AWS Big Data Blog
Get started faster with one-click onboarding, serverless notebooks, and AI agents in Amazon SageMaker Unified Studio
Data teams today struggle with fragmented tools, complex infrastructure provisioning, and hours spent writing boilerplate code to connect to data sources. This forces analysts, data scientists, and engineers to work in separate environments, which slows collaboration and time to insight. Since our launch of Amazon SageMaker Unified Studio in March 2025, leading companies such as Bayer, NatWest, and Carrier have adopted it to bring their data teams into one collaborative workspace with unified tools, straightforward infrastructure provisioning, and fast connections to data sources.
Continuing our mission to provide faster time-to-value for customers, in November 2025, we announced Amazon SageMaker notebooks, a serverless workspace with a built-in AI agent in Amazon SageMaker Unified Studio. You can now launch a notebook in seconds, generate code from natural language prompts, and connect automatically to data across Amazon Simple Storage Service (Amazon S3), Amazon Redshift, third-party databases, and more from a single environment without needing to pre-provision or tune data processing infrastructure. Inside these serverless notebooks, analysts can perform SQL queries, data scientists can execute Python code, and data engineers can process large-scale data jobs in Spark within a single workspace. Together with the new one-click onboarding available for SageMaker Unified Studio, customers can go from their existing AWS data to running analytics and machine learning workloads much faster, spending their time on analysis rather than setup and configuration.
In this post, we walk you through how these new capabilities in SageMaker Unified Studio can help you consolidate your fragmented data tools, reduce time to insight, and collaborate across your data teams. Here’s a short demo of the new capabilities:
One-click onboarding of existing AWS datasets
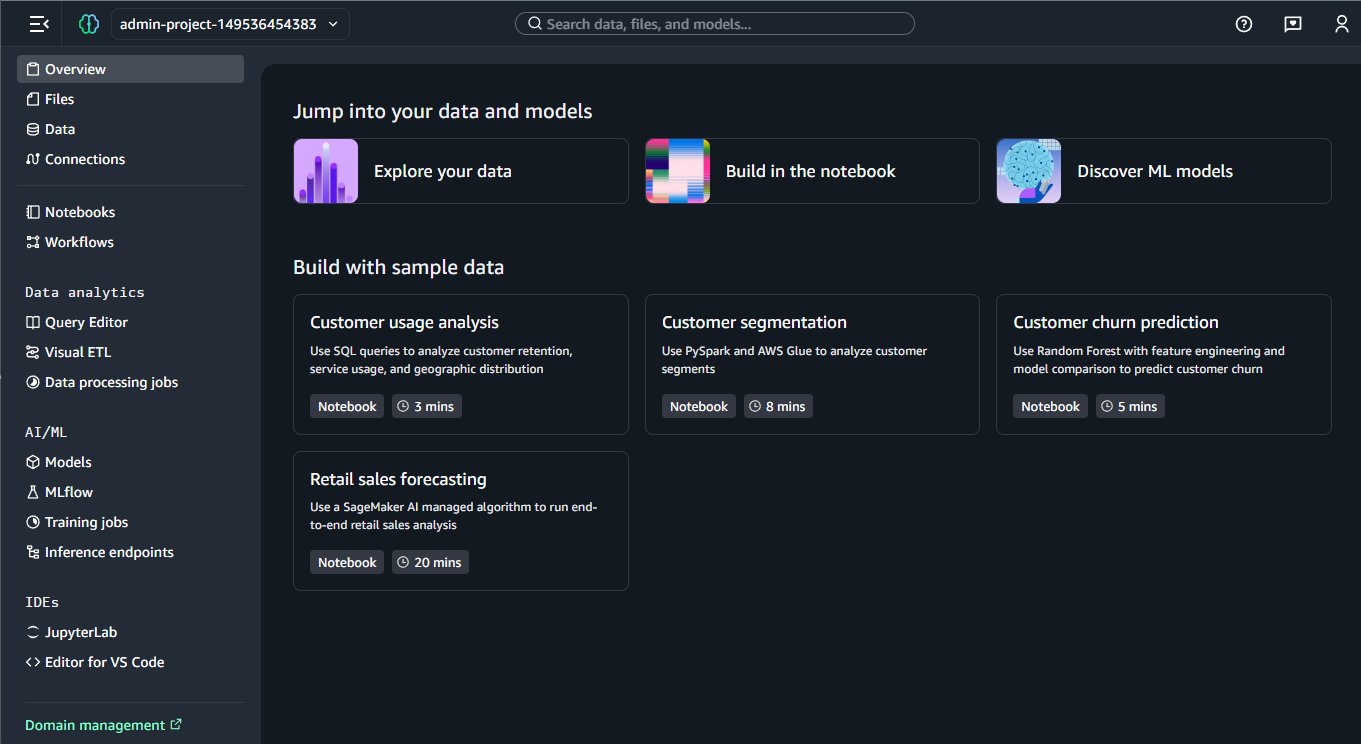
Get started exploring your data with one-click onboarding that provisions and configures environments in minutes instead of weeks. The new onboarding experience can reuse existing AWS Identity and Access Management (IAM) roles to provide access to SageMaker Unified Studio, automatically connecting to data sources across S3 buckets, S3 Tables, AWS Glue Data Catalog, and AWS Lake Formation policies, removing the need for additional data permission setup. Under the covers, a new IAM-based domain and project are created with default notebook and compute resources preconfigured. When complete, you enter SageMaker Unified Studio with all your tools available in the left-side navigation along with built-in samples to accelerate first use, as seen in the following screenshot.
“New features with Amazon Sagemaker will unlock a new paradigm of innovation, allowing Codex to significantly accelerate time-to-value for our customers, and transform them from aging to agentic in weeks, not months.“
– Abhinav Sharma, Chief Data Officer, Codex
You can start directly from Amazon SageMaker, Amazon Athena, Amazon Redshift, or Amazon S3 Tables, giving them a fast path from their existing tools and data to the unified experience in SageMaker Unified Studio. After you choose Get Started and specify an IAM role, SageMaker automatically creates a project with the existing data permissions intact from Data Catalog, Lake Formation, and Amazon S3. As a result, teams can immediately discover and act on their data using the existing data permissions and infrastructure.
For more information, see New one-click onboarding and notebooks with a built-in AI agent in Amazon SageMaker Unified Studio
Serverless SageMaker notebooks
The fully managed, web-based notebooks in SageMaker Unified Studio support multiple programming languages, letting you write Python, SQL, and Spark code in the same notebook. The infrastructure adjusts automatically based on your workload, while built-in libraries create charts and insights directly in your workflow. When your analysis scales beyond interactive queries to large-scale data processing, Amazon Athena for Apache Spark engine delivers optimized performance, integrating with the serverless notebook experience to execute analytical workloads efficiently. This serverless approach eliminates the need to provision clusters or maintain servers, reducing the time from question to insight.
“The new SageMaker interface brings clarity and speed to the entire ML lifecycle. Its developer-friendly design has made our experimentation and delivery significantly faster,“
– Sachin Mittal, Product Manager at Deloitte.
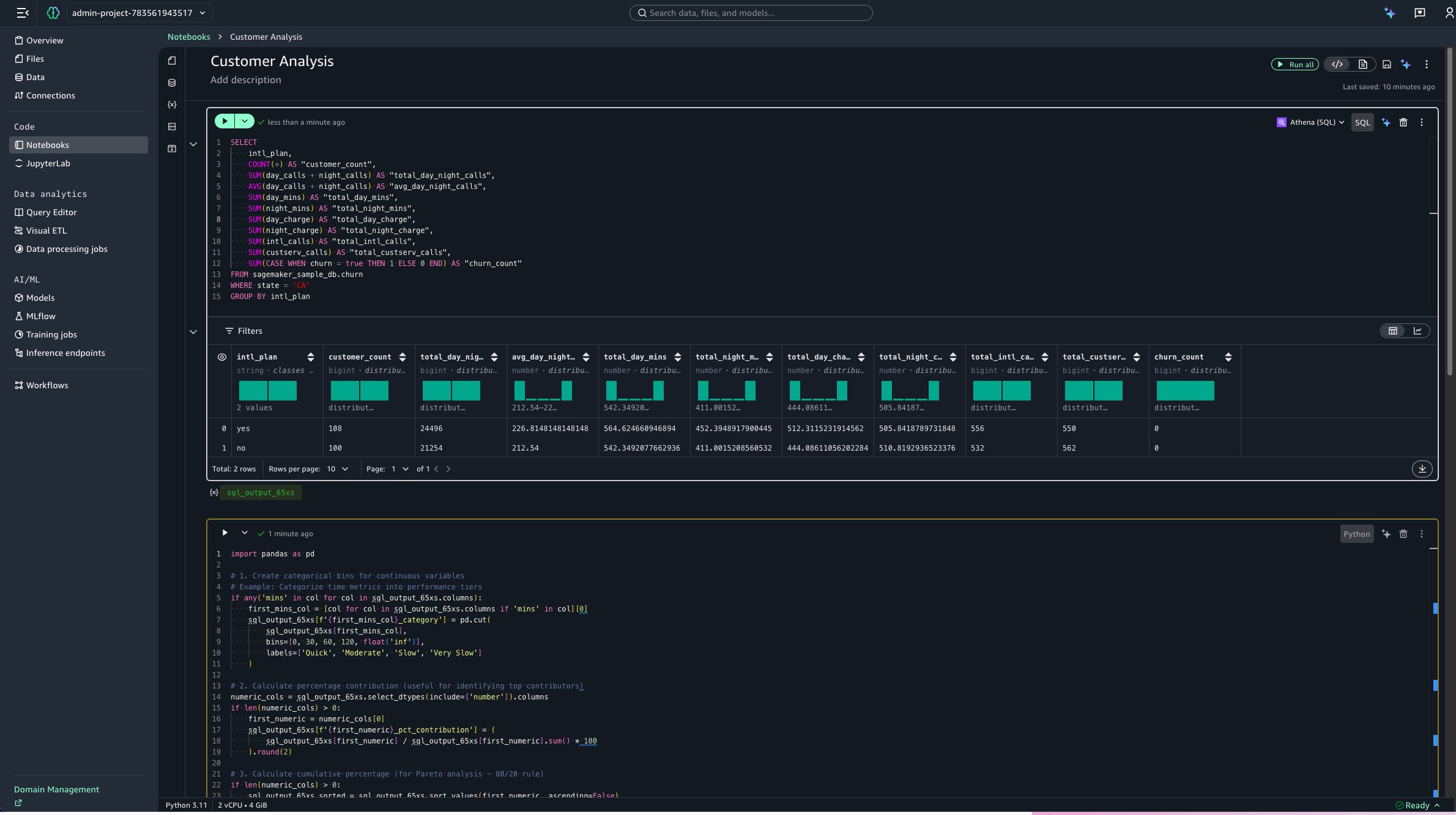
As shown in the preceding image, the notebook gives data engineers, analysts, and data scientists one place to perform SQL queries, execute Python code, process large-scale data jobs, run machine learning workloads, and create visualizations without having to switch between tools.
AI-assisted development with Data Agent
To accelerate development further, the new SageMaker Data Agent helps create SQL, Python, or Spark code using natural language prompts. Instead of spending hours writing boilerplate code to connect to your data sources and understand schemas, you can describe what you want to accomplish. The agent analyzes data catalog metadata about your available datasets, schemas, and relationships to provide context-aware assistance.
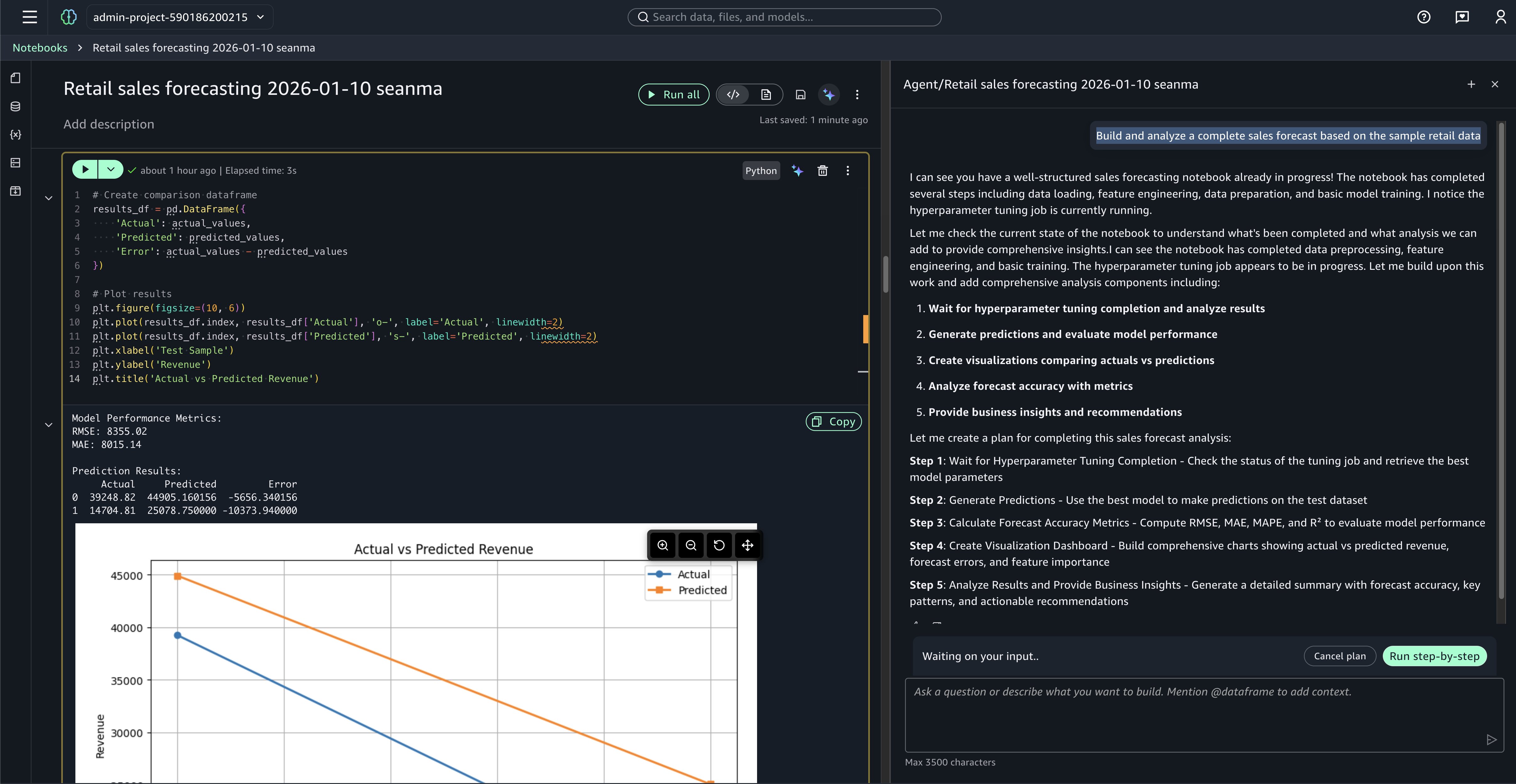
In the preceding example image, if you prompt Build and analyze a complete sales forecast based on the sample retail data, the agent helps identify the relevant tables and suggests the appropriate joins and analysis approach, transforming what might take hours into minutes. To try this yourself, navigate to the Overview tab in your SageMaker Studio environment and look for the Retail Sales Forecasting with SageMaker XGBoost notebook in the sample notebooks collection—these examples are automatically available when you first set up SageMaker Studio. The agent breaks down complex analytical workflows into manageable, executable steps, so you can move from question to insight faster.
Learn more about SageMaker
In this post, we focused on three new SageMaker Unified Studio capabilities recently made available, but they’re a fraction of the more than 40 launches last year. Here’s a list of videos of re:Invent sessions and the measurable results from leading organizations adopting SageMaker Unified Studio, including:
- Summary of 2025 launches: What’s new with Amazon SageMaker in the era of unified data and AI (ANT216)
- NatWest Group plans to scale to 72,000 employees having federated data access using SageMaker Unified Studio. Watch their presentation.
- Commonwealth Bank of Australia migrated 10 petabytes and 61,000 pipelines into AWS and has setup SageMaker Unified Studio to provide unified access to 40 different lines of business in their ongoing data transformation journey. Watch their presentation.
- Carrier Global Corporation improved natural language to SQL agent accuracy by 38% through the SageMaker Catalog’s governed metadata and business glossary. Watch their presentation.
- Bayer is now positioned to onboard over 300 TB of biomarker data and integrate siloed omics, clinical, and chemistry data repositories into a cohesive environment built on Amazon SageMaker. Read their story.
Conclusion
Using Amazon SageMaker Unified Studio serverless notebooks, AI-assisted development, and unified governance, you can speed up your data and AI workflows across data team functions while maintaining security and compliance. To learn more visit the SageMaker product page or get started in the SageMaker console.