AWS Big Data Blog
Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. AWS has many services to build solutions with an event-driven architecture, such as Amazon EventBridge, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), and AWS Lambda.
Amazon Elastic Kubernetes Service (Amazon EKS) is becoming a popular choice among AWS customers to host long-running analytics and AI or machine learning (ML) workloads. By containerizing your data processing tasks, you can simply deploy them into Amazon EKS as Kubernetes jobs and use Kubernetes to manage underlying computing compute resources. For big data processing, which requires distributed computing, you can use Spark on Amazon EKS. Amazon EMR on EKS, a managed Spark framework on Amazon EKS, enables you to run Spark jobs with benefits of scalability, portability, extensibility, and speed. With EMR on EKS, the Spark jobs run using the Amazon EMR runtime for Apache Spark, which increases the performance of your Spark jobs so that they run faster and cost less than open-source Apache Spark.
Data processes require a workflow management to schedule jobs and manage dependencies between jobs, and require monitoring to ensure that the transformed data is always accurate and up to date. One popular orchestration tool for managing workflows is Apache Airflow, which can be installed in Amazon EKS. Alternatively, you can use the AWS-managed version, Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Another option is to use AWS Step Functions, which is a serverless workflow service that integrates with EMR on EKS and EventBridge to build event-driven workflows.
In this post, we demonstrate how to build an event-driven data pipeline using AWS Controllers for Kubernetes (ACK) and EMR on EKS. We use ACK to provision and configure serverless AWS resources, such as EventBridge and Step Functions. Triggered by an EventBridge rule, Step Functions orchestrates jobs running in EMR on EKS. With ACK, you can use the Kubernetes API and configuration language to create and configure AWS resources the same way you create and configure a Kubernetes data processing job. Because most of the managed services are serverless, you can build and manage your entire data pipeline using the Kubernetes API with tools such as kubectl.
Solution overview
ACK lets you define and use AWS service resources directly from Kubernetes, using the Kubernetes Resource Model (KRM). The ACK project contains a series of service controllers, one for each AWS service API. With ACK, developers can stay in their familiar Kubernetes environment and take advantage of AWS services for their application-supporting infrastructure. In the post Microservices development using AWS controllers for Kubernetes (ACK) and Amazon EKS blueprints, we show how to use ACK for microservices development.
In this post, we show how to build an event-driven data pipeline using ACK controllers for EMR on EKS, Step Functions, EventBridge, and Amazon Simple Storage Service (Amazon S3). We provision an EKS cluster with ACK controllers using Terraform modules. We create the data pipeline with the following steps:
- Create the emr-data-team-a namespace and bind it with the virtual cluster my-ack-vc in Amazon EMR by using the ACK controller.
- Use the ACK controller for Amazon S3 to create an S3 bucket. Upload the sample Spark scripts and sample data to the S3 bucket.
- Use the ACK controller for Step Functions to create a Step Functions state machine as an EventBridge rule target based on Kubernetes resources defined in YAML manifests.
- Use the ACK controller for EventBridge to create an EventBridge rule for pattern matching and target routing.
The pipeline is triggered when a new script is uploaded. An S3 upload notification is sent to EventBridge and, if it matches the specified rule pattern, triggers the Step Functions state machine. Step Functions calls the EMR virtual cluster to run the Spark job, and all the Spark executors and driver are provisioned inside the emr-data-team-a namespace. The output is saved back to the S3 bucket, and the developer can check the result on the Amazon EMR console.
The following diagram illustrates this architecture.

Prerequisites
Ensure that you have the following tools installed locally:
Deploy the solution infrastructure
Because each ACK service controller requires different AWS Identity and Access Management (IAM) roles for managing AWS resources, it’s better to use an automation tool to install the required service controllers. For this post, we use Amazon EKS Blueprints for Terraform and the AWS EKS ACK Addons Terraform module to provision the following components:
- A new VPC with three private subnets and three public subnets
- An internet gateway for the public subnets and a NAT Gateway for the private subnets
- An EKS cluster control plane with one managed node group
- Amazon EKS-managed add-ons:
VPC_CNI,CoreDNS, andKube_Proxy - ACK controllers for EMR on EKS, Step Functions, EventBridge, and Amazon S3
- IAM execution roles for EMR on EKS, Step Functions, and EventBridge
Let’s start by cloning the GitHub repo to your local desktop. The module eks_ack_addons in addon.tf is for installing ACK controllers. ACK controllers are installed by using helm charts in the Amazon ECR public galley. See the following code:
The following screenshot shows an example of our output. emr_on_eks_role_arn is the ARN of the IAM role created for Amazon EMR running Spark jobs in the emr-data-team-a namespace in Amazon EKS. stepfunction_role_arn is the ARN of the IAM execution role for the Step Functions state machine. eventbridge_role_arn is the ARN of the IAM execution role for the EventBridge rule.

The following command updates kubeconfig on your local machine and allows you to interact with your EKS cluster using kubectl to validate the deployment:
Test your access to the EKS cluster by listing the nodes:
Now we’re ready to set up the event-driven pipeline.
Create an EMR virtual cluster
Let’s start by creating a virtual cluster in Amazon EMR and link it with a Kubernetes namespace in EKS. By doing that, the virtual cluster will use the linked namespace in Amazon EKS for running Spark workloads. We use the file emr-virtualcluster.yaml. See the following code:
Let’s apply the manifest by using the following kubectl command:
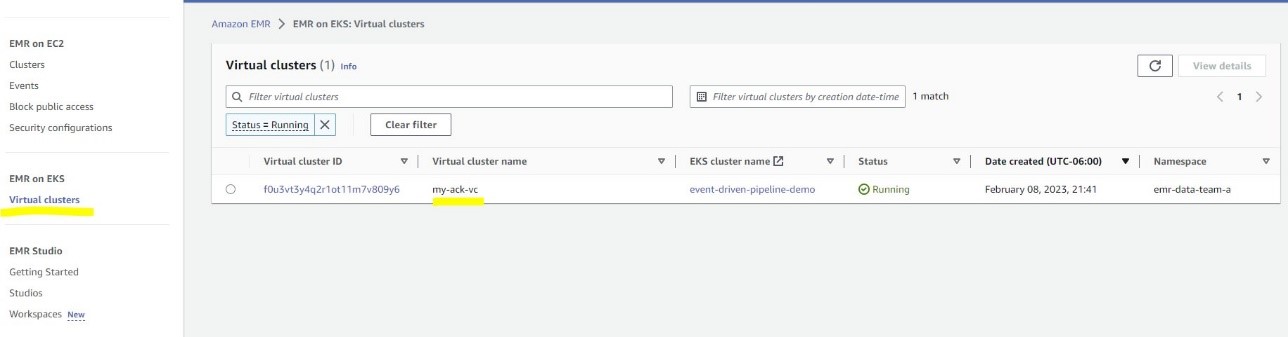
You can navigate to the Virtual clusters page on the Amazon EMR console to see the cluster record.
Create an S3 bucket and upload data
Next, let’s create a S3 bucket for storing Spark pod templates and sample data. We use the s3.yaml file. See the following code:
s3.yaml as well as in eventbridge.yaml and sfn.yaml. You also need to update upload-inputdata.sh and upload-spark-scripts.sh with the new bucket name.
Run the following command to upload the input data and pod templates:
The amzn-s3-demo-bucket S3 bucket is created with two folders: input and scripts.
Create a Step Functions state machine
The next step is to create a Step Functions state machine that calls the EMR virtual cluster to run a Spark job, which is a sample Python script to process the New York City Taxi Records dataset. You need to define the Spark script location and pod templates for the Spark driver and executor in the StateMachine object .yaml file. Let’s make the following changes (highlighted) in sfn.yaml first:
- Replace the value for
roleARNwithstepfunctions_role_arn - Replace the value for
ExecutionRoleArnwithemr_on_eks_role_arn - Replace the value for
VirtualClusterIdwith your virtual cluster ID - Optionally, replace
amzn-s3-demo-bucketwith your bucket name
See the following code:
You can get your virtual cluster ID from the Amazon EMR console or with the following command:
Then apply the manifest to create the Step Functions state machine:
Create an EventBridge rule
The last step is to create an EventBridge rule, which is used as an event broker to receive event notifications from Amazon S3. Whenever a new file, such as a new Spark script, is created in the S3 bucket, the EventBridge rule will evaluate (filter) the event and invoke the Step Functions state machine if it matches the specified rule pattern, triggering the configured Spark job.
Let’s use the following command to get the ARN of the Step Functions state machine we created earlier:
Then, update eventbridge.yaml with the following values:
- Under targets, replace the value for roleARN with
eventbridge_role_arn
Under targets, replace arn with your sfn_arn
- Optionally, in eventPattern, replace
amzn-s3-demo-bucketwith your bucket name
See the following code:
By applying the EventBridge configuration file, an EventBridge rule is created to monitor the folder scripts in the S3 bucket amzn-s3-demo-bucket:
For simplicity, the dead-letter queue is not set and maximum retry attempts is set to 0. For production usage, set them based on your requirements. For more information, refer to Event retry policy and using dead-letter queues.
Test the data pipeline
To test the data pipeline, we trigger it by uploading a Spark script to the S3 bucket scripts folder using the following command:
The upload event triggers the EventBridge rule and then calls the Step Functions state machine. You can go to the State machines page on the Step Functions console and choose the job run-spark-job-ack to monitor its status.

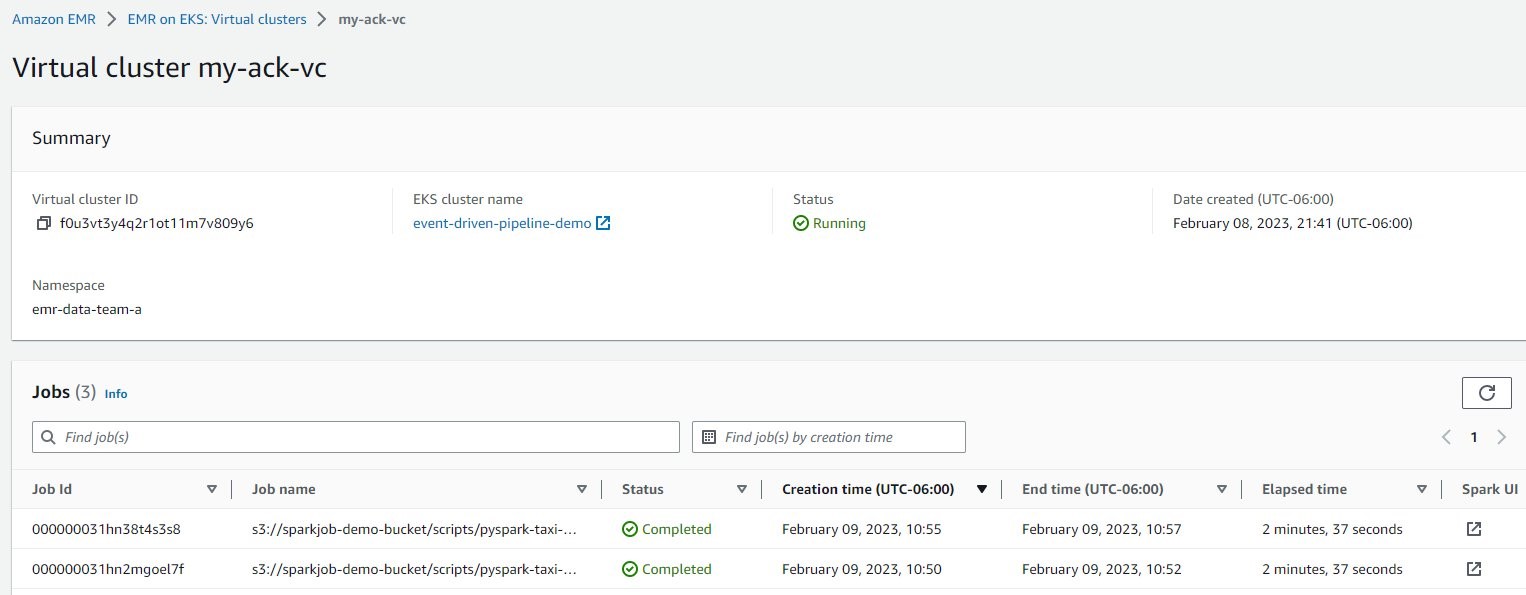
For the Spark job details, on the Amazon EMR console, choose Virtual clusters in the navigation pane, and then choose my-ack-vc. You can review all the job run history for this virtual cluster. If you choose Spark UI in any row, you’re redirected the Spark history server for more Spark driver and executor logs.
Clean up
To clean up the resources created in the post, use the following code:
Conclusion
This post showed how to build an event-driven data pipeline purely with native Kubernetes API and tooling. The pipeline uses EMR on EKS as compute and uses serverless AWS resources Amazon S3, EventBridge, and Step Functions as storage and orchestration in an event-driven architecture. With EventBridge, AWS and custom events can be ingested, filtered, transformed, and reliably delivered (routed) to more than 20 AWS services and public APIs (webhooks), using human-readable configuration instead of writing undifferentiated code. EventBridge helps you decouple applications and achieve more efficient organizations using event-driven architectures, and has quickly become the event bus of choice for AWS customers for many use cases, such as auditing and monitoring, application integration, and IT automation.
By using ACK controllers to create and configure different AWS services, developers can perform all data plane operations without leaving the Kubernetes platform. Also, developers only need to maintain the EKS cluster because all the other components are serverless.
As a next step, clone the GitHub repository to your local machine and test the data pipeline in your own AWS account. You can modify the code in this post and customize it for your own needs by using different EventBridge rules or adding more steps in Step Functions.
About the authors
 Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS customers to design microservices and cloud native solutions using Amazon EKS/ECS and AWS serverless services. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps.
Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS customers to design microservices and cloud native solutions using Amazon EKS/ECS and AWS serverless services. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps.
 Michael Gasch is a Senior Product Manager for AWS EventBridge, driving innovations in event-driven architectures. Prior to AWS, Michael was a Staff Engineer at the VMware Office of the CTO, working on open-source projects, such as Kubernetes and Knative, and related distributed systems research.
Michael Gasch is a Senior Product Manager for AWS EventBridge, driving innovations in event-driven architectures. Prior to AWS, Michael was a Staff Engineer at the VMware Office of the CTO, working on open-source projects, such as Kubernetes and Knative, and related distributed systems research.
 Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter has a keen interest in evangelizing AWS solutions and has written multiple blog posts that focus on simplifying complex use cases. At AWS, Peter helps with designing and architecting variety of customer workloads.
Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter has a keen interest in evangelizing AWS solutions and has written multiple blog posts that focus on simplifying complex use cases. At AWS, Peter helps with designing and architecting variety of customer workloads.