AWS Big Data Blog

Author: Srividya Parthasarathy
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
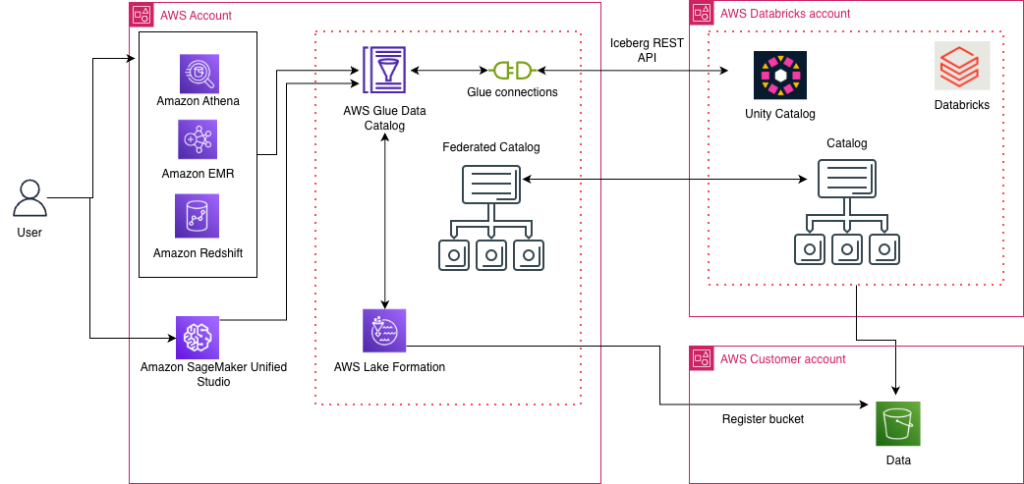
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.

Access Apache Iceberg tables in Amazon S3 from Databricks using AWS Glue Iceberg REST Catalog in Amazon SageMaker Lakehouse
In this post, we will show you how Databricks on AWS general purpose compute can integrate with the AWS Glue Iceberg REST Catalog for metadata access and use Lake Formation for data access. To keep the setup in this post straightforward, the Glue Iceberg REST Catalog and Databricks cluster share the same AWS account.

Simplify data access for your enterprise using Amazon SageMaker Lakehouse
Amazon SageMaker Lakehouse offers a unified solution for enterprise data access, combining data from warehouses and lakes. This post demonstrates how SageMaker Lakehouse integrates scattered data sources, enabling secure enterprise-wide access, and allowing teams to use their preferred tools for predicting and analyzing customer churn. The solution involves multiple data sources, including Amazon S3, Amazon Redshift, and AWS Glue Data Catalog, with AWS Lake Formation managing permissions.

Efficiently crawl your data lake and improve data access with an AWS Glue crawler using partition indexes
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) data lakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems. AWS Glue crawlers provide a straightforward way to catalog data in the AWS Glue Data […]

Build an AWS Lake Formation permissions inventory dashboard using AWS Glue and Amazon QuickSight
AWS Lake Formation makes it easier to centrally govern, secure, and share data for analytics with familiar database-style grant features managed through the Glue Data Catalog. Lake Formation provides a single place to define fine-grained access control on catalog resources. These permissions are granted to the principals by a data lake admin, and integrated engines […]

Centrally manage access and permissions for Amazon Redshift data sharing with AWS Lake Formation
Today’s global, data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. Amazon Redshift data sharing allows you to securely share live, transactionally consistent data in one Amazon Redshift data warehouse with another Amazon Redshift data warehouse within the same AWS […]