AWS Big Data Blog
Category: Analytics

Migrate External Table Definitions from a Hive Metastore to Amazon Athena
For customers who use Hive external tables on Amazon EMR, or any flavor of Hadoop, a key challenge is how to effectively migrate an existing Hive metastore to Amazon Athena, an interactive query service that directly analyzes data stored in Amazon S3. With Athena, there are no clusters to manage and tune, and no infrastructure to […]

Implement Serverless Log Analytics Using Amazon Kinesis Analytics
Applications log a large amount of data that—when analyzed in real time—provides significant insight into your applications. Real-time log analysis can be used to ensure security compliance, troubleshoot operation events, identify application usage patterns, and much more. Ingesting and analyzing this data in real time can be accomplished by using a variety of open source […]

Secure Amazon EMR with Encryption
In the last few years, there has been a rapid rise in enterprises adopting the Apache Hadoop ecosystem for critical workloads that process sensitive or highly confidential data. Due to the highly critical nature of the workloads, the enterprises implement certain organization/industry wide policies and certain regulatory or compliance policies. Such policy requirements are designed […]
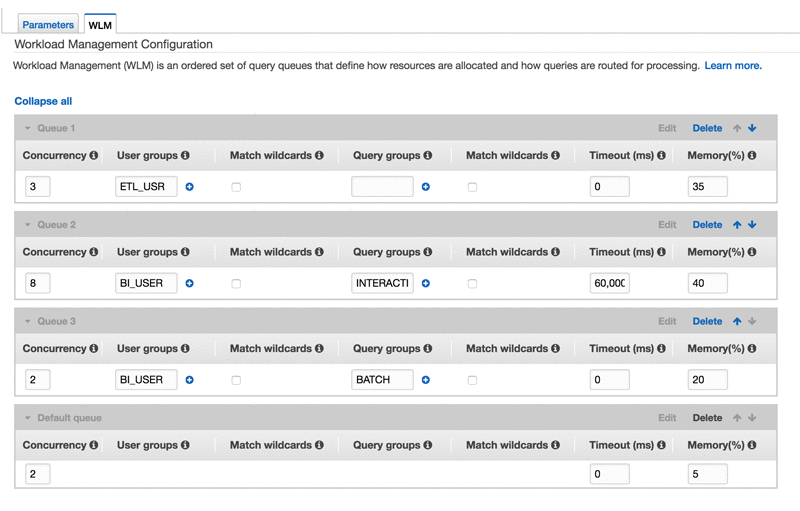
Run Mixed Workloads with Amazon Redshift Workload Management
This blog post has been translated into Japanese. Mixed workloads run batch and interactive workloads (short-running and long-running queries or reports) concurrently to support business needs or demand. Typically, managing and configuring mixed workloads requires a thorough understanding of access patterns, how the system resources are being used and performance requirements. It’s common for mixed […]
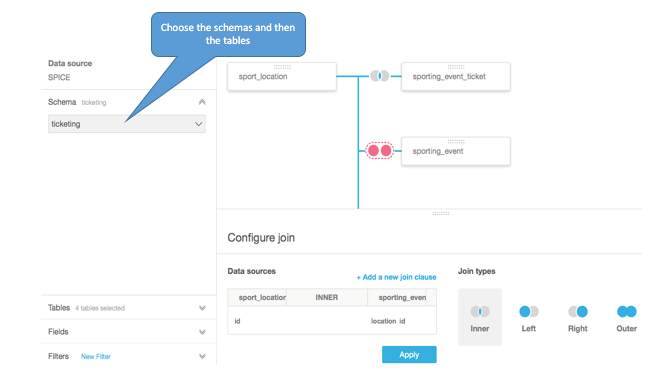
Converging Data Silos to Amazon Redshift Using AWS DMS
Organizations often grow organically—and so does their data in individual silos. Such systems are often powered by traditional RDBMS systems and they grow orthogonally in size and features. To gain intelligence across heterogeneous data sources, you have to join the data sets. However, this imposes new challenges, as joining data over dblinks or into a […]

Create a Healthcare Data Hub with AWS and Mirth Connect
As anyone visiting their doctor may have noticed, gone are the days of physicians recording their notes on paper. Physicians are more likely to enter the exam room with a laptop than with paper and pen. This change is the byproduct of efforts to improve patient outcomes, increase efficiency, and drive population health. Pushing for […]

Decreasing Game Churn: How Upopa used ironSource Atom and Amazon ML to Engage Users
This is a guest post by Tom Talpir, Software Developer at ironSource. ironSource is as an Advanced AWS Partner Network (APN) Technology Partner and an AWS Big Data Competency Partner. Ever wondered what it takes to keep a user from leaving your game or application after all the hard work you put in? Wouldn’t it be great […]
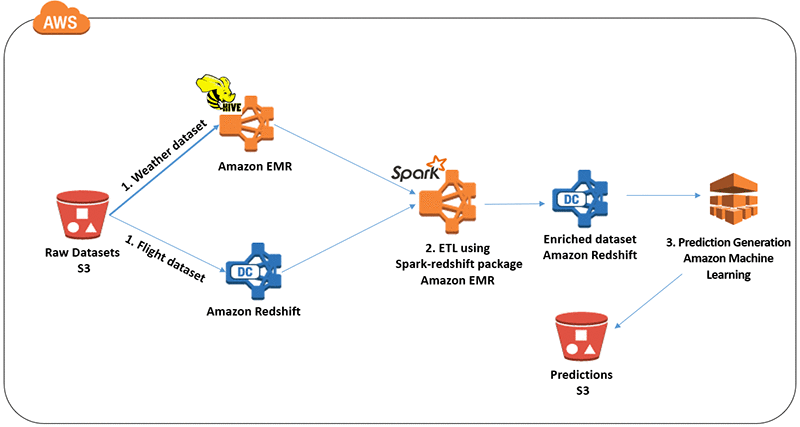
Powering Amazon Redshift Analytics with Apache Spark and Amazon Machine Learning
Air travel can be stressful due to the many factors that are simply out of airline passengers’ control. As passengers, we want to minimize this stress as much as we can. We can do this by using past data to make predictions about how likely a flight will be delayed based on the time of […]

Serving Real-Time Machine Learning Predictions on Amazon EMR
The typical progression for creating and using a trained model for recommendations falls into two general areas: training the model and hosting the model. Model training has become a well-known standard practice. We want to highlight one of many ways to host those recommendations (for example, see the Analyzing Genomics Data at Scale using R, […]

Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Ben Snively is a Solutions Architect with AWS Speed and agility are essential with today’s analytics tools. The quicker you can get from idea to first results, the more you can experiment […]