AWS Big Data Blog
How GE Aviation automated engine wash analytics with AWS Glue using a serverless architecture
This post is authored by Giridhar G Jorapur, GE Aviation Digital Technology.
Maintenance and overhauling of aircraft engines are essential for GE Aviation to increase time on wing gains and reduce shop visit costs. Engine wash analytics provide visibility into the significant time on wing gains that can be achieved through effective water wash, foam wash, and other tools. This empowers GE Aviation with digital insights that help optimize water and foam wash procedures and maximize fuel savings.
This post demonstrates how we automated our engine wash analytics process to handle the complexity of ingesting data from multiple data sources and how we selected the right programming paradigm to reduce the overall time of the analytics job. Prior to automation, analytics jobs took approximately 2 days to complete and ran only on an as-needed basis. In this post, we learn how to process large-scale data using AWS Glue and by integrating with other AWS services such as AWS Lambda and Amazon EventBridge. We also discuss how to achieve optimal AWS Glue job performance by applying various techniques.
Challenges
When we considered automating and developing the engine wash analytics process, we observed the following challenges:
- Multiple data sources – The analytics process requires data from different sources such as foam wash events from IoT systems, flight parameters, and engine utilization data from a data lake hosted in an AWS account.
- Large dataset processing and complex calculations – We needed to run analytics for seven commercial product lines. One of the product lines has approximately 280 million records, which is growing at a rate of 30% year over year. We needed analytics to run against 1 million wash events and perform over 2,000 calculations, while processing approximately 430 million flight records.
- Scalable framework to accommodate new product lines and calculations – Due to the dynamics of the use case, we needed an extensible framework to add or remove new or existing product lines without affecting the existing process.
- High performance and availability – We needed to run analytics daily to reflect the latest updates in engine wash events and changes in flight parameter data.
- Security and compliance – Because the analytics processes involve flight and engine-related data, the data distribution and access need to adhere to the stringent security and compliance regulations of the aviation industry.
Solution overview
The following diagram illustrates the architecture of our wash analytics solution using AWS services.
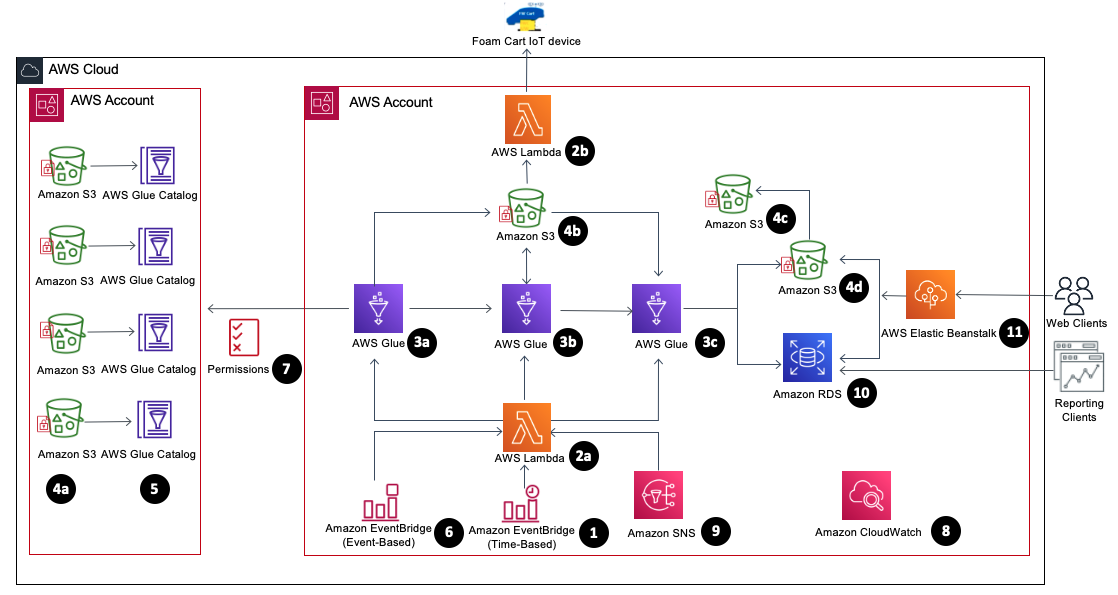
The solution includes the following components:
- EventBridge (1) – We use an EventBridge (time-based) to schedule the daily process to capture the delta changes between the runs.
- Lambda (2a) – Lambda orchestrates the AWS Glue jobs initiation, backup, and recovery on failure for each stage, utilizing EventBridge (event-based) for the alerting of these events.
- Lambda (2b) – Foam cart events from IoT devices are loaded into staging buckets in Amazon Simple Storage Service (Amazon S3) daily.
- AWS Glue (3) – The wash analytics need to handle a small subset of data daily, but the initial historical load and transformation is huge. Because AWS Glue is serverless, it’s easy to set up and run with no maintenance.
- Copy job (3a) – We use an AWS Glue copy job to copy only the required subset of data from across AWS accounts by connecting to AWS Glue Data Catalog tables using a cross-account AWS Identity and Access Management (IAM) role.
- Business transformation jobs (3b, 3c) – When the copy job is complete, Lambda triggers subsequent AWS Glue jobs. Because our jobs are both compute and memory intensive, we use G2.x worker nodes. We can use Amazon CloudWatch metrics to fine-tune our jobs to use the right worker nodes. To handle complex calculations, we split large jobs up into multiple jobs by pipelining the output of one job as input to another job.
- Source S3 buckets (4a) – Flights, wash events, and other engine parameter data is available in source buckets in a different AWS account exposed via Data Catalog tables.
- Stage S3 bucket (4b) – Data from another AWS account is required for calculations, and all the intermediate outputs from the AWS Glue jobs are written to the staging bucket.
- Backup S3 bucket (4c) – Every day before starting the AWS Glue job, the previous day’s output from the output bucket is backed up in the backup bucket. In case of any job failure, the data is recovered from this bucket.
- Output S3 bucket (4d) – The final output from the AWS Glue jobs is written to the output bucket.
Continuing our analysis of the architecture components, we also use the following:
- AWS Glue Data Catalog tables (5) – We catalog flights, wash events, and other engine parameter data using Data Catalog tables, which are accessed by AWS Glue copy jobs from another AWS account.
- EventBridge (6) – We use EventBridge (event-based) to monitor for AWS Glue job state changes (SUCEEDED, FAILED, TIMEOUT, and STOPPED) and orchestrate the workflow, including backup, recovery, and job status notifications.
- IAM role (7) – We set up cross-account IAM roles to copy the data from one account to another from the AWS Glue Data Catalog tables.
- CloudWatch metrics (8) – You can monitor many different CloudWatch metrics. The following metrics can help you decide on horizontal or vertical scaling when fine-tuning the AWS Glue jobs:
- CPU load of the driver and executors
- Memory profile of the driver
- ETL data movement
- Data shuffle across executors
- Job run metrics, including active executors, completed stages, and maximum needed executors
- Amazon SNS (9) – Amazon Simple Notification Service (Amazon SNS) automatically sends notifications to the support group on the error status of jobs, so they can take corrective action upon failure.
- Amazon RDS (10) – The final transformed data is stored in Amazon Relational Database Service (Amazon RDS) for PostgreSQL (in addition to Amazon S3) to support legacy reporting tools.
- Web application (11) – A web application is hosted on AWS Elastic Beanstalk, and is enabled with Auto Scaling exposed for clients to access the analytics data.
Implementation strategy
Implementing our solution included the following considerations:
- Security – The data required for running analytics is present in different data sources and different AWS accounts. We needed to craft well-thought-out role-based access policies for accessing the data.
- Selecting the right programming paradigm – PySpark does lazy evaluation while working with data frames. For PySpark to work efficiently with AWS Glue, we created data frames with required columns upfront and performed column-wise operations.
- Choosing the right persistence storage – Writing to Amazon S3 enables multiple consumption patterns, and writes are much faster due to parallelism.
If we’re writing to Amazon RDS (for supporting legacy systems), we need to watch out for database connectivity and buffer lock issues while writing from AWS Glue jobs.
- Data partitioning – Identifying the right key combination is important for partitioning the data for Spark to perform optimally. Our initial runs (without data partition) with 30 workers of type G2.x took 2 hours and 4 minutes to complete.
The following screenshot shows our CloudWatch metrics.
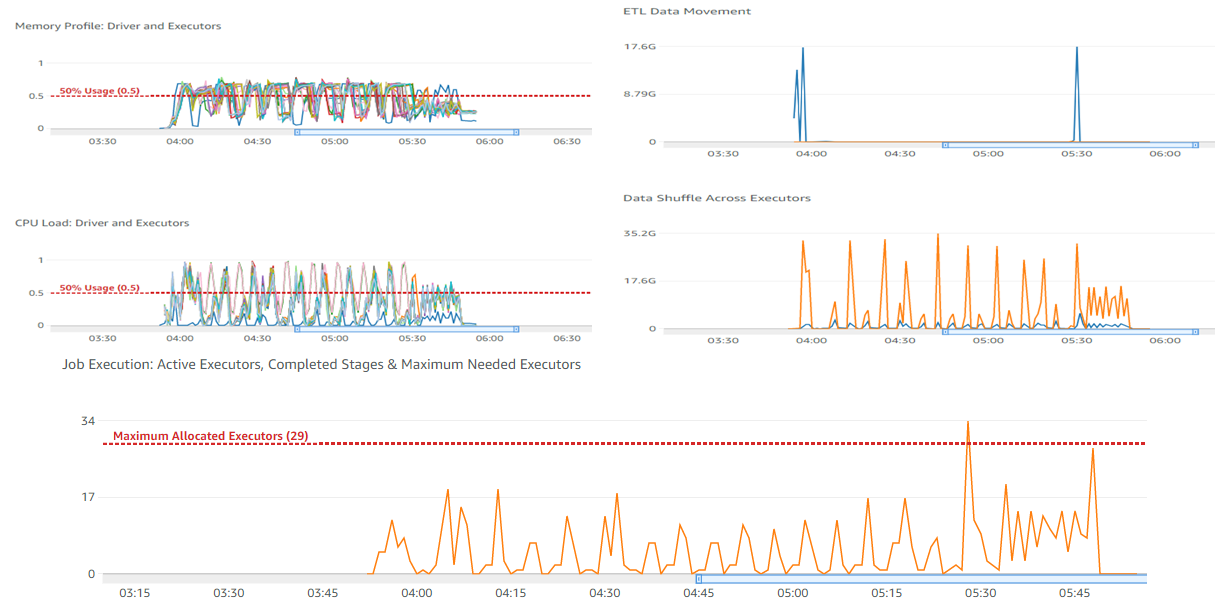
After a few dry runs, we were able to arrive at partitioning by a specific column (df.repartition(columnKey)) and with 24 workers of type G2.x, the job completed in 2 hours and 7 minutes. The following screenshot shows our new metrics.
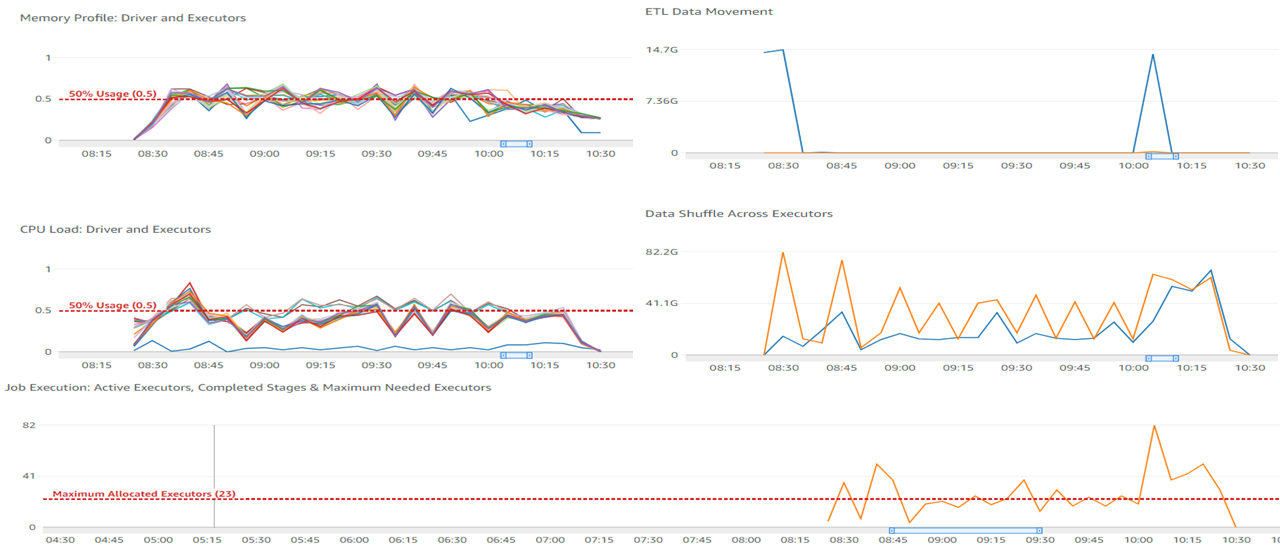
We can observe a difference in CPU and memory utilization—running with even fewer nodes shows a smaller CPU utilization and memory footprint.
The following table shows how we achieved the final transformation with the strategies we discussed.
| Iteration | Run Time | AWS Glue Job Status | Strategy |
| 1 | ~12 hours | Unsuccessful/Stopped | Initial iteration |
| 2 | ~9 hours | Unsuccessful/Stopped | Changing code to PySpark methodology |
| 3 | 5 hours, 11 minutes | Partial success | Splitting a complex large job into multiple jobs |
| 4 | 3 hours, 33 minutes | Success | Partitioning by column key |
| 5 | 2 hours, 39 minutes | Success | Changing CSV to Parquet file format while storing the copied data from another AWS account and intermediate results in the stage S3 bucket |
| 6 | 2 hours, 9 minutes | Success | Infra scaling: horizontal and vertical scaling |
Conclusion
In this post, we saw how to build a cost-effective, maintenance-free solution using serverless AWS services to process large-scale data. We also learned how to gain optimal AWS Glue job performance with key partitioning, using the Parquet data format while persisting in Amazon S3, splitting complex jobs into multiple jobs, and using the right programming paradigm.
As we continue to solidify our data lake solution for data from various sources, we can use Amazon Redshift Spectrum to serve various future analytical use cases.
About the Authors
 Giridhar G Jorapur is a Staff Infrastructure Architect at GE Aviation. In this role, he is responsible for designing enterprise applications, migration and modernization of applications to the cloud. Apart from work, Giri enjoys investing himself in spiritual wellness. Connect him on LinkedIn.
Giridhar G Jorapur is a Staff Infrastructure Architect at GE Aviation. In this role, he is responsible for designing enterprise applications, migration and modernization of applications to the cloud. Apart from work, Giri enjoys investing himself in spiritual wellness. Connect him on LinkedIn.