AWS Big Data Blog
Category: Uncategorized
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]
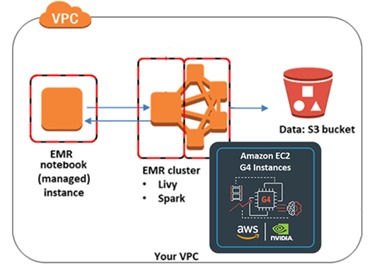
Improving RAPIDS XGBoost performance and reducing costs with Amazon EMR running Amazon EC2 G4 instances
This is a guest post by Kong Zhao, Solution Architect at NVIDIA Corporation This post shares how NVIDIA sped up RAPIDS XGBoost performance up to 4.5 times faster and reduced costs up to 5.4 times less by using Amazon EMR running Amazon Elastic Compute Cloud (Amazon EC2) G4 instances. Gradient boosting is a powerful machine […]

Best practices from Delhivery on migrating from Apache Kafka to Amazon MSK
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This is a guest post by Delhivery. In this post, we describe the steps Delhivery took to migrate from self-managed Apache Kafka running on Amazon Elastic Compute […]

Streaming web content with a log-based architecture with Amazon MSK
Content, such as breaking news or sports scores, requires updates in near-real-time. To stay up to date, you may be constantly refreshing your browser or mobile app. Building APIs to deliver this content at speed and scale can be challenging. In this post, I present an alternative to an API-based approach. I outline the concept […]

Federate Amazon Redshift access with Microsoft Azure AD single sign-on
April 2024: This post was reviewed for accuracy. December 2022: This post was reviewed and updated for accuracy. February 2nd, 2022: This blog was updated by Kay Lerch. Recently, we helped a large enterprise customer who was building their data warehouse on Amazon Redshift, using Microsoft Azure Active Directory (Azure AD) as a corporate directory. […]

Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 2
In Part 1 of this post series, you learned how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. This post guides you through deploying the AWS CloudFormation templates, configuring Genie, and running an example workflow authored in Apache Airflow.

Create advanced insights using Level Aware Aggregations in Amazon QuickSight
Amazon QuickSight recently launched Level Aware Aggregations (LAA), which enables you to perform calculations on your data to derive advanced and meaningful insights. In this blog post, we go through examples of applying these calculations to a sample sales dataset so that you can start using these for your own needs.
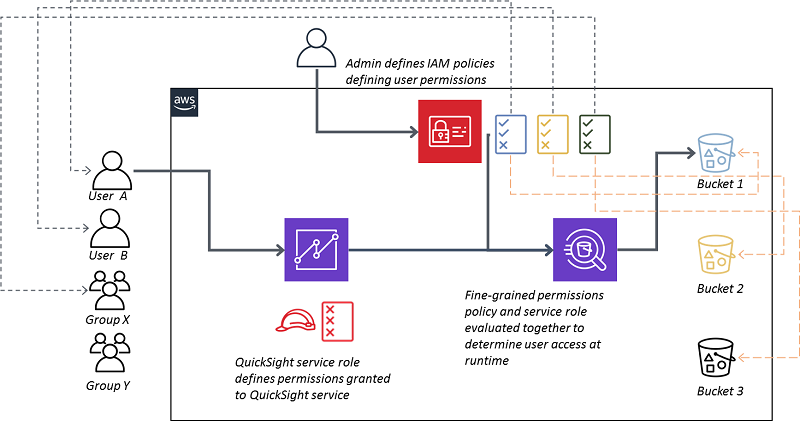
Introducing Amazon QuickSight fine-grained access control over Amazon S3 and Amazon Athena
Today, AWS is excited to announce the availability of fine-grained access control for AWS Identity and Access Management (IAM)-permissioned resources in Amazon QuickSight. Fine-grained access control allows Amazon QuickSight account administrators to control authors’ default access to connected AWS resources. Fine-grained access control enables administrators to use IAM policies to scope down access permissions, limiting specific authors’ access to specific items within the AWS resources. Administrators can now apply this new level of access control to Amazon S3, Amazon Athena, and Amazon RDS/Redshift database discovery.
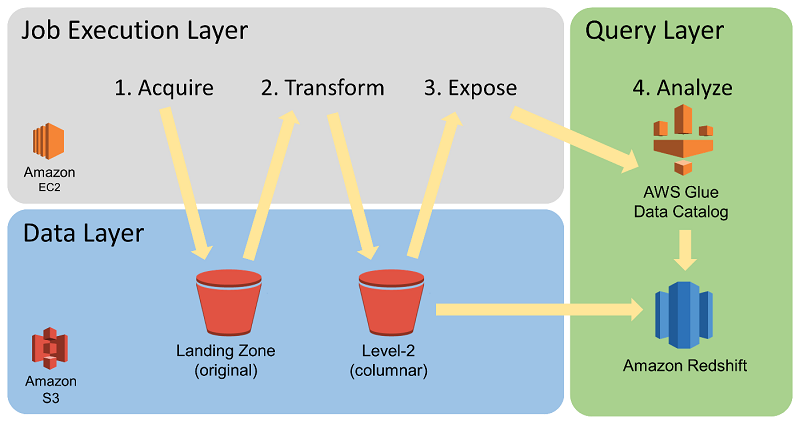
How Annalect built an event log data analytics solution using Amazon Redshift
By establishing a data warehouse strategy using Amazon S3 for storage and Redshift Spectrum for analytics, we increased the size of the datasets we support by over an order of magnitude. In addition, we improved our ability to ingest large volumes of data quickly, and maintained fast performance without increasing our costs. Our analysts and modelers can now perform deeper analytics to improve ad buying strategies and results.
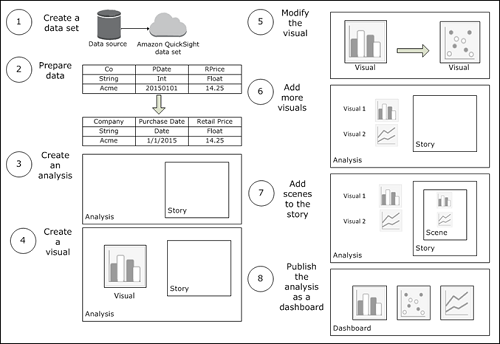
10 visualizations to try in Amazon QuickSight with sample data
Using Amazon QuickSight, you can see patterns across a time-series data by building visualizations, performing ad hoc analysis, and quickly generating insights.