AWS Big Data Blog

Keeping your data lake clean and compliant with Amazon Athena
June 2025: This post has been reviewed for accuracy and the following updates have been made: added new function to retrieve SQL query in the Lambda code; upgraded Python’s run time and version of sqlparse in the Lambda deployment package; added and removed actions in the Lambda policy; updated the CloudFormation template to reflect policy […]

Auditing, inspecting, and visualizing Amazon Athena usage and cost
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. It’s a serverless platform with no need to set up or manage infrastructure. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries. You […]

Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
November 2024: This post was reviewed and updated for accuracy. Many organizations are processing and analyzing clickstream data in real time from customer-facing applications to look for new business opportunities and identify security incidents in real time. A common practice is to consolidate and enrich logs from applications and servers in real time to proactively […]
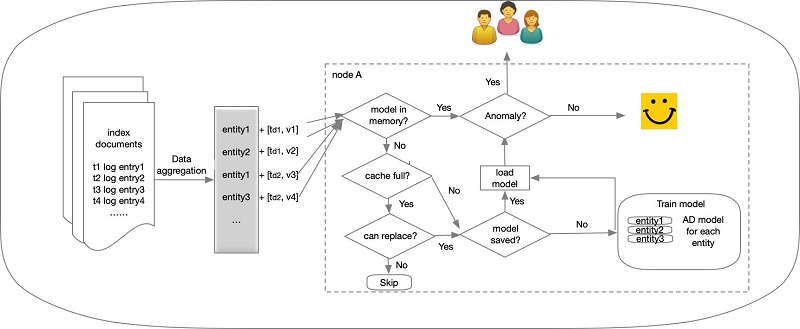
A deep dive into high-cardinality anomaly detection in Elasticsearch
In May 2020, we announced the general availability of real-time anomaly detection for Elasticsearch. With that release we leveraged the Random Cut Forest (RCF) algorithm to identify anomalous behaviors in the multi-dimensional data streams generated by Elasticsearch queries. We focused on aggregation first, to enable our users to quickly and accurately detect anomalies in their […]
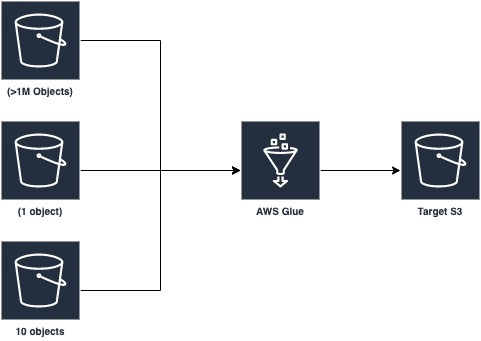
Optimizing Spark applications with workload partitioning in AWS Glue
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This posts discusses a new AWS Glue Spark runtime optimization that helps developers of Apache Spark applications and ETL jobs, big data architects, […]

Data preprocessing for machine learning on Amazon EMR made easy with AWS Glue DataBrew
The machine learning (ML) lifecycle consists of several key phases: data collection, data preparation, feature engineering, model training, model evaluation, and model deployment. The data preparation and feature engineering phases ensure an ML model is given high-quality data that is relevant to the model’s purpose. Because most raw datasets require multiple cleaning steps (such as […]

Accessing and visualizing external tables in an Apache Hive metastore with Amazon Athena and Amazon QuickSight
Many organizations have an Apache Hive metastore that stores the schemas for their data lake. You can use Amazon Athena due to its serverless nature; Athena makes it easy for anyone with SQL skills to quickly analyze large-scale datasets. You may also want to reliably query the rich datasets in the lake, with their schemas […]

Orchestrating analytics jobs by running Amazon EMR Notebooks programmatically
Amazon EMR is a big data service offered by AWS to run Apache Spark and other open-source applications on AWS in a cost-effective manner. Amazon EMR Notebooks is a managed environment based on Jupyter Notebook that allows data scientists, analysts, and developers to prepare and visualize data, collaborate with peers, build applications, and perform interactive […]

Applying row-level and column-level security on Amazon QuickSight dashboards
Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people you work with, wherever they are. QuickSight connects to your data in the cloud and combines data from many different sources. On a single data dashboard, QuickSight can include AWS data, third-party data, big data, […]
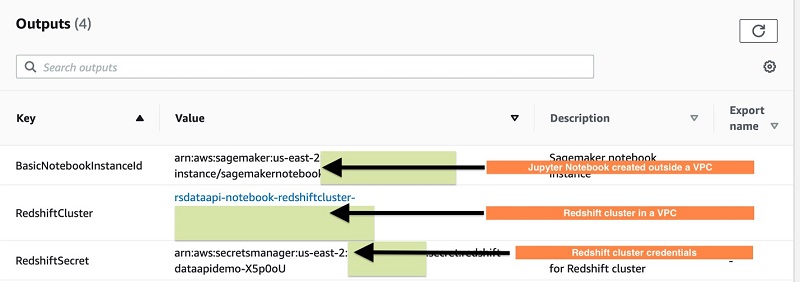
Using the Amazon Redshift Data API to interact from an Amazon SageMaker Jupyter notebook
June 2023: This post was reviewed for accuracy. The Amazon Redshift Data API makes it easy for any application written in Python, Go, Java, Node.JS, PHP, Ruby, and C++ to interact with Amazon Redshift. Traditionally, these applications use JDBC connectors to connect, send a query to run, and retrieve results from the Amazon Redshift cluster. […]