITH user_time_data AS (
SELECT
sub.udid AS udid,
count(DISTINCT sub.sessionId) AS total_sessions,
sum(sub.session_length) AS total_game_time, /* Sum the length of all sessions to get the total game time */
datediff(second, min(sub.start_time), max(sub.end_time)) AS absolute_total_time /* Calculate the time between the first and last events*/
FROM (
/* Gather data that will help us calculate the time a user spends playing, in the parent query*/
SELECT
events.udid,
events.sessionId,
MIN(events.datetime) start_time,
MAX(events.datetime) end_time,
datediff(second, MIN(events.datetime), MAX(events.datetime)) session_length
FROM game_events events
/* We JOIN the previous WITH clause, to get the absolute first event of the user. We need the first event
so we can limit this query to the first 3 hours of user-data (since that's what our model is based on).
We can't get that data solely from this query, since this query is grouped by both user ID AND session ID,
which gives us data on specific sessions, not overall game-time */
INNER JOIN users_first_event first_event_data
ON first_event_data.udid = events.udid
AND events.datetime >= first_event_data.first_event_time
AND events.datetime <= first_event_data.first_event_time + INTERVAL '3 hour' /* Limit data to the first 3 hours */
GROUP BY events.udid, events.sessionId
) sub
GROUP BY sub.udid
)
After the training data was defined using a DataSource, Amazon ML did its magic and created an ML model for us.
Making predictions
To manage the whole data prediction flow, our team wrapped the ML model with two microservices written in Go:
- Discoverer
- Predictor
These Atom services were an integral part of the churn prediction for Upopa.
The first service, Discoverer, has a fairly simple job — to discover new users as soon as possible and keep track of all the users that have previously been discovered. The pipeline built using Atom constantly inserts new data to the data warehouse, and Discoverer keeps searching for new users with a few simple SQL queries.

The second service, Predictor, manages the actual prediction process. Whenever Discoverer finds new users, Predictor gathers data on these users and uses the ML model to predict their future actions quickly. After a prediction is obtained, Predictor sends an alert to an Amazon SNS topic, to which the game engine can subscribe.
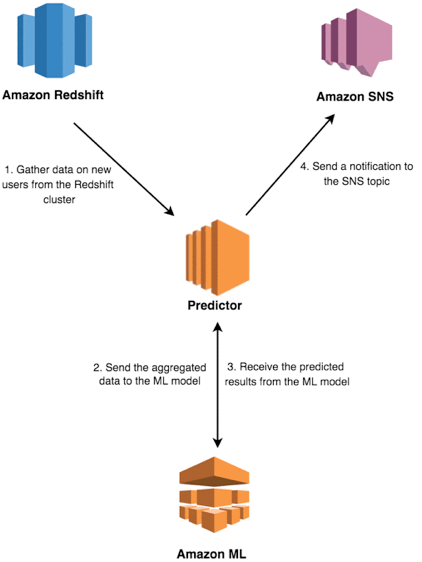
Now, whenever the game engine receives a “call to action” from the SNS topic, it makes a special offer to users to persuade them to stay in the game.

Accuracy
One of the concerns that our team and Upopa both had was how accurate the ML model generated by Amazon would be compared to a model specially crafted by a data scientist for a specific problem.
We were very happy to learn that this specific churn model, along with other models that we created for other projects, yielded great results. The accuracy of these models was measured using AUC and RMSE metrics (industry standards in the machine learning world), and compared to prediction results and success rates from manually created models by data scientists.

Not only were the metrics good, in certain cases, the Amazon ML models achieved even better prediction results than the R models created by data scientists!
However, these measures and scores don’t mean much if they can’t be translated to actual value. Upopa discovered that the model managed to increase the average time a player spends in the game, which has a tremendous impact for any game developer!
Wrapping up
This is how, by combining ironSource Atom’s data pipeline and Amazon ML, our team managed to build an efficient, cheap, and accurate way to battle churn and make data-driven decisions in applications and games. We had a great time working on this project with Upopa, and learned a lot during the process.
If you have questions or suggestions, please comment below.
Related
Building an Event-Based Analytics Pipeline for Amazon Game Studios’ Breakaway
