AWS Big Data Blog
Author: Nivas Shankar

Build a modern data architecture and data mesh pattern at scale using AWS Lake Formation tag-based access control
September 2024: This post was reviewed and updated to use version 4 of the settings for AWS Lake Formation, which allows for cross-account grants with AWS Resource Access Manager and hybrid access mode. Customers are exploring building a data mesh on their AWS platform using AWS Lake Formation and sharing their data lakes across the […]

Easily manage your data lake at scale using AWS Lake Formation Tag-based access control
Thousands of customers are building petabyte-scale data lakes on AWS. Many of these customers use AWS Lake Formation to easily build and share their data lakes across the organization. As the number of tables and users increase, data stewards and administrators are looking for ways to manage permissions on data lakes easily at scale. Customers […]

Design a data mesh architecture using AWS Lake Formation and AWS Glue
April 2024: This post was reviewed for accuracy. Organizations of all sizes have recognized that data is one of the key enablers to increase and sustain innovation, and drive value for their customers and business units. They are eagerly modernizing traditional data platforms with cloud-native technologies that are highly scalable, feature-rich, and cost-effective. As you […]

Tune Hadoop and Spark performance with Dr. Elephant and Sparklens on Amazon EMR
This post demonstrates how to install Dr. Elephant and Sparklens on an Amazon EMR cluster and run workloads to demonstrate these tools’ capabilities. Amazon EMR is a managed Hadoop service offered by AWS to easily and cost-effectively run Hadoop and other open-source frameworks on AWS.
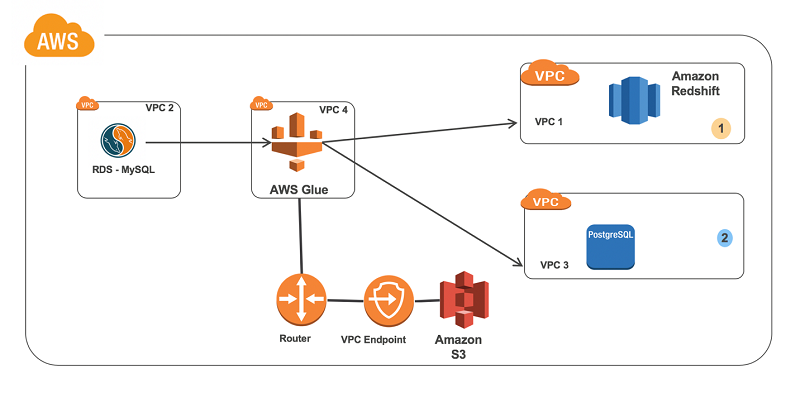
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.

Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).