AWS Big Data Blog

Publish and update data products dynamically with AWS Data Exchange
Updated June, 2022. We’ve enhanced the “Publishing new data files to the product automatically” section of this blog post via Publisher Coordinator. Please refer to this solution when needing to automate the import of new files to an existing dataset. Data is revolutionizing the way organizations of all sizes conduct their business. Companies are increasingly […]

Find and acquire new data sets and retrieve new updates automatically using AWS Data Exchange
AWS Data Exchange makes it simple to exchange data in the cloud. In a few minutes, you can find and subscribe to hundreds of data products from more than 80 qualified data providers across industries such as Financial Services, Healthcare and Life Sciences, and Consumer and Retail. After subscribing, you can download data sets or copy them to Amazon S3 and analyze them with AWS’s analytics and machine learning services. With AWS Data Exchange, you can subscribe to data products and get access to data sets. Subscribers also access new data set revisions as providers publish new data.

Enhancing dashboard interactivity with Amazon QuickSight Actions
Amazon QuickSight now offers enhanced dashboard interactivity capabilities through QuickSight Actions. QuickSight Actions provide advanced filtering capabilities through single point-and-click actions on dashboards. With Actions, you can link visuals within a dashboard so that selecting a dimensional point on one visual provides you with granular insights on the selected point on other visuals within your dashboard. Therefore, you can start with summaries and dive deep into details of your business metrics, all within the same dashboard sheet. You can define what visuals within your dashboard are interactive and how these interact with each other. As of this writing, QuickSight Actions lets you define two primary actions of interactivity: filter actions and URL actions. URL actions within Amazon QuickSight are not new, but the point of entry to create URL actions is now consolidated with Actions.
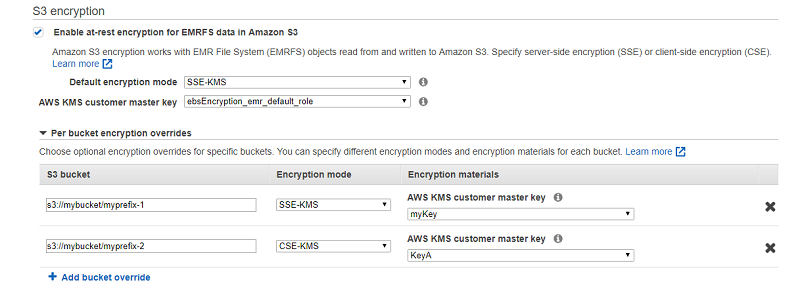
Secure your data on Amazon EMR using native EBS and per bucket S3 encryption options
This post provides a detailed walkthrough of two new encryption options to help you secure your EMR cluster that handles sensitive data. The first option is native EBS encryption to encrypt volumes attached to EMR clusters. The second option is an Amazon S3 encryption that allows you to use different encryption modes and customer master keys (CMKs) for individual S3 buckets with Amazon EMR.

Amazon QuickSight announces the all-new QuickSight Mobile app
AWS is happy to announce the release of QuickSight Mobile for iOS and Android devices. This release is both a major update to the existing iOS app and the launch of a new Android application. The app enables you to securely get insights from your data from anywhere; favorite, browse, and interact with your dashboards; […]

Joining across data sources on Amazon QuickSight
June 2025: This post was reviewed and updated for accuracy. Amazon QuickSight allows you to connect to multiple data sources and join data across these sources in Amazon QuickSight directly to create datasets used to build dashboards. For example, you can join transactional data in Amazon Redshift that contains customer IDs with Salesforce tables that contain […]

Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 2
In Part 1 of this post series, you learned how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. This post guides you through deploying the AWS CloudFormation templates, configuring Genie, and running an example workflow authored in Apache Airflow.
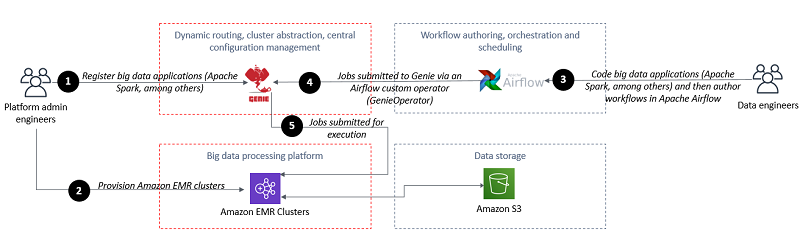
Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 1
This post introduces an architecture that helps centralized platform teams maintain a big data platform to service thousands of concurrent ETL workflows, and simplifies the operational tasks required to accomplish that.

Access and manage data from multiple accounts from a central AWS Lake Formation account
his post shows how to access and manage data in multiple accounts from a central AWS Lake Formation account. The walkthrough demonstrates a centralized catalog residing in the master Lake Formation account, with data residing in the different accounts. The post shows how to grant access permissions from the Lake Formation service to read, write and update the catalog and access data in different accounts.

How ironSource built a multi-purpose data lake with Upsolver, Amazon S3, and Amazon Athena
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. This is a guest post co-written by Seva Feldman at ironSource Mobile and Eran Levy at Upsolver. ironSource, in their own words, is the leading in-app monetization and video advertising platform, making free-to-play and free-to-use possible for over 1.5B people around […]