September 2025: This post was reviewed for accuracy.
AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry provides an open-source library that includes Apache-licensed serializers and deserializers for protobuf that integrate with Java applications developed for Apache Kafka, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Kinesis Data Streams, and Kafka Streams. Similar to Avro and JSON schemas, Protocol buffers schemas also support compatibility modes, schema sourcing via metadata, auto-registration of schemas, and AWS Identity and Access Management (IAM) compatibility.
In this post, we focus on Protocol buffers schema support in AWS Glue Schema Registry and how to use Protocol buffers schemas in stream processing Java applications that integrate with Apache Kafka, Amazon Managed Streaming for Apache Kafka and Amazon Kinesis Data Streams
Introduction to Protocol buffers
Protocol buffers is a language and platform-neutral, extensible mechanism for serializing and deserializing structured data for use in communications protocols and data storage. A protobuf message format is defined in the .proto file. Protobuf is recommended over other data formats when you need language interoperability, faster serialization and deserialization, type safety, schema adherence between data producer and consumer applications, and reduced coding effort. With protobuf, you can use generated code from the schema using the protobuf compiler (protoc) to easily write and read your data to and from data streams using a variety of languages. You can also use build tools plugins such as Maven and Gradle to generate code from protobuf schemas as part of your CI/CD pipelines. We use the following schema for code examples in this post, which defines an employee with a gRPC service definition to find an employee by ID:
Employee.proto
syntax = "proto2";
package gsr.proto.post;
import "google/protobuf/wrappers.proto";
import "google/protobuf/duration.proto";
import "google/protobuf/timestamp.proto";
import "google/type/money.proto";
service EmployeeSearch {
rpc FindEmployee(EmployeeSearchParams) returns (Employee);
}
message EmployeeSearchParams {
required int32 id = 1;
}
message Employee {
required int32 id = 1;
required string name = 2;
required string address = 3;
required google.protobuf.Int32Value employee_age = 4;
required google.protobuf.Timestamp start_date = 5;
required google.protobuf.Duration total_time_span_in_company = 6;
required google.protobuf.BoolValue is_certified = 7;
required Team team = 8;
required Project project = 9;
required Role role = 10;
required google.type.Money total_award_value = 11;
}
message Team {
required string name = 1;
required string location = 2;
}
message Project {
required string name = 1;
required string state = 2;
}
enum Role {
MANAGER = 0;
DEVELOPER = 1;
ARCHITECT = 2;
}
AWS Glue Schema Registry supports both proto2 and proto3 syntax. The preceding protobuf schema using version 2 contains three message types: Employee, Team, and Project using scalar, composite, and enumeration data types. Each field in the message definitions has a unique number, which is used to identify fields in the message binary format, and should not be changed once your message type is in use. In a proto2 message, a field can be required, optional, or repeated; in proto3, the options are repeated and optional. The package declaration makes sure generated code is namespaced to avoid any collisions. In addition to scalar, composite, and enumeration types, AWS Glue Schema Registry also supports protobuf schemas with common types such as Money, PhoneNumber,Timestamp, Duration, and nullable types such as BoolValue and Int32Value. It also supports protobuf schemas with gRPC service definitions with compatibility rules, such as EmployeeSearch, in the preceding schema. To learn more about the Protocol buffers, refer to its documentation.
Supported Protocol buffers specification and features
AWS Glue Schema Registry supports all the features of Protocol buffers for versions 2 and 3 except for groups, extensions, and importing definitions. AWS Glue Schema Registry APIs and its open-source library supports the latest protobuf runtime version. The protobuf schema operations in AWS Glue Schema Registry are supported via the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Glue Schema Registry API, AWS SDK, and AWS CloudFormation.
How AWS Glue Schema Registry works
The following diagram illustrates a high-level view of how AWS Glue Schema Registry works. AWS Glue Schema Registry allows you to register and evolve JSON, Apache Avro, and Protocol buffers schemas with compatibility modes. You can register multiple versions of each schema as the business needs or stream processing application’s requirements evolve. The AWS Glue Schema Registry open-source library provides JSON, Avro, and protobuf serializers and deserializers that you configure in producer and consumer stream processing applications, as shown in the following diagram. The open-source library also supports optional compression and caching configuration to save on data transfers.

To accommodate various business use cases, AWS Glue Schema Registry supports multiple compatibility modes. For example, if a consumer application is updated to a new schema version but is still able to consume and process messages based on the previous version of the same schema, then the schema is backward-compatible. However, if a schema version has bumped up in the producer application and the consumer application is not updated yet but can still consume and process the old and new message, then the schema is configured as forward-compatible. For more information, refer to How the Schema Registry Works.
Create a Protocol buffers schema in AWS Glue Schema Registry
In this section, we create a protobuf schema in AWS Glue Schema Registry via the console and AWS CLI.
Create a schema via the console
Make sure you have the required AWS Glue Schema Registry IAM permissions.
- On the AWS Glue console, choose Stream Schema registries in the navigation pane.
- Click Add registry.
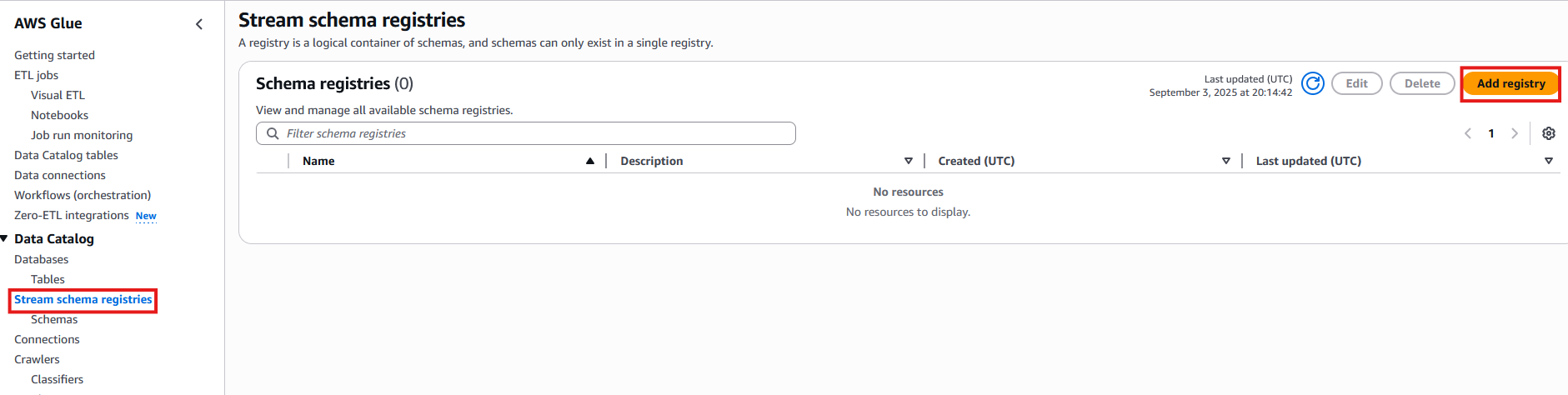
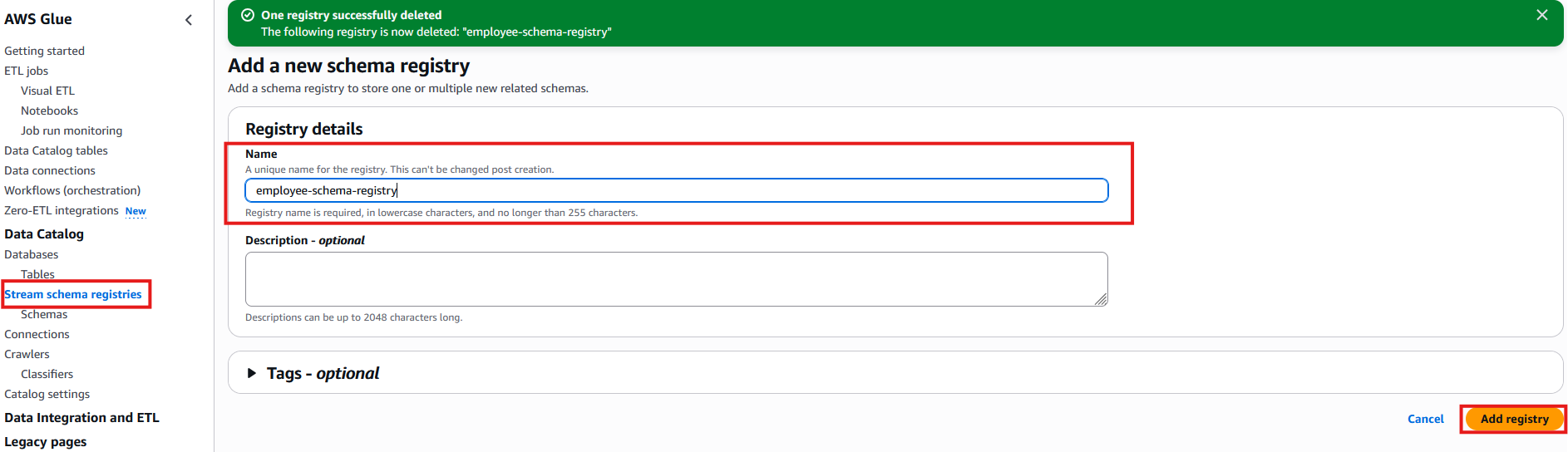
- For Registry name, enter
employee-schema-registry.
- Click Add Registry.
- Click on
employee-schema-registry

- After the registry is created, click Create schema to register a new schema.
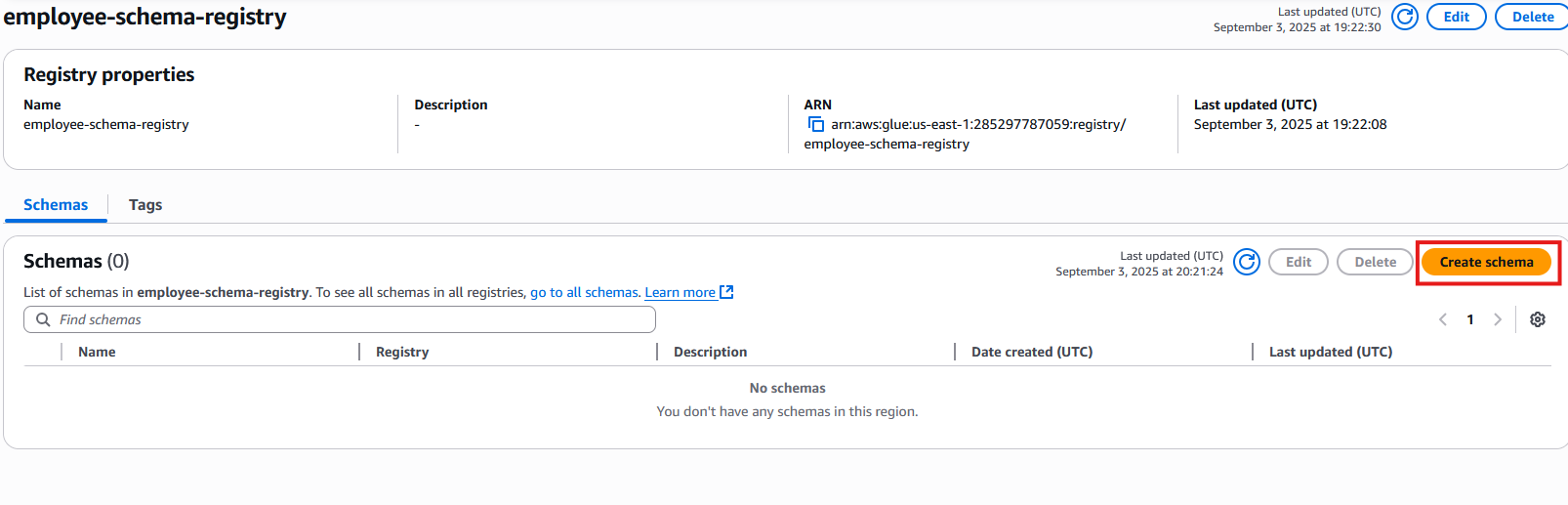
- For Schema name, enter
Employee.proto.
The schema must be either Employee.proto or Employee if the protobuf schema doesn’t have the options option java_multiple_files = true; and option java_outer_classname = "<Outer class name>"; and if you decide to use protobuf schema generated code (POJOs) in your stream processing applications. We cover this with an example in a subsequent section of this post. For more information on protobuf options, refer to Options.
- For Registry, choose the
registry employee-schema-registry.
- For Data format, choose Protocol buffers.
- For Compatibility mode, choose Backward.
You can choose other compatibility modes as per your use case.
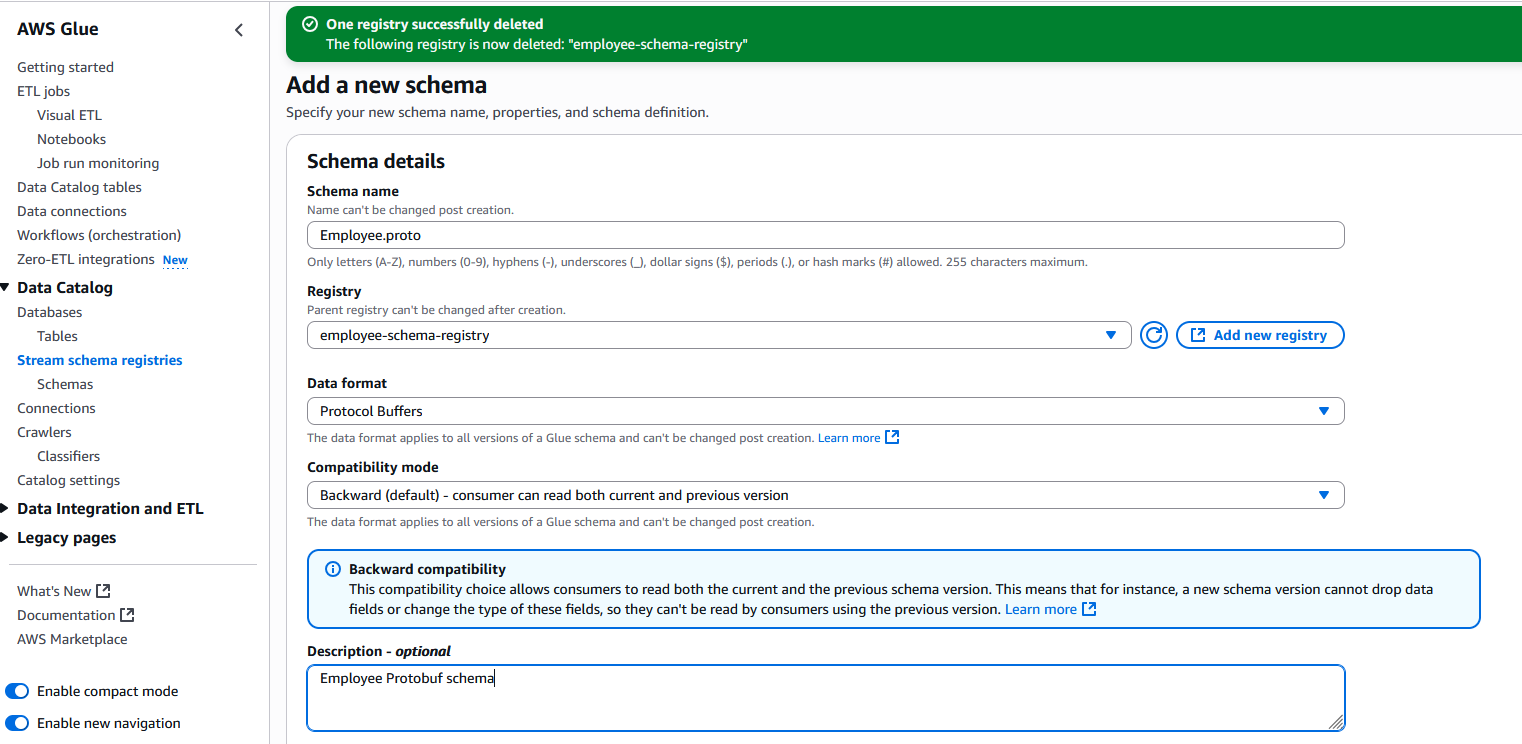
- For First schema version, enter the preceding protobuf schema, then click Create schema and version.
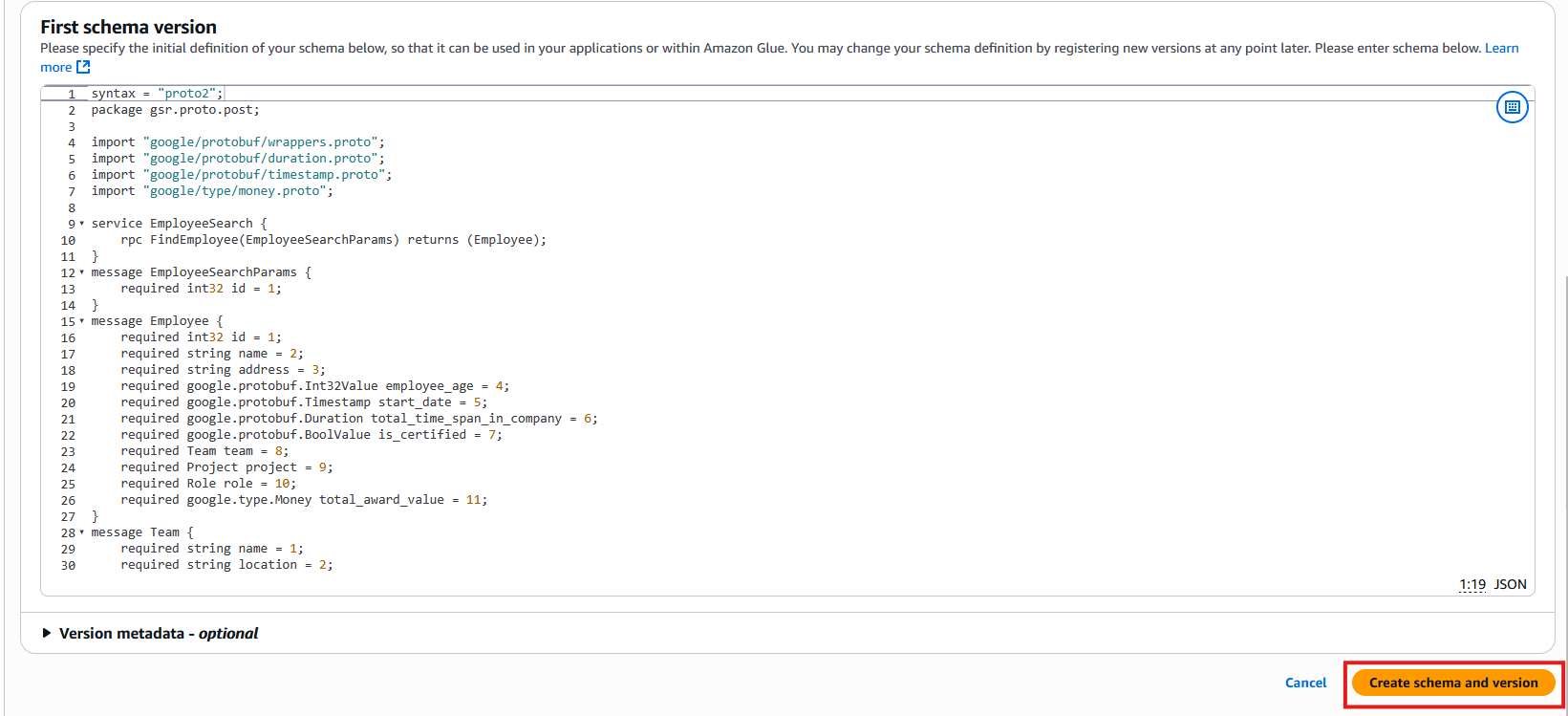
After the schema is registered successfully, its status will be Available, as shown in the following screenshot.
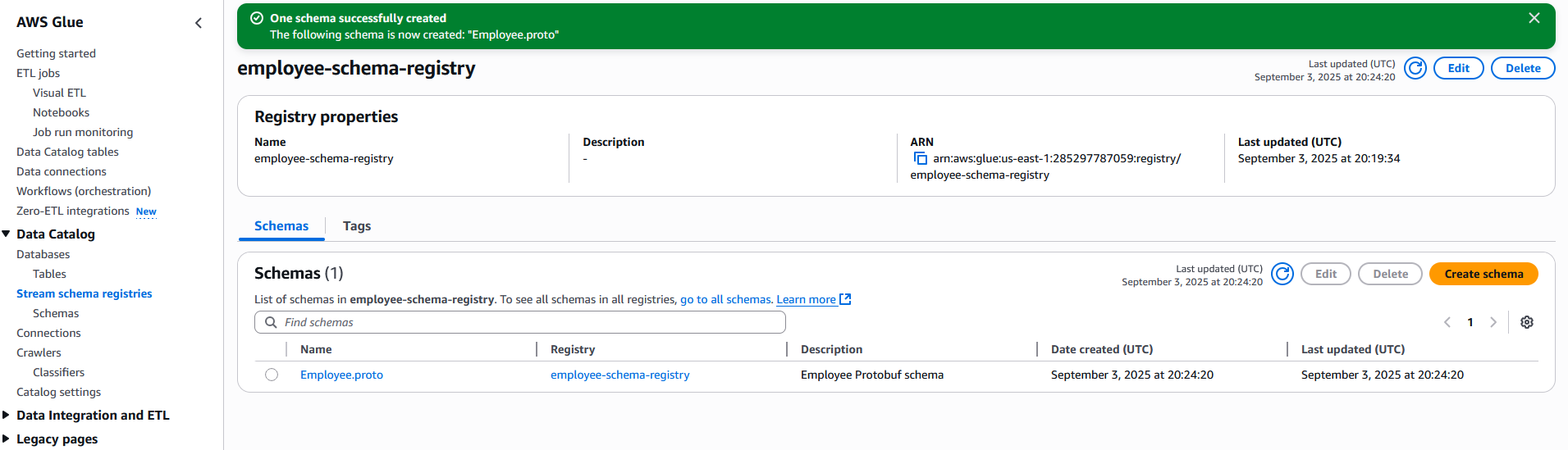
Create a schema via the AWS CLI
Make sure you have IAM credentials with AWS Glue Schema Registry permissions.
- Run the following AWS CLI command to create a schema registry
employee-schema-registry (for this post, we use the Region us-east-2):
aws glue create-registry \
--registry-name employee-schema-registry \
--region us-east-2
The AWS CLI command returns the newly created schema registry ARN in response.
- Copy the
RegistryArn value from the response to use in the following AWS CLI command.
- In the following command, use the preceding protobuf schema and schema name
Employee.proto:
aws glue create-schema --schema-name Employee.proto \
--registry-id RegistryArn=<Schema Registry ARN that you copied from response of create registry CLI command> \
--compatibility BACKWARD \
--data-format PROTOBUF \
--schema-definition file:///<project-directory>/Employee.proto \
--region us-east-2
You can also use AWS CloudFormation to create schemas in AWS Glue Schema Registry.
Using a Protocol buffers schema with Amazon MSK and Kinesis Data Streams
Like Apache Avro’s SpecificRecord and GenericRecord, protobuf also supports working with POJOs to ensure type safety and DynamicMessage to create generic data producer and consumer applications. The following examples showcase the use of a protobuf schema registered in AWS Glue Schema Registry with Kafka and Kinesis Data Streams producer and consumer applications.
Use a protobuf schema with Amazon MSK
Create an Amazon MSK or Apache Kafka cluster with a topic called protobuf-demo-topic. If creating an Amazon MSK cluster, you can use the console. For instructions, refer to Getting Started Using Amazon MSK.
Use protobuf schema-generated POJOs
To use protobuf schema-generated POJOs, complete the following steps:
- Install the protobuf compiler (
protoc) on your local machine from GitHub and add it in the PATH variable.
- Add the following plugin configuration to your application’s pom.xml file. We use the xolstice protobuf Maven plugin for this post to generate code from the protobuf schema.
<plugin>
<!-- https://www.xolstice.org/protobuf-maven-plugin/usage.html -->
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<protoSourceRoot>${basedir}/src/main/resources/proto</protoSourceRoot>
<outputDirectory>${basedir}/src/main/java</outputDirectory>
<clearOutputDirectory>false</clearOutputDirectory>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
- Add the following dependencies to your application’s pom.xml file:
<!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.19.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/software.amazon.glue/schema-registry-serde -->
<dependency>
<groupId>software.amazon.glue</groupId>
<artifactId>schema-registry-serde</artifactId>
<version>1.1.9</version>
</dependency>
- Create a schema
registry employee-schema-registry in AWS Glue Schema Registry and register the Employee.proto protobuf schema with it. Name your schema Employee.proto (or Employee).
- Run the following command to generate the code from
Employee.proto. Make sure you have the schema file in the ${basedir}/src/main/resources/proto directory or change it as per your application directory structure in the application’s pom.xml <protoSourceRoot> tag value:
Next, we configure the Kafka producer publishing protobuf messages to the Kafka topic on Amazon MSK.
- Configure the Kafka producer properties:
private Properties getProducerConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, this.bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, GlueSchemaRegistryKafkaSerializer.class.getName());
props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.PROTOBUF.name());
props.put(AWSSchemaRegistryConstants.AWS_REGION,"us-east-2");
props.put(AWSSchemaRegistryConstants.REGISTRY_NAME, "employee-schema-registry");
props.put(AWSSchemaRegistryConstants.SCHEMA_NAME, "Employee.proto");
props.put(AWSSchemaRegistryConstants.PROTOBUF_MESSAGE_TYPE, ProtobufMessageType.POJO.getName());
return props;
}
The VALUE_SERIALIZER_CLASS_CONFIG configuration specifies the AWS Glue Schema Registry serializer, which serializes the protobuf message.
- Use the schema-generated code (POJOs) to create a protobuf message:
public EmployeeOuterClass.Employee createEmployeeRecord(int employeeId){
EmployeeOuterClass.Employee employee =
EmployeeOuterClass.Employee.newBuilder()
.setId(employeeId)
.setName("Dummy")
.setAddress("Melbourne, Australia")
.setEmployeeAge(Int32Value.newBuilder().setValue(32).build())
.setStartDate(Timestamp.newBuilder().setSeconds(235234532434L).build())
.setTotalTimeSpanInCompany(Duration.newBuilder().setSeconds(3453245345L).build())
.setIsCertified(BoolValue.newBuilder().setValue(true).build())
.setRole(EmployeeOuterClass.Role.ARCHITECT)
.setProject(EmployeeOuterClass.Project.newBuilder()
.setName("Protobuf Schema Demo")
.setState("GA").build())
.setTotalAwardValue(Money.newBuilder()
.setCurrencyCode("USD")
.setUnits(5)
.setNanos(50000).build())
.setTeam(EmployeeOuterClass.Team.newBuilder()
.setName("Solutions Architects")
.setLocation("Australia").build()).build();
return employee;
}
- Publish the protobuf messages to the
protobuf-demo-topic topic on Amazon MSK:
public void startProducer() throws InterruptedException {
String topic = "protobuf-demo-topic";
KafkaProducer<String, EmployeeOuterClass.Employee> producer = new KafkaProducer<String, EmployeeOuterClass.Employee>(getProducerConfig());
logger.info("Starting to send records...");
int employeeId = 0;
while(employeeId < 100)
{
EmployeeOuterClass.Employee person = createEmployeeRecord(employeeId);
String key = "key-" + employeeId;
ProducerRecord<String, EmployeeOuterClass.Employee> record = new ProducerRecord<String, EmployeeOuterClass.Employee>(topic, key, person);
producer.send(record, new ProducerCallback());
employeeId++;
}
}
private class ProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetaData, Exception e){
if (e == null) {
logger.info("Received new metadata. \n" +
"Topic:" + recordMetaData.topic() + "\n" +
"Partition: " + recordMetaData.partition() + "\n" +
"Offset: " + recordMetaData.offset() + "\n" +
"Timestamp: " + recordMetaData.timestamp());
}
else {
logger.info("There's been an error from the Producer side");
e.printStackTrace();
}
}
}
- Start the Kafka producer:
public static void main(String args[]) throws InterruptedException {
ProducerProtobuf producer = new ProducerProtobuf();
producer.startProducer();
}
- In the Kafka consumer application’s pom.xml, add the same plugin and dependencies as the Kafka producer’s pom.xml.
Next, we configure the Kafka consumer consuming protobuf messages from the Kafka topic on Amazon MSK.
- Configure the Kafka consumer properties:
private Properties getConsumerConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, this.bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "protobuf-consumer");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, GlueSchemaRegistryKafkaDeserializer.class.getName());
props.put(AWSSchemaRegistryConstants.AWS_REGION,"us-east-2");
props.put(AWSSchemaRegistryConstants.PROTOBUF_MESSAGE_TYPE, ProtobufMessageType.POJO.getName());
return props;
}
The VALUE_DESERIALIZER_CLASS_CONFIG config specifies the AWS Glue Schema Registry deserializer that deserializes the protobuf messages.
- Consume the protobuf message (as a POJO) from the
protobuf-demo-topic topic on Amazon MSK:
public void startConsumer() {
logger.info("starting consumer...");
String topic = "protobuf-demo-topic";
KafkaConsumer<String, EmployeeOuterClass.Employee> consumer = new KafkaConsumer<String, EmployeeOuterClass.Employee>(getConsumerConfig());
consumer.subscribe(Collections.singletonList(topic));
while (true) {
final ConsumerRecords<String, EmployeeOuterClass.Employee> records = consumer.poll(Duration.ofMillis(1000));
for (final ConsumerRecord<String, EmployeeOuterClass.Employee> record : records) {
final EmployeeOuterClass.Employee employee = record.value();
logger.info("Employee Id: " + employee.getId() + " | Name: " + employee.getName() + " | Address: " + employee.getAddress() +
" | Age: " + employee.getEmployeeAge().getValue() + " | Startdate: " + employee.getStartDate().getSeconds() +
" | TotalTimeSpanInCompany: " + employee.getTotalTimeSpanInCompany() +
" | IsCertified: " + employee.getIsCertified().getValue() + " | Team: " + employee.getTeam().getName() +
" | Role: " + employee.getRole().name() + " | Project State: " + employee.getProject().getState() +
" | Project Name: " + employee.getProject().getName() + "| Award currency code: " + employee.getTotalAwardValue().getCurrencyCode() +
" | Award units : " + employee.getTotalAwardValue().getUnits() + " | Award nanos " + employee.getTotalAwardValue().getNanos());
}
}
}
- Start the Kafka consumer:
public static void main(String args[]){
ConsumerProtobuf consumer = new ConsumerProtobuf();
consumer.startConsumer();
}
Use protobuf’s DynamicMessage
You can use DynamicMessage to create generic producer and consumer applications without generating the code from the protobuf schema. To use DynamicMessage, you first need to create a protobuf schema file descriptor.
- Generate a file descriptor from the protobuf schema using the following command:
protoc --include_imports --proto_path=proto --descriptor_set_out=proto/Employeeproto.desc proto/Employee.proto
The option --descritor_set_out has the descriptor file name that this command generates. The protobuf schema Employee.proto is in the proto directory.
- Make sure you have created a schema registry and registered the preceding protobuf schema with it.
Now we configure the Kafka producer publishing DynamicMessage to the Kafka topic on Amazon MSK.
- Create the Kafka producer configuration. The
PROTOBUF_MESSAGE_TYPE configuration is DYNAMIC_MESSAGE instead of POJO.
private Properties getProducerConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, this.bootstrapServers);
props.put(ProducerConfig.ACKS_CONFIG, "-1");
props.put(ProducerConfig.CLIENT_ID_CONFIG,"protobuf-dynamicmessage-record-producer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,GlueSchemaRegistryKafkaSerializer.class.getName());
props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.PROTOBUF.name());
props.put(AWSSchemaRegistryConstants.AWS_REGION,"us-east-2");
props.put(AWSSchemaRegistryConstants.REGISTRY_NAME, "employee-schema-registry");
props.put(AWSSchemaRegistryConstants.SCHEMA_NAME, "Employee.proto");
props.put(AWSSchemaRegistryConstants.PROTOBUF_MESSAGE_TYPE, ProtobufMessageType.DYNAMIC_MESSAGE.getName());
return props;
}
- Create protobuf dynamic messages and publish them to the Kafka topic on Amazon MSK:
public void startProducer() throws Exception {
Descriptor desc = getDescriptor();
String topic = "protobuf-demo-topic";
KafkaProducer<String, DynamicMessage> producer = new KafkaProducer<String, DynamicMessage>(getProducerConfig());
logger.info("Starting to send records...");
int i = 0;
while (i < 100) {
DynamicMessage dynMessage = DynamicMessage.newBuilder(desc)
.setField(desc.findFieldByName("id"), 1234)
.setField(desc.findFieldByName("name"), "Dummy Name")
.setField(desc.findFieldByName("address"), "Melbourne, Australia")
.setField(desc.findFieldByName("employee_age"), Int32Value.newBuilder().setValue(32).build())
.setField(desc.findFieldByName("start_date"), Timestamp.newBuilder().setSeconds(235234532434L).build())
.setField(desc.findFieldByName("total_time_span_in_company"), Duration.newBuilder().setSeconds(3453245345L).build())
.setField(desc.findFieldByName("is_certified"), BoolValue.newBuilder().setValue(true).build())
.setField(desc.findFieldByName("total_award_value"), Money.newBuilder().setCurrencyCode("USD")
.setUnits(1).setNanos(50000).build())
.setField(desc.findFieldByName("team"), createTeam(desc.findFieldByName("team").getMessageType()))
.setField(desc.findFieldByName("project"), createProject(desc.findFieldByName("project").getMessageType()))
.setField(desc.findFieldByName("role"), desc.findFieldByName("role").getEnumType().findValueByName("ARCHITECT"))
.build();
String key = "key-" + i;
ProducerRecord<String, DynamicMessage> record = new ProducerRecord<String, DynamicMessage>(topic, key, dynMessage);
producer.send(record, new ProtobufProducer.ProducerCallback());
Thread.sleep(1000);
i++;
}
}
private static DynamicMessage createTeam(Descriptor desc) {
DynamicMessage dynMessage = DynamicMessage.newBuilder(desc)
.setField(desc.findFieldByName("name"), "Solutions Architects")
.setField(desc.findFieldByName("location"), "Australia")
.build();
return dynMessage;
}
private static DynamicMessage createProject(Descriptor desc) {
DynamicMessage dynMessage = DynamicMessage.newBuilder(desc)
.setField(desc.findFieldByName("name"), "Protobuf Schema Demo")
.setField(desc.findFieldByName("state"), "GA")
.build();
return dynMessage;
}
private class ProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetaData, Exception e) {
if (e == null) {
logger.info("Received new metadata. \n" +
"Topic:" + recordMetaData.topic() + "\n" +
"Partition: " + recordMetaData.partition() + "\n" +
"Offset: " + recordMetaData.offset() + "\n" +
"Timestamp: " + recordMetaData.timestamp());
} else {
logger.info("There's been an error from the Producer side");
e.printStackTrace();
}
}
}
- Create a descriptor using the
Employeeproto.desc file that we generated from the Employee.proto schema file in the previous steps:
private Descriptor getDescriptor() throws Exception {
InputStream inStream = ProtobufProducer.class.getClassLoader().getResourceAsStream("proto/Employeeproto.desc");
DescriptorProtos.FileDescriptorSet fileDescSet = DescriptorProtos.FileDescriptorSet.parseFrom(inStream);
Map<String, DescriptorProtos.FileDescriptorProto> fileDescProtosMap = new HashMap<String, DescriptorProtos.FileDescriptorProto>();
List<DescriptorProtos.FileDescriptorProto> fileDescProtos = fileDescSet.getFileList();
for (DescriptorProtos.FileDescriptorProto fileDescProto : fileDescProtos) {
fileDescProtosMap.put(fileDescProto.getName(), fileDescProto);
}
DescriptorProtos.FileDescriptorProto fileDescProto = fileDescProtosMap.get("Employee.proto");
FileDescriptor[] dependencies = getProtoDependencies(fileDescProtosMap, fileDescProto);
FileDescriptor fileDesc = FileDescriptor.buildFrom(fileDescProto, dependencies);
Descriptor desc = fileDesc.findMessageTypeByName("Employee");
return desc;
}
public static FileDescriptor[] getProtoDependencies(Map<String, FileDescriptorProto> fileDescProtos,
FileDescriptorProto fileDescProto) throws Exception {
if (fileDescProto.getDependencyCount() == 0)
return new FileDescriptor[0];
ProtocolStringList dependencyList = fileDescProto.getDependencyList();
String[] dependencyArray = dependencyList.toArray(new String[0]);
int noOfDependencies = dependencyList.size();
FileDescriptor[] dependencies = new FileDescriptor[noOfDependencies];
for (int i = 0; i < noOfDependencies; i++) {
FileDescriptorProto dependencyFileDescProto = fileDescProtos.get(dependencyArray[i]);
FileDescriptor dependencyFileDesc = FileDescriptor.buildFrom(dependencyFileDescProto,
getProtoDependencies(fileDescProtos, dependencyFileDescProto));
dependencies[i] = dependencyFileDesc;
}
return dependencies;
}
- Start the Kafka producer:
public static void main(String args[]) throws InterruptedException {
ProducerProtobuf producer = new ProducerProtobuf();
producer.startProducer();
}
Now we configure the Kafka consumer consuming dynamic messages from the Kaka topic on Amazon MSK.
- Enter the following Kafka consumer configuration:
private Properties getConsumerConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, this.bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "protobuf-record-consumer");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, GlueSchemaRegistryKafkaDeserializer.class.getName());
props.put(AWSSchemaRegistryConstants.AWS_REGION,"us-east-2");
props.put(AWSSchemaRegistryConstants.PROTOBUF_MESSAGE_TYPE, ProtobufMessageType.DYNAMIC_MESSAGE.getName());
return props;
}
- Consume protobuf dynamic messages from the Kafka topic
protobuf-demo-topic. Because we’re using DYNAMIC_MESSAGE, the retrieved objects are of type DynamicMessage.
public void startConsumer() {
logger.info("starting consumer...");
String topic = "protobuf-demo-topic";
KafkaConsumer<String, DynamicMessage> consumer = new KafkaConsumer<String, DynamicMessage>(getConsumerConfig());
consumer.subscribe(Collections.singletonList(topic));
while (true) {
final ConsumerRecords<String, DynamicMessage> records = consumer.poll(Duration.ofMillis(1000));
for (final ConsumerRecord<String, DynamicMessage> record : records) {
for (Descriptors.FieldDescriptor field : record.value().getAllFields().keySet()) {
logger.info(field.getName() + ": " + record.value().getField(field));
}
}
}
}
- Start the Kafka consumer:
public static void main(String args[]){
ConsumerProtobuf consumer = new ConsumerProtobuf();
consumer.startConsumer();
}
Use a protobuf schema with Kinesis Data Streams
You can use the protobuf schema-generated POJOs with the Kinesis Producer Library (KPL) and Kinesis Client Library (KCL).
- Install the protobuf compiler (
protoc) on your local machine from GitHub and add it in the PATH variable.
- Add the following plugin configuration to your application’s pom.xml file. We’re using the xolstice protobuf Maven plugin for this post to generate code from the protobuf schema.
<plugin>
<!-- https://www.xolstice.org/protobuf-maven-plugin/usage.html -->
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<protoSourceRoot>${basedir}/src/main/resources/proto</protoSourceRoot>
<outputDirectory>${basedir}/src/main/java</outputDirectory>
<clearOutputDirectory>false</clearOutputDirectory>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
- Because the KPL and KCL latest versions have the AWS Glue Schema Registry open-source library (
schema-registry-serde) and protobuf runtime (protobuf-java) included, you only need to add the following dependencies to your application’s pom.xml:
<!-- https://mvnrepository.com/artifact/com.amazonaws/amazon-kinesis-producer -->
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>amazon-kinesis-producer</artifactId>
<version>0.14.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/software.amazon.kinesis/amazon-kinesis-client -->
<dependency>
<groupId>software.amazon.kinesis</groupId>
<artifactId>amazon-kinesis-client</artifactId>
<version>2.4.0version>
</dependency>
- Create a schema registry
employee-schema-registry and register the Employee.proto protobuf schema with it. Name your schema Employee.proto (or Employee).
- Run the following command to generate the code from
Employee.proto. Make sure you have the schema file in the ${basedir}/src/main/resources/proto directory or change it as per your application directory structure in the application’s pom.xml <protoSourceRoot> tag value.
The following Kinesis producer code with the KPL uses the Schema Registry open-source library to publish protobuf messages to Kinesis Data Streams.
- Start the Kinesis Data Streams producer:
private static final String PROTO_SCHEMA_FILE = "proto/Employee.proto";
private static final String SCHEMA_NAME = "Employee.proto";
private static String REGION_NAME = "us-east-2";
private static String REGISTRY_NAME = "employee-schema-registry";
private static String STREAM_NAME = "employee_data_stream";
private static int NUM_OF_RECORDS = 100;
private static String REGISTRY_ENDPOINT = "https://glue.us-east-2.amazonaws.com";
public static void main(String[] args) throws Exception {
ProtobufKPLProducer producer = new ProtobufKPLProducer();
producer.startProducer();
}
}
- Configure the Kinesis producer:
public void startProducer() throws Exception {
logger.info("Starting KPL client with Glue Schema Registry Integration...");
GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(REGION_NAME);
schemaRegistryConfig.setCompressionType(AWSSchemaRegistryConstants.COMPRESSION.ZLIB);
schemaRegistryConfig.setSchemaAutoRegistrationEnabled(false);
schemaRegistryConfig.setCompatibilitySetting(Compatibility.BACKWARD);
schemaRegistryConfig.setEndPoint(REGISTRY_ENDPOINT);
schemaRegistryConfig.setProtobufMessageType(ProtobufMessageType.POJO);
schemaRegistryConfig.setRegistryName(REGISTRY_NAME);
//Setting Glue Schema Registry configuration in Kinesis Producer Configuration along with other configs
KinesisProducerConfiguration config = new KinesisProducerConfiguration()
.setRecordMaxBufferedTime(3000)
.setMaxConnections(1)
.setRequestTimeout(60000)
.setRegion(REGION_NAME)
.setRecordTtl(60000)
.setGlueSchemaRegistryConfiguration(schemaRegistryConfig);
FutureCallback<UserRecordResult> myCallback = new FutureCallback<UserRecordResult>() {
@Override public void onFailure(Throwable t) {
t.printStackTrace();
};
@Override public void onSuccess(UserRecordResult result) {
logger.info("record sent successfully. Sequence Number: " + result.getSequenceNumber() + " | Shard Id : " + result.getShardId());
};
};
//Creating schema definition object from the Employee.proto schema file.
Schema gsrSchema = getSchemaDefinition();
final KinesisProducer producer = new KinesisProducer(config);
int employeeCount = 1;
while(true) {
//Creating and serializing schema generated POJO object (protobuf message)
EmployeeOuterClass.Employee employee = createEmployeeRecord(employeeCount);
byte[] serializedBytes = employee.toByteArray();
ByteBuffer data = ByteBuffer.wrap(serializedBytes);
Instant timestamp = Instant.now();
//Publishing protobuf message to the Kinesis Data Stream
ListenableFuture<UserRecordResult> f =
producer.addUserRecord(STREAM_NAME,
Long.toString(timestamp.toEpochMilli()),
new BigInteger(128, new Random()).toString(10),
data,
gsrSchema);
Futures.addCallback(f, myCallback, MoreExecutors.directExecutor());
employeeCount++;
if(employeeCount > NUM_OF_RECORDS)
break;
}
List<Future<UserRecordResult>> putFutures = new LinkedList<>();
for (Future<UserRecordResult> future : putFutures) {
UserRecordResult userRecordResult = future.get();
logger.info(userRecordResult.getShardId() + userRecordResult.getSequenceNumber());
}
}
- Create a protobuf message using schema-generated code (POJOs):
public EmployeeOuterClass.Employee createEmployeeRecord(int count){
EmployeeOuterClass.Employee employee =
EmployeeOuterClass.Employee.newBuilder()
.setId(count)
.setName("Dummy")
.setAddress("Melbourne, Australia")
.setEmployeeAge(Int32Value.newBuilder().setValue(32).build())
.setStartDate(Timestamp.newBuilder().setSeconds(235234532434L).build())
.setTotalTimeSpanInCompany(Duration.newBuilder().setSeconds(3453245345L).build())
.setIsCertified(BoolValue.newBuilder().setValue(true).build())
.setRole(EmployeeOuterClass.Role.ARCHITECT)
.setProject(EmployeeOuterClass.Project.newBuilder()
.setName("Protobuf Schema Demo")
.setState("GA").build())
.setTotalAwardValue(Money.newBuilder()
.setCurrencyCode("USD")
.setUnits(5)
.setNanos(50000).build())
.setTeam(EmployeeOuterClass.Team.newBuilder()
.setName("Solutions Architects")
.setLocation("Australia").build()).build();
return employee;
}
- Create the schema definition from
Employee.proto:
private Schema getSchemaDefinition() throws IOException {
InputStream inputStream = ProtobufKPLProducer.class.getClassLoader().getResourceAsStream(PROTO_SCHEMA_FILE);
StringBuilder resultStringBuilder = new StringBuilder();
try (BufferedReader br = new BufferedReader(new InputStreamReader(inputStream))) {
String line;
while ((line = br.readLine()) != null) {
resultStringBuilder.append(line).append("\n");
}
}
String schemaDefinition = resultStringBuilder.toString();
logger.info("Schema Definition " + schemaDefinition);
Schema gsrSchema =
new Schema(schemaDefinition, DataFormat.PROTOBUF.toString(), SCHEMA_NAME);
return gsrSchema;
}
The following is the Kinesis consumer code with the KCL using the Schema Registry open-source library to consume protobuf messages from the Kinesis Data Streams.
- Initialize the application:
public void run(){
logger.info("Starting KCL client with Glue Schema Registry Integration...");
Region region = Region.of(ObjectUtils.firstNonNull(REGION_NAME, "us-east-2"));
KinesisAsyncClient kinesisClient = KinesisClientUtil.createKinesisAsyncClient(KinesisAsyncClient.builder().region(region));
DynamoDbAsyncClient dynamoClient = DynamoDbAsyncClient.builder().region(region).build();
CloudWatchAsyncClient cloudWatchClient = CloudWatchAsyncClient.builder().region(region).build();
EmployeeRecordProcessorFactory employeeRecordProcessorFactory = new EmployeeRecordProcessorFactory();
ConfigsBuilder configsBuilder =
new ConfigsBuilder(STREAM_NAME,
APPLICATION_NAME,
kinesisClient,
dynamoClient,
cloudWatchClient,
APPLICATION_NAME,
employeeRecordProcessorFactory);
//Creating Glue Schema Registry configuration and Glue Schema Registry Deserializer object.
GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration(region.toString());
gsrConfig.setEndPoint(REGISTRY_ENDPOINT);
gsrConfig.setProtobufMessageType(ProtobufMessageType.POJO);
GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer =
new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), gsrConfig);
/*
Setting Glue Schema Registry deserializer in the Retrieval Config for
Kinesis Client Library to use it while deserializing the protobuf messages.
*/
RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(STREAM_NAME, kinesisClient));
retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer);
Scheduler scheduler = new Scheduler(
configsBuilder.checkpointConfig(),
configsBuilder.coordinatorConfig(),
configsBuilder.leaseManagementConfig(),
configsBuilder.lifecycleConfig(),
configsBuilder.metricsConfig(),
configsBuilder.processorConfig(),
retrievalConfig);
Thread schedulerThread = new Thread(scheduler);
schedulerThread.setDaemon(true);
schedulerThread.start();
logger.info("Press enter to shutdown");
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
try {
reader.readLine();
Future<Boolean> gracefulShutdownFuture = scheduler.startGracefulShutdown();
logger.info("Waiting up to 20 seconds for shutdown to complete.");
gracefulShutdownFuture.get(20, TimeUnit.SECONDS);
} catch (Exception e) {
logger.info("Interrupted while waiting for graceful shutdown. Continuing.");
}
logger.info("Completed, shutting down now.");
}
- Consume protobuf messages from Kinesis Data Streams:
public static class EmployeeRecordProcessorFactory implements ShardRecordProcessorFactory {
@Override
public ShardRecordProcessor shardRecordProcessor() {
return new EmployeeRecordProcessor();
}
}
public static class EmployeeRecordProcessor implements ShardRecordProcessor {
private static final Logger logger = Logger.getLogger(EmployeeRecordProcessor.class.getSimpleName());
public void initialize(InitializationInput initializationInput) {}
public void processRecords(ProcessRecordsInput processRecordsInput) {
try {
logger.info("Processing " + processRecordsInput.records().size() + " record(s)");
for (KinesisClientRecord r : processRecordsInput.records()) {
//Deserializing protobuf message into schema generated POJO
EmployeeOuterClass.Employee employee = EmployeeOuterClass.Employee.parseFrom(r.data().array());
logger.info("Processed record: " + employee);
logger.info("Employee Id: " + employee.getId() + " | Name: " + employee.getName() + " | Address: " + employee.getAddress() +
" | Age: " + employee.getEmployeeAge().getValue() + " | Startdate: " + employee.getStartDate().getSeconds() +
" | TotalTimeSpanInCompany: " + employee.getTotalTimeSpanInCompany() +
" | IsCertified: " + employee.getIsCertified().getValue() + " | Team: " + employee.getTeam().getName() +
" | Role: " + employee.getRole().name() + " | Project State: " + employee.getProject().getState() +
" | Project Name: " + employee.getProject().getName() + " | Award currency code: " +
employee.getTotalAwardValue().getCurrencyCode() + " | Award units : " + employee.getTotalAwardValue().getUnits() +
" | Award nanos " + employee.getTotalAwardValue().getNanos());
}
} catch (Exception e) {
logger.info("Failed while processing records. Aborting" + e);
Runtime.getRuntime().halt(1);
}
}
public void leaseLost(LeaseLostInput leaseLostInput) {. . .}
public void shardEnded(ShardEndedInput shardEndedInput) {. . .}
public void shutdownRequested(ShutdownRequestedInput shutdownRequestedInput) {. . .}
}
- Start the Kinesis Data Streams consumer:
private static final Logger logger = Logger.getLogger(ProtobufKCLConsumer.class.getSimpleName());
private static String REGION_NAME = "us-east-2";
private static String STREAM_NAME = "employee_data_stream";
private static final String APPLICATION_NAME = "protobuf-demo-kinesis-kpl-consumer";
private static String REGISTRY_ENDPOINT = "https://glue.us-east-2.amazonaws.com";
public static void main(String[] args) throws ParseException {
new ProtobufKCLConsumer().run();
}
Enhance your protobuf schema
We covered examples of data producer and consumer applications integrating with Amazon MSK, Apache Kafka, and Kinesis Data Streams, and using a Protocol buffers schema registered with AWS Glue Schema Registry. You can further enhance these examples with schema evolution using the following rules, which are supported by AWS Glue Schema Registry. For example, the following protobuf schema shown is a backward-compatible updated version of Employee.proto. We have added another gRPC service definition CreateEmployee under EmployeeSearch and added an Optional field in the Employee message type. If you upgrade the consumer application with this version of the protobuf schema, the consumer application can still consume old and new protobuf messages.
Employee.proto (version-2)
syntax = "proto2";
package gsr.proto.post;
import "google/protobuf/wrappers.proto";
import "google/protobuf/duration.proto";
import "google/protobuf/timestamp.proto";
import "google/protobuf/empty.proto";
import "google/type/money.proto";
service EmployeeSearch {
rpc FindEmployee(EmployeeSearchParams) returns (Employee);
rpc CreateEmployee(EmployeeSearchParams) returns (google.protobuf.Empty);
}
message EmployeeSearchParams {
required int32 id = 1;
}
message Employee {
required int32 id = 1;
required string name = 2;
required string address = 3;
required google.protobuf.Int32Value employee_age = 4;
required google.protobuf.Timestamp start_date = 5;
required google.protobuf.Duration total_time_span_in_company = 6;
required google.protobuf.BoolValue is_certified = 7;
required Team team = 8;
required Project project = 9;
required Role role = 10;
required google.type.Money total_award_value = 11;
optional string title = 12;
}
message Team {
required string name = 1;
required string location = 2;
}
message Project {
required string name = 1;
required string state = 2;
}
enum Role {
MANAGER = 0;
DEVELOPER = 1;
ARCHITECT = 2;
}
Conclusion
In this post, we introduced Protocol buffers schema support in AWS Glue Schema Registry. AWS Glue Schema Registry now supports Apache Avro, JSON, and Protocol buffers schemas with different compatible modes. The examples in this post demonstrated how to use Protocol buffers schemas registered with AWS Glue Schema Registry in stream processing applications integrated with Apache Kafka, Amazon MSK, and Kinesis Data Streams. We used the schema-generated POJOs for type safety and protobuf’s DynamicMessage to create generic producer and consumer applications. The examples in this post contain the basic components of the stream processing pattern; you can adapt these examples to your use case needs.
To learn more, refer to the following resources:
About the Author
 Vikas Bajaj is a Principal Solutions Architect at AWS. Vikas works with digital native customers and advises them on technology architecture and solutions to meet strategic business objectives.
Vikas Bajaj is a Principal Solutions Architect at AWS. Vikas works with digital native customers and advises them on technology architecture and solutions to meet strategic business objectives.
Audit History
Last reviewed and updated in September 2025 by Olajide Ogunmola | Solutions Architect