AWS Big Data Blog
Improving RAPIDS XGBoost performance and reducing costs with Amazon EMR running Amazon EC2 G4 instances
This is a guest post by Kong Zhao, Solution Architect at NVIDIA Corporation
This post shares how NVIDIA sped up RAPIDS XGBoost performance up to 4.5 times faster and reduced costs up to 5.4 times less by using Amazon EMR running Amazon Elastic Compute Cloud (Amazon EC2) G4 instances.
Gradient boosting is a powerful machine learning (ML) algorithm used to achieve state-of-the-art accuracy on tasks such as regression, classification, and ranking. If you’re not using deep neural networks, there’s a good chance you use gradient boosting.
Data scientists use open-source XGBoost libraries in industries such as:
- Financial services – Predicting loan performance and other financial risks
- Retail – Predicting customer churn
- Advertising – Predicting click rate
Amazon EMR and NVIDIA GPU instances
Amazon EMR is the industry-leading cloud big data platform for processing vast amounts of data using open-source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. With Amazon EMR, you can run petabyte-scale analysis at less than half the cost of traditional on-premises solutions and over three times faster than standard Apache Spark. Data scientists use Amazon EMR to run open-source deep learning and ML tools such as TensorFlow and Apache MXNet, and use case-specific tools and libraries. You can quickly and easily create scalable and secure clusters with the latest GPU instances for distributed ML training with a few clicks on the Amazon EMR console.
For more information about getting started with Amazon EMR, see What Is Amazon EMR?
G4 instance on Amazon EMR
Amazon EMR continually evolves GPU offerings and collaborates with partners like NVIDIA to improve the platform’s performance. Our latest development is the support for the EC2 G4 instance type featuring an NVIDIA T4 Tensor Core GPU with 16 GB of GPU memory, offered under the Nitro hypervisor with 1–4 GPUs per node. It also includes up to 1.8 TB of local non-volatile memory express (NVMe) storage and up to 100 Gbps of network bandwidth.
The T4 Tensor Core GPU offering from NVIDIA is a cost-effective and versatile GPU instance for accelerating ML models training and inferencing, video transcoding, and other compute-intensive workloads. G4 instances are offered in different instance sizes with access to one GPU or multiple GPUs with different amounts of vCPU and memory—giving you the flexibility to pick the right instance size for your applications.
Accelerated XGBoost open-source library integrated into Apache Spark by NVIDIA
While ML at scale can deliver powerful, predictive capabilities to millions of users, it hinges on overcoming two key challenges across infrastructure to save costs and deliver results faster: speeding up preprocessing massive volumes of data and accelerating compute-intensive model training.
To tackle these challenges, NVIDIA is incubating RAPIDS, a set of open-source software libraries, and the RAPIDS team works closely with the Distributed Machine Learning Common (DMLC) XGBoost organization to upstream code and make sure that all components of the GPU-accelerated analytics ecosystem work together smoothly. We used the XGBoost4J-Spark open-source library, which enables training and inferencing of XGBoost models across Apache Spark nodes. With GPUs, you can exploit data parallelism through columnar processing instead of traditional row-based reading designed initially for CPUs. This allows for cost savings and higher performance.
Higher performance at lower cost with Amazon EMR on GPU instances
We benchmarked the latest RAPIDS-Spark XGBoost4j open-source library on an EMR cluster with EC2 G4 instances running Apache Spark. We ran the benchmark using a 1 TB open-source dataset called Criteo on Amazon Simple Storage Service (Amazon S3) directly. Criteo is commonly used for predicting click-through rates on display ads. We used Amazon S3 as a data store.
The following graphs show our improvements in training time and costs.
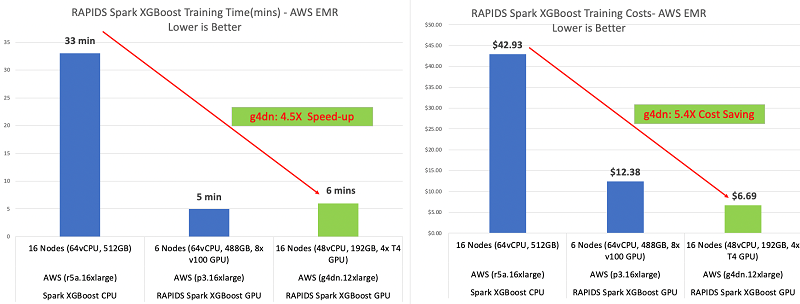
An EMR cluster running G4dn instances is 5.4 times cheaper and 4.5 times faster than an EMR cluster running EC2 R5 memory-optimized instances. The EMR cluster with g4dn GPU instances gave us almost the same training time but at half the cost of running the training on an EMR cluster running EC2 P3 instances. The following table summarizes our findings.
| Type | Number of Instances | Hardware per Instance | Instance Type | Amazon EC2 Cost per Hour | Amazon EMR Cost per Hour | Training (Minutes) | Training Costs |
| GPU | 16 | 4x T4 | g4dn.12xlarge | $3.912 | $0.27 | 6 | $6.69 |
| GPU | 6 | 8 x V100 | p3.16xlarge | $24.48 | $0.27 | 5 | $12.38 |
| CPU | 16 | 64 vCPU | r5a.16xlarge | $4.608 | $0.27 | 33 | $42.93 |
Solution overview
You can use the following step-by-step walkthrough to run the example mortgage dataset using the open-source XGBoost library on EMR GPU clusters. For more examples, see the GitHub repo.
Implementing this solution includes the following steps:
- Create an EMR notebook and launch Amazon EMR with NVIDIA GPU nodes.
- Run the open-source XGBoost library and Apache Spark examples on the notebook.
- View the training and transform results and benchmark.
- Launch example applications with the Apache Spark
spark-submit
Creating an EMR notebook and launching Amazon EMR with NVIDIA GPU nodes
An EMR notebook is a serverless Jupyter notebook. Unlike a traditional notebook, the contents of an EMR notebook—the equations, visualizations, queries, models, code, and narrative text—are saved in Amazon S3 separately from the cluster that runs the code. This provides an EMR notebook with durable storage, efficient access, and flexibility.
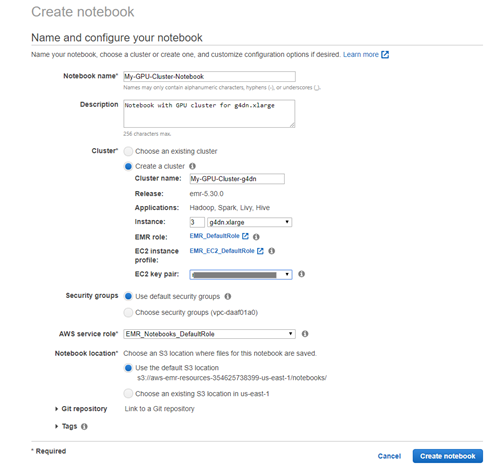
To create your notebook and launch Amazon EMR, complete the following steps.
- On the Amazon EMR console, choose the Region you want to launch your cluster in (typically the same Region as your S3 bucket where you store large training datasets).
- Choose Notebooks.
- Choose Create notebook.
- Create a new cluster with notebook instances by setting the GPU node.
For this use case, we add three EC2 g4dn.xlarge GPU nodes to the new cluster.
If you want to customize your cluster with advanced configuration, you can create a GPU cluster separately, then create an EMR notebook and connect to the existing GPU cluster. You can enter the following code in the AWS Command Line Interface (AWS CLI) to launch a GPU cluster with two EC2 G4dn instances as core nodes in one command line:
Replace the values for KeyName, SubnetId, EmrManagedSlaveSecurityGroup, EmrManagedMasterSecurityGroup, and S3 bucket with your logs, name, and Region.
You can also use the AWS Management Console to configure the EMR cluster. For instructions, see Get Started with XGBoost4J-Spark on AWS EMR on GitHub.
Running the XGBoost library and Apache Spark examples on your EMR notebook
When the cluster is ready, go to the Amazon EMR notebooks, choose the notebook instance, and choose Open in Jupyter. Start the notebook instance if it’s not running.
Download the example notebook EMR_Mortgage_Example_G4dn.ipynb from Rapids/spark-examples on GitHub and upload it to the EMR notebook instance. For more Scala example code, see the GitHub repo.
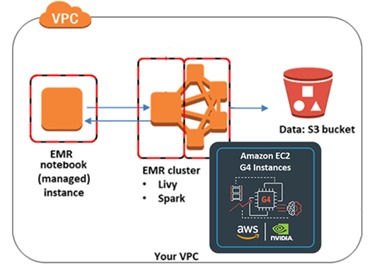
Enter the mortgage example notebook to run the GPU-accelerated Apache Spark code on the open-source XGBoost library towards a small mortgage dataset on Amazon S3. If the notebook kernel isn’t set to Apache Spark, choose Kernel, Change Kernel to set Apache Spark as the kernel. The EMR notebook is now talking to the EMR cluster running Apache Spark using Apache Livy. The following diagram illustrates this architecture.
You can customize your Apache Spark job configurations, such as number of executors, number of cores, and executor memory base on your GPU cluster. Each GPU maps to one executor.
Viewing the training and transform results and benchmark
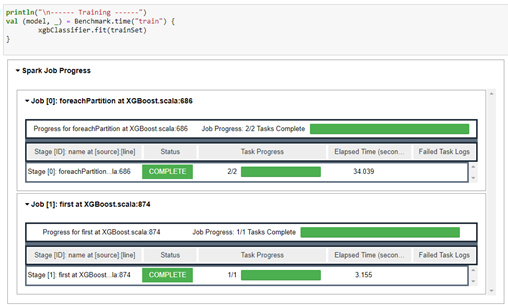
In the EMR notebook, you can view the Apache Spark job progress and the benchmark results. You can save the trained model to a local folder or S3 bucket. The following screenshot shows our job progress.
The following code shows the benchmark results:
Launching example applications with the spark-submit script
Alternatively, you can SSH into the EMR primary node and use the Apache Spark spark-submit script to launch the application directly on a cluster. Follow the walkthrough on the GitHub repo to use Apache Maven to create a jar containing the example code for the mortgage dataset and its dependencies, and launch the application using the Apache Spark spark-submit script CLI.
Cleaning up
To avoid ongoing charges for resources you created for this benchmarking, delete all the resources you created. This includes the data on the S3 bucket, EMR cluster, and EMR notebook.
Conclusion
Get started on Amazon EMR today, or reach out to AWS for help if you want to migrate your big data and applications to AWS. You can also learn more about Nvidia’s contribution to RAPIDS.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the author
 Kong Zhao is a Solution Architect at Nvidia. He provides technical thought leadership, architecture guidance, and conducts PoC for both Nvidia and AWS customers to meet their AI and HPC requirement by developing, optimizing, and deploying GPU-accelerated solutions in the cloud. His core areas of focus are GPU-related cloud architecture, HPC, machine learning, and analytics. Previously, Kong worked as a Senior Solution Architect in AWS, an Architect in Equinix for Cloud Exchange, and a Product Manager in Cisco.
Kong Zhao is a Solution Architect at Nvidia. He provides technical thought leadership, architecture guidance, and conducts PoC for both Nvidia and AWS customers to meet their AI and HPC requirement by developing, optimizing, and deploying GPU-accelerated solutions in the cloud. His core areas of focus are GPU-related cloud architecture, HPC, machine learning, and analytics. Previously, Kong worked as a Senior Solution Architect in AWS, an Architect in Equinix for Cloud Exchange, and a Product Manager in Cisco.