AWS Big Data Blog
Processing Amazon Kinesis Stream Data Using Amazon KCL for Node.js
Manan Gosalia is an SDE for Amazon Kinesis
This blog post shows you how to get started with the Amazon Kinesis Client Library (KCL) for Node.js. The Node.js framework uses an event-driven, non-blocking I/O model that makes it lightweight, efficient, and perfect for data-intensive, real-time applications that run across distributed devices. JavaScript is also simple to learn and use. With the increasing popularity of full-stack JavaScript application development, Amazon KCL for Node.js allows JavaScript developers to write end-to-end Amazon Kinesis applications in Node.js easily.
Amazon Kinesis is a fully managed, cloud-based service for real-time data processing over large, distributed data streams. With Amazon Kinesis, data can be collected from many sources such as website clickstreams, IT logs, social media feeds, billing related transactions, and sensor readings from IoT devices.
After data has been stored in Amazon Kinesis, you can consume and process data with the KCL for data analysis, archival, real-time dashboards, and much more. While you can use Amazon Kinesis API functions to process stream data directly, the KCL takes care of many complex tasks associated with distributed processing and allows you to focus on the record processing logic. For example, the KCL can automatically load balance record processing across many instances, allow the user to checkpoint records that are already processed, and handle instance failures.
Node.js support for the KCL is implemented using the MultiLangDaemon. The core of the KCL logic (communicating with Amazon Kinesis, load balancing, handling instance failure, etc.) resides in Java, and Amazon KCL for Node.js uses the multi-language daemon protocol to communicate with the Java daemon.
You can view a detailed tutorial for getting started with Amazon KCL for Node.js on GitHub. The KCL is also available for other languages, such as Java, Python, and Ruby.
Amazon Kinesis and KCL Overview
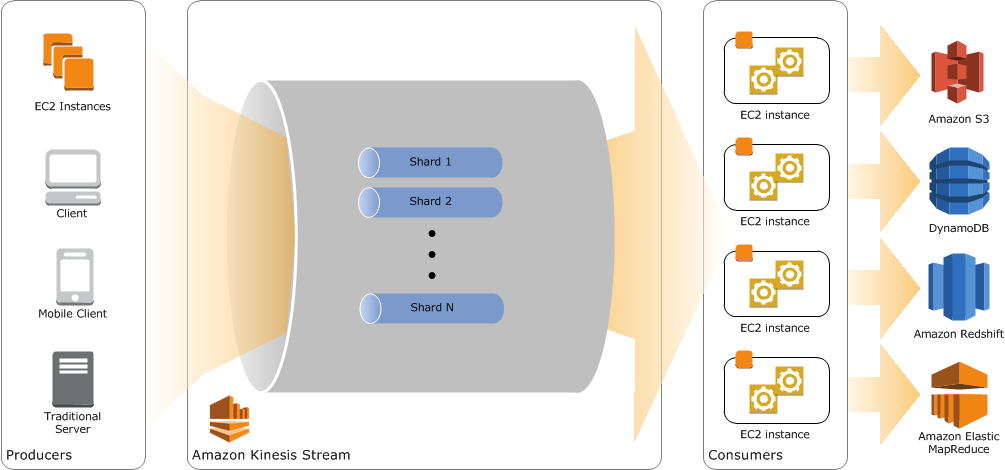
The image below shows the key components of a typical Amazon Kinesis application:

Producers, which can be EC2 instances, traditional servers, or even end-user devices, generate and put data into an Amazon Kinesis stream. The stream consists of one or more shards, each of which supports a fixed number of put transactions and throughput. Consumers retrieve data from the stream in real-time using the Amazon Kinesis API or KCL for processing. Processed data can be sent to a number of other services for archival, querying, or batch processing depending on the specific use case.
Put Data into an Amazon Kinesis Stream using Node.js
Before writing a consumer application, you’ll need to develop an Amazon Kinesis producer to put data into your stream. The AWS SDK for Node.js provides easy-to-use API for Amazon Kinesis. To get started, run the following command to install the AWS SDK module with the Node.js package manager, npm:
npm install aws-sdk
There are several ways to pass credential information to the AWS SDK library. This is discussed in detail in the Getting Started guide for the AWS SDK in Node.js.
After the setup is complete, you can start writing an Amazon Kinesis producer application that creates a stream and adds records to it. The example below demonstrates how to create a new stream:
var AWS = require('aws-sdk');
var kinesis = new AWS.Kinesis({region : 'us-west-2'});
function createStream(streamName, numberOfShards, callback) {
var params = {
ShardCount: numberOfShards,
StreamName: streamName
};
// Create the new stream if it does not already exist.
kinesis.createStream(params, function(err, data) {
if (err && err.code !== 'ResourceInUseException') {
callback(err);
return;
}
// Make sure the stream is in the ACTIVE state before
// you start pushing data.
waitForStreamToBecomeActive(streamName, callback);
});
}
function waitForStreamToBecomeActive(streamName, callback) {
kinesis.describeStream({StreamName : streamName},
function(err, data) {
if (err) {
callback(err);
return;
}
if (data.StreamDescription.StreamStatus === 'ACTIVE') {
callback();
}
// The stream is not ACTIVE yet. Wait for another 5 seconds before
// checking the state again.
else {
setTimeout(function() {
waitForStreamToBecomeActive(streamName, callback);
}, 5000);
}
}
);
}
After the stream is created, you can start putting data into the stream. In the example below, we put random data in the stream.
function writeToKinesis(streamName) {
var randomNumber = Math.floor(Math.random() * 100000);
var data = 'data-' + randomNumber;
var partitionKey = 'pk-' + randomNumber;
var recordParams = {
Data: data,
PartitionKey: partitionKey,
StreamName: streamName
};
kinesis.putRecord(recordParams, function(err, data) {
if (err) {
console.error(err);
}
});
}
And now, to tie everything together, the following example invokes functions to create a new stream with two shards and put data into the stream after the stream becomes active.
createStream('TestStream', 2, function(err) {
if (err) {
console.error('Error starting Kinesis producer: ' + err);
return;
}
for (var i = 0 ; i < 10 ; ++i) {
writeToKinesis('TestStream');
}
});
Process Data from Amazon Kinesis using the Amazon KCL for Node.js
Assuming that you have at least one producer that has sent or is actively sending data to the stream, the example below shows how to use the Amazon KCL for Node.js to consume data from the stream.
Run the following command to install the KCL module in Node.js with npm:
npm install aws-kcl
After the module is installed, you can create your KCL application by providing a record processor implementation. Each shard is processed by exactly one record processor instance, and vice versa. The KCL takes care of instantiating one record processor instance for each shard in the stream. A record processor needs to implement three API functions that the KCL will invoke:
- initialize – invoked one time at the beginning of the record processing for the specific shard. Your application’s initialization logic can be implemented in this function. For example, if you are saving processed data in Amazon S3, then you may create an S3 client here.
- processRecords – invoked zero or more times with new records retrieved from the stream. The KCL supports checkpoint functionality, also. With periodic checkpoints, your record processor stores the state to mark how far it has successfully progressed in processing the records in the shard. This way, if the record processor instance for a shard fails, the new record processor continues processing records after the latest checkpoint for that shard.
- shutdown – called one time at the end when there are no more records to process or when the record processor is no longer processing records for the shard. Your application-specific clean up logic can be put in this function. For example, you can close or clean up resources that you may have created in the initialize function. If the shard has no more records (shutdown reason is TERMINATE), then you should also checkpoint the final state to notify the KCL that all records for the shard have been processed successfully.
Below is an example implementation of a record processor:
var recordProcessor = {
initialize: function(initializeInput, completeCallback) {
// Your application specific initialization logic.
// After initialization is done, call completeCallback,
// to let the KCL know that the initialize operation is
// complete.
completeCallback();
},
processRecords: function(processRecordsInput, completeCallback) {
// Sample code for record processing.
if (!processRecordsInput || !processRecordsInput.records) {
// Invoke callback to tell the KCL to process next batch
// of records.
completeCallback();
return;
}
var records = processRecordsInput.records;
var record, sequenceNumber, partitionKey, data;
for (var i = 0 ; i < records.length ; ++i) {
record = records[i];
sequenceNumber = record.sequenceNumber;
partitionKey = record.partitionKey;
// Data is in base64 format.
data = new Buffer(record.data, 'base64').toString();
// Record processing logic here.
}
// Checkpoint last sequence number.
processRecordsInput.checkpointer.checkpoint(
sequenceNumber, function(err, sn) {
// Error handling logic. In this case, we call
// completeCallback to process more data.
completeCallback();
}
);
},
shutdown: function(shutdownInput, completeCallback) {
// Your shutdown logic.
if (shutdownInput.reason !== 'TERMINATE') {
completeCallback();
return;
}
shutdownInput.checkpointer.checkpoint(function(err) {
// Error handling logic.
// Invoke the callback at the end to mark the shutdown
// operation complete.
completeCallback();
});
}
};
Now the only remaining task is to write the code that invokes the KCL with your record processor implementation.
var kcl = require('aws-kcl');
kcl(recordProcessor).run();
As previously mentioned, the Amazon KCL for Node.js uses the multi-language protocol (MultiLangDaemon) for the core KCL functionality. To run the Amazon KCL for Node.js application, you need to invoke the MultiLangDaemon with a properties file. The MultiLangDaemon is implemented in Java and requires the Java Runtime Environment (JRE) 1.7 or higher. The properties file passed to the MultiLangDaemon specifies different KCL configuration options such as region, the stream name to be processed by your KCL application, AWS credential provider, etc. To view the sample properties file, see the “samples” directory in the GitHub repository.
A bootstrap script is provided in the KCL module’s /bin folder and will run the Amazon KCL for Node.js application for you. After you have your Amazon KCL for Node.js application and properties file, you can invoke the following command to start the consumer application (this command assumes that you have the /node_modules/.bin folder in your path).
kcl-bootstrap --properties <path_to_properties_file> -e
Another Amazon KCL for Node.js consumer application with sample properties file can be viewed at the GitHub repository. If you would like to explore a more complex application, the repository also contains a sample click-stream producer and consumer.
Conclusion
In summary, Amazon KCL for Node.js allows developers with JavaScript knowledge to write Amazon Kinesis consumer applications and process stream data easily. For more information, see the Developer Resources page.
If you have questions or suggestions, please leave a comment below.
————————————
Related:
Hosting Amazon Kinesis Applications on AWS Elastic Beanstalk

Snakes in the Stream! Feeding and Eating Amazon Kinesis Streams with Python