AWS Big Data Blog
Joining across data sources on Amazon QuickSight
June 2025: This post was reviewed and updated for accuracy.
Amazon QuickSight allows you to connect to multiple data sources and join data across these sources in Amazon QuickSight directly to create datasets used to build dashboards. For example, you can join transactional data in Amazon Redshift that contains customer IDs with Salesforce tables that contain customer profile data to create an interactive dashboard with order and customer details. You can slice and dice transactional data by various customer dimensional data such as segment, geographic, or demographic without first pulling the data to a single source outside Amazon QuickSight.
With cross data source joins, you can join across all data sources supported by Amazon QuickSight, including file-to-file, file-to-database, and database-to-database joins using the built-in drag-and-drop UI, without heavily relying on the BI and data engineering teams to set up complex and time-consuming ETLs. Whether it is local CSV files, Amazon RDS databases, or JSON objects on an Amazon S3 bucket, you can now join any of these data sources together to create data sets.
Finally, you can also refresh or set up a scheduled refresh and confirm that the joined data set is always up to date with the latest information.
Getting started with Cross Data Source Join
The screenshot below shows all data sources you can connect to on QuickSight.
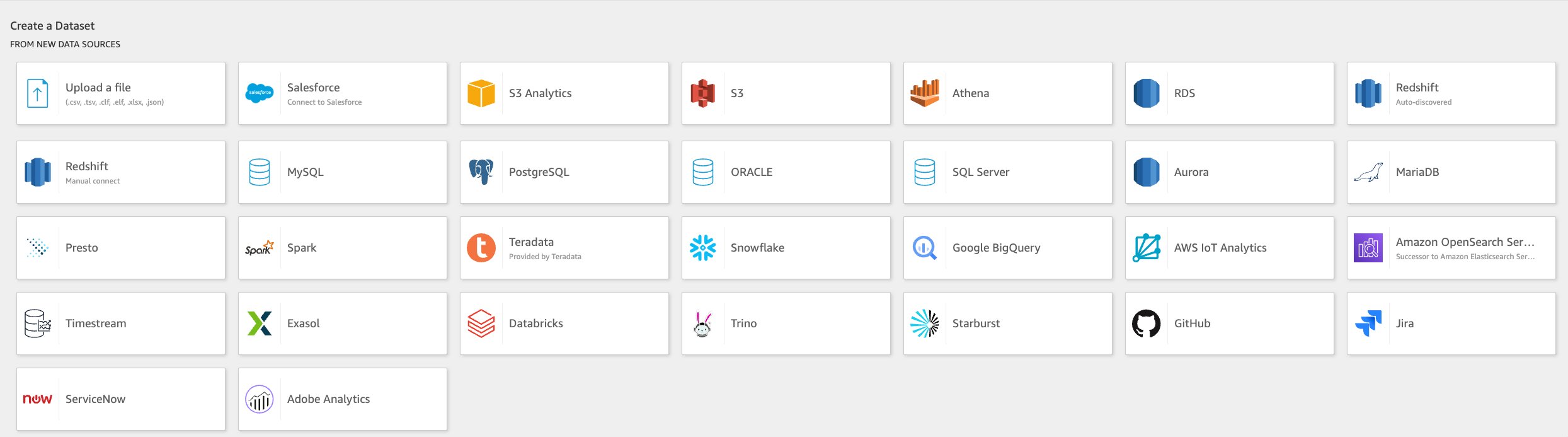
Amazon QuickSight allows you to connect to different data sources. It is common for businesses to have data spread across multiple data sources, depending on your data requirements. For example, you might have your web server logs stored in Amazon S3, customer details on Amazon Redshift tables, and order details on RDS. You may need to build reports from data combined from two or more of these different data sources.
You can accomplish this to some extent by building data pipelines to consolidate from multiple data sources into one single data source. However, creating these data pipelines results in data duplications across various AWS services, and adds additional cost in terms of effort and time to move data to a single data source. You would then build Amazon QuickSight data sets from this single data source. With cross data source join available directly on Amazon QuickSight, you can eliminate this problem.
There is no size restriction on your largest source, as long as the post-join table can fit into your SPICE capacity per data set. The rest of the tables together need to be within 1 GB in size. For example, if you have 20 numeric columns in your smaller table, you can fit about 5 million rows until you exceed the 1 GB memory limit.
This post demonstrates how to create data sets from two CSV files and how to join an RDS table with an S3 file. The post uses an example table with orders-related data in one data source, and returns-related data in another data source. The final goal is to create one single data set that contains both orders and returns data.
Prerequisites
Before getting started, download these CSV files in to your local machines:
- Orders table
- Returns table
- Download the JSON file for returns and upload to your own S3 bucket.
Also, learn how to create, edit, delete QuickSight data sources from Working with Data Sources in Amazon QuickSight.
Joining multiple CSV files
To join two CSV files, complete the following steps:
- Use the orders CSV file downloaded from the S3 bucket above and upload to QuickSight.
- After selecting the ‘orders’ sheet, go to edit/preview data page where your data set details appears.
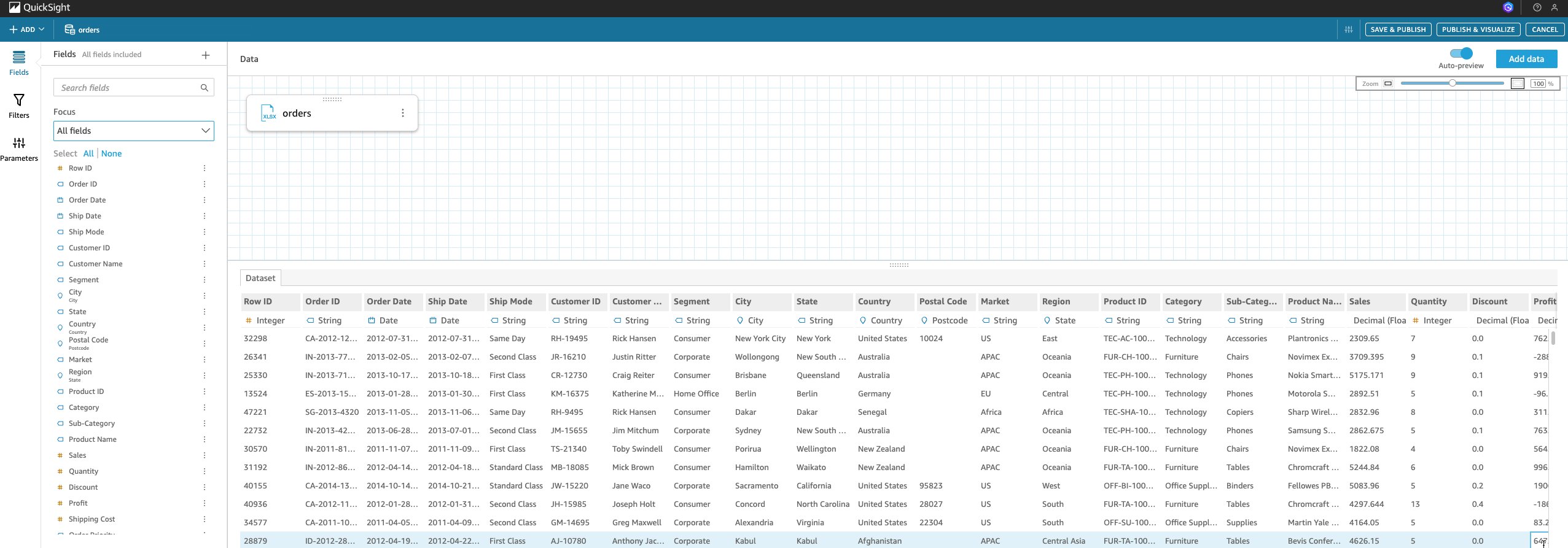
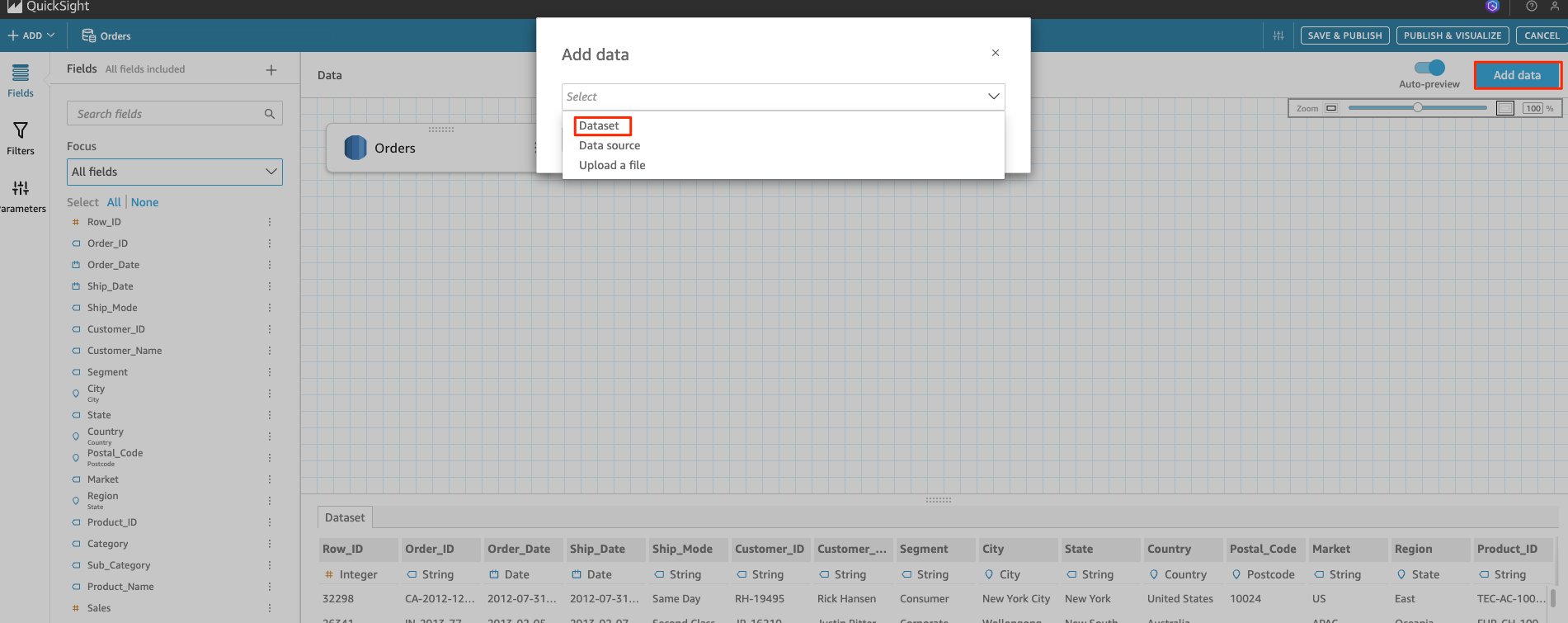
- From the top menu, choose Add data. A pop-up window appears with the option to either switch data sources or upload a new CSV to join with the current data set. The window also shown has existing source.
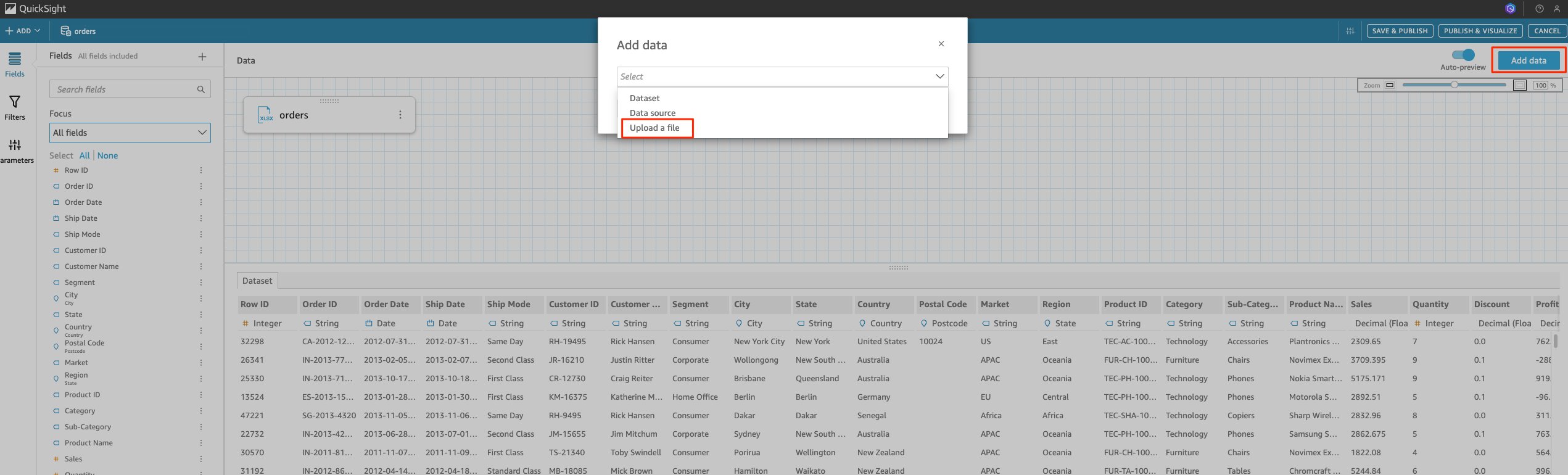
- Choose Upload a file and upload the ‘returns’ CSV file.After uploading the file, you can see sheet names for both the CSVs. The following screenshot shows
ordersandreturns.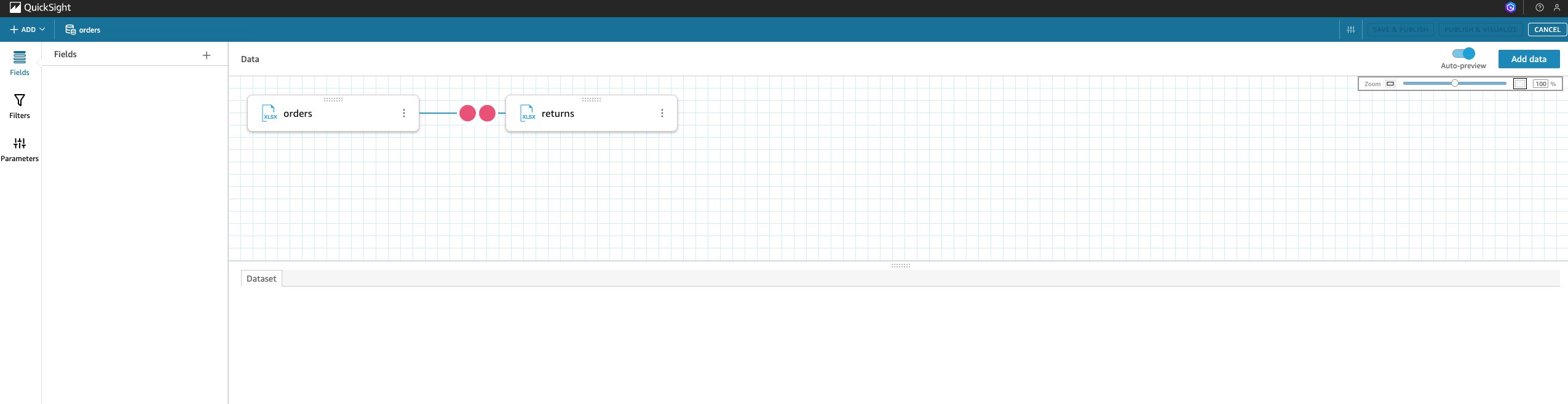
- Choose the two circles between the files.This step allows you to edit the join configuration between the two CSVs. In the Join configuration section, you can select the join type (inner, left, right, or full) and also select the column on which to apply the join. This post uses an inner join.
- For Join type, choose Inner. This post is joining the order ID classes of the two files.
- For Join classes, select Order ID in both drop-downs.
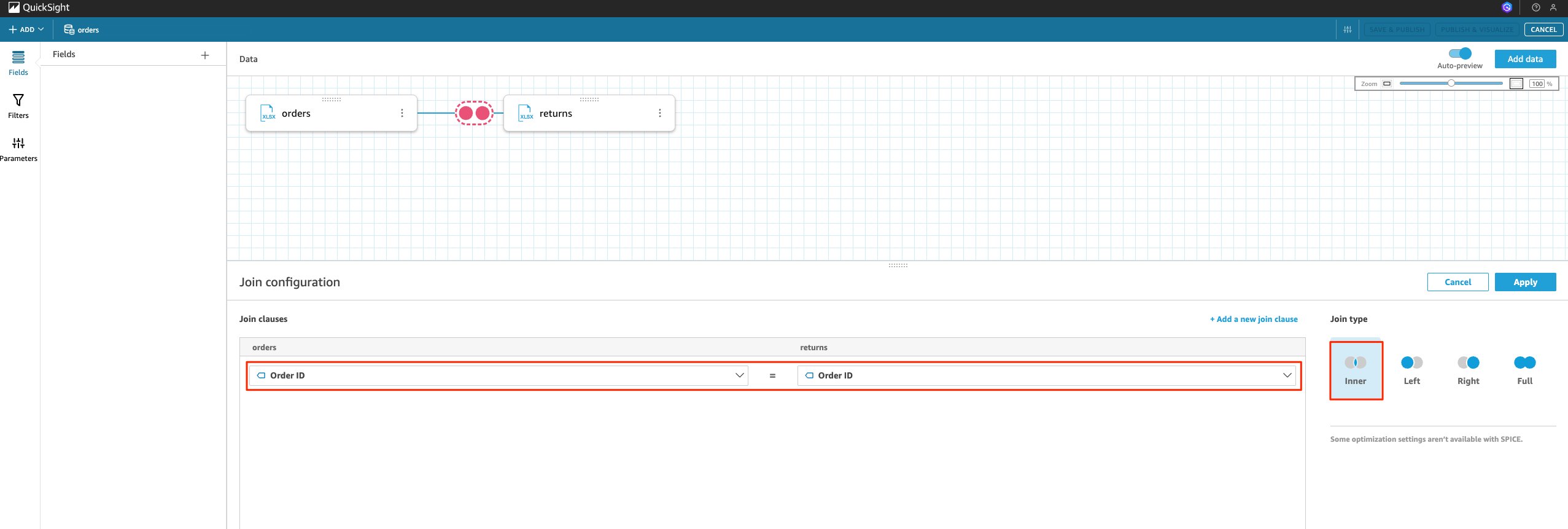
- Choose Apply, You now have a data set that contains both orders and returns data from two different CSVs. You can name the dataset accordingly, save it and continue to create your analysis.
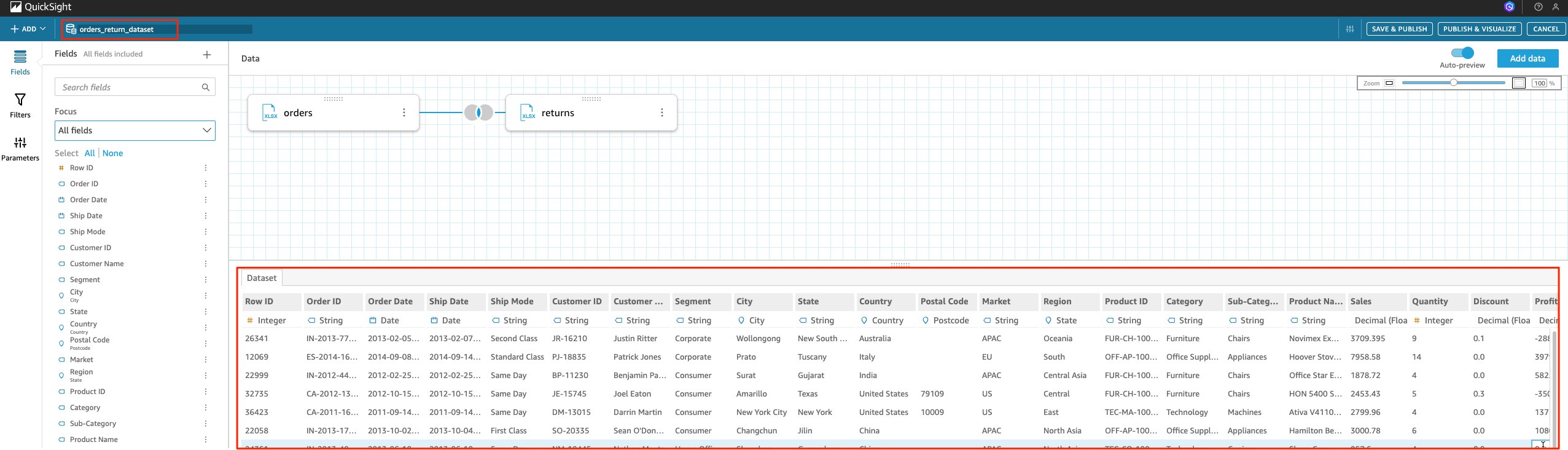
Joining an RDS table with S3
In this example, you have orders data in RDS and returns data as a JSON file in an S3 bucket. To join this data, complete the following steps:
- Create a data set on QuickSight from the RDS table. Review Create a Database Data Set and an Analysis to learn to connect to RDS to create data sets. See RDS Authorization and access for more details.
- Next, Click Datasets, select the RDS data set. This post uses the
ordersdata set.
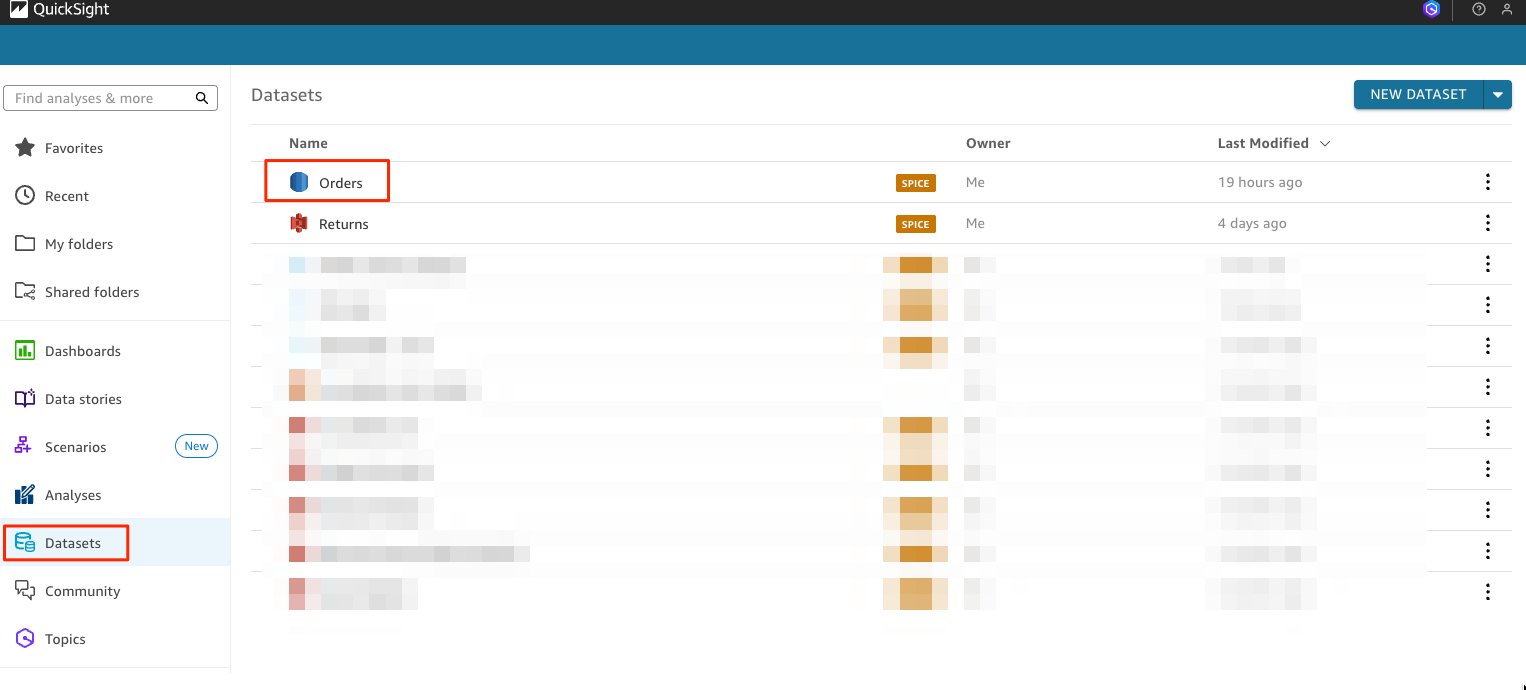
- Choose Edit data set. A page with your data set details appears.
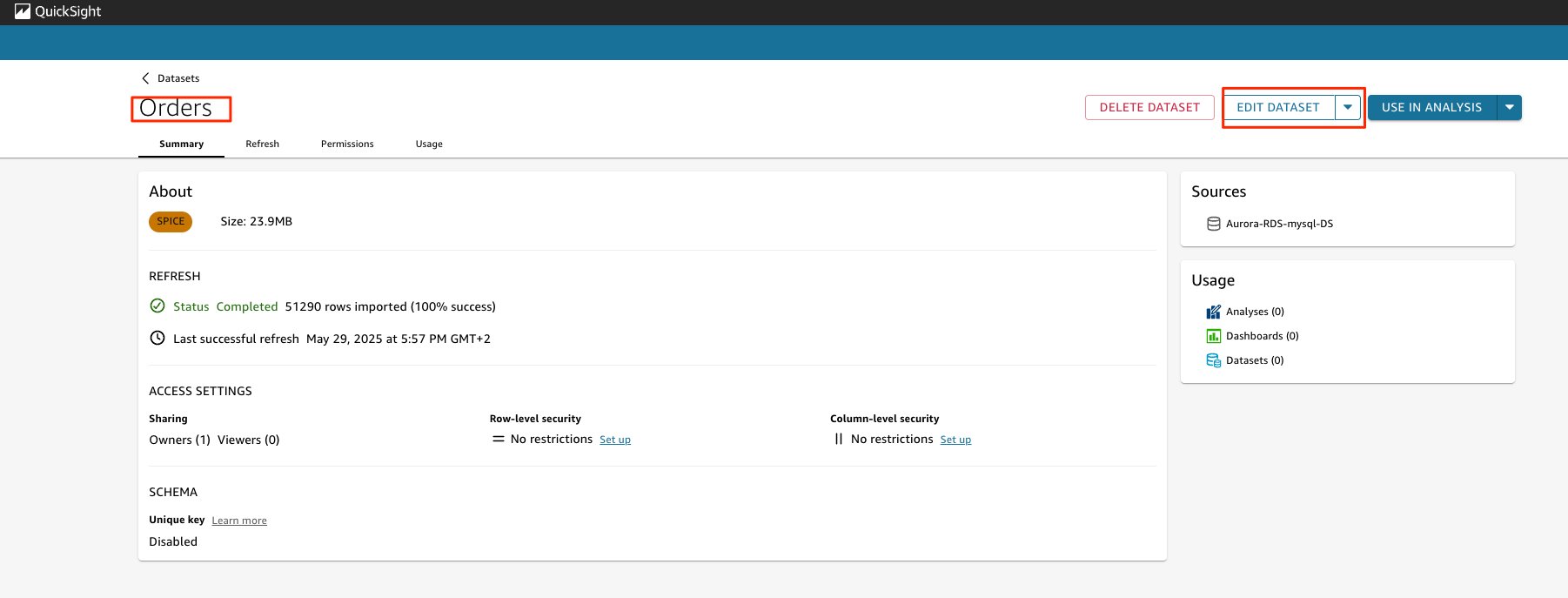
- Click Add data. A pop-up window appears with the drop down option to either add data from Dataset, Data source or Upload a file.
- Dataset selection will let you select all the available dataset you have access in the QuickSight account
- Datasource lets you select all dataset you have access to or also add additional tables from the same dataset.
- Upload a file lets you add flat files. See Importing file data on formats supported.
- Choose Data source. A list appears of the different data sets and their sources.
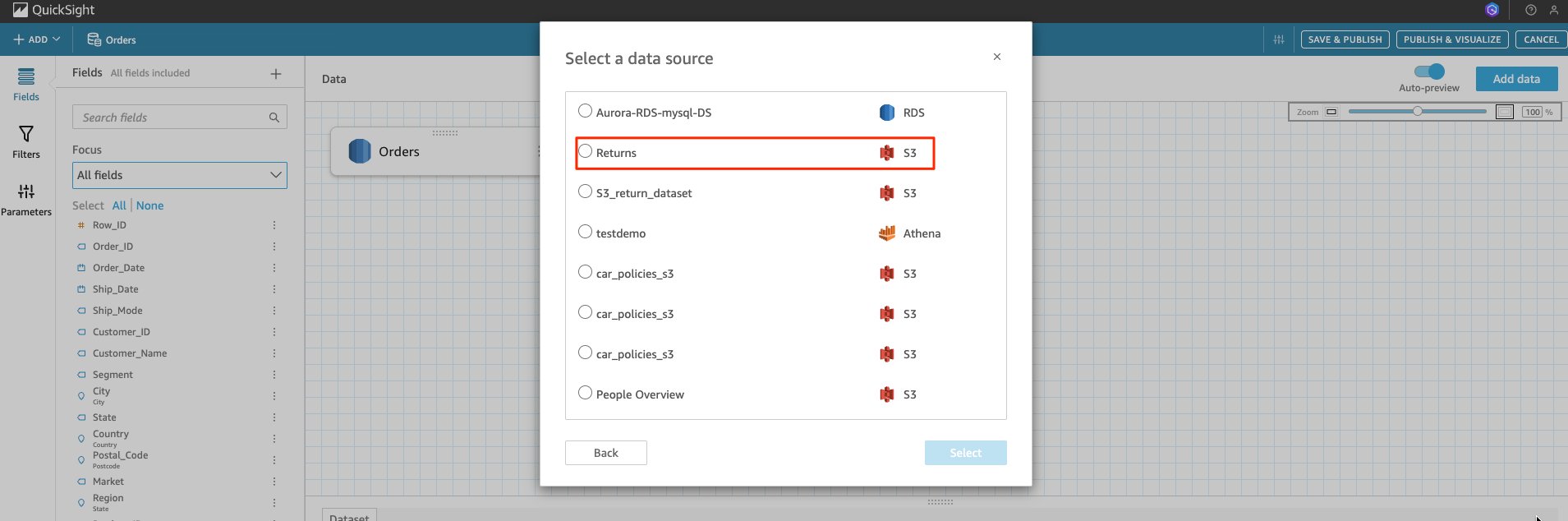
- For this post choose
Returnsand its Table. You can now see both data sets linked together.
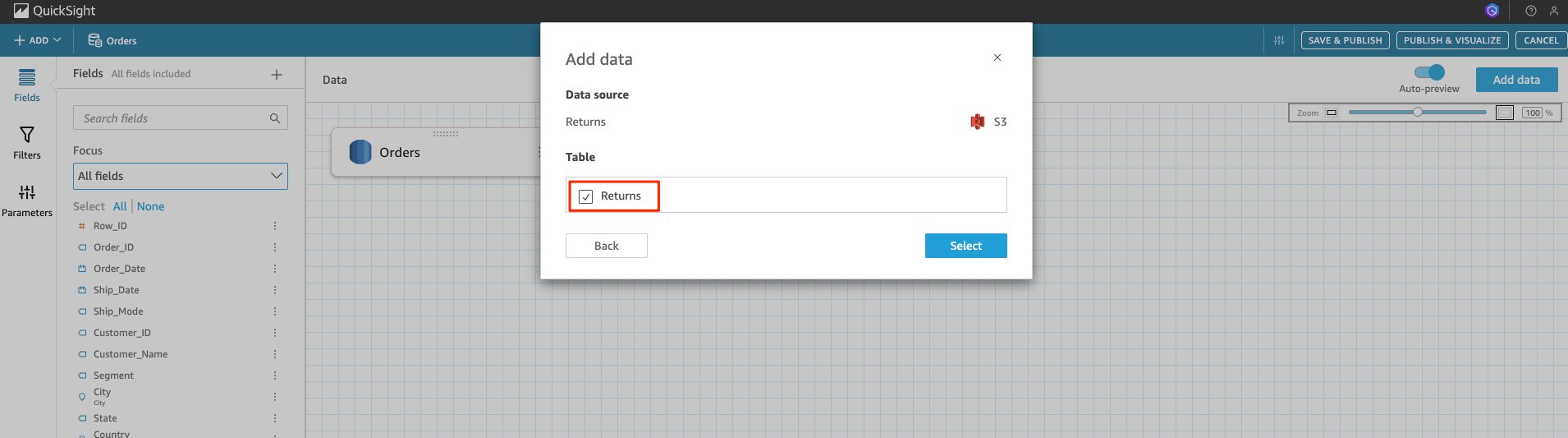
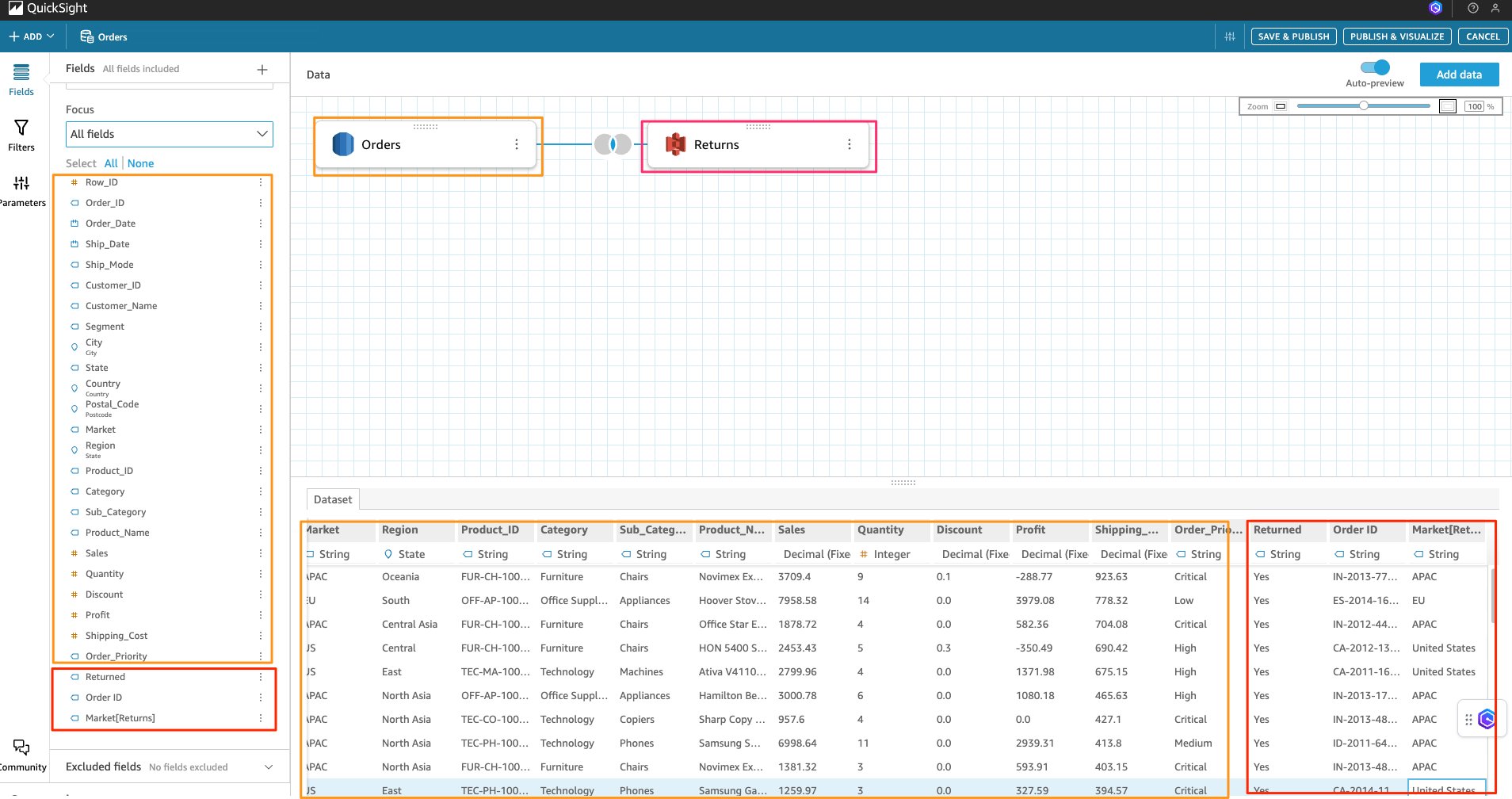
- Choose the two spheres between the data sets.
- Under Join configuration, choose your desired Join type. This post chooses Inner.
- For Join clauses, from the drop-downs of each data set, select the column on which to apply the join. This post chooses
order_idfor orders andOrder IDforReturns.
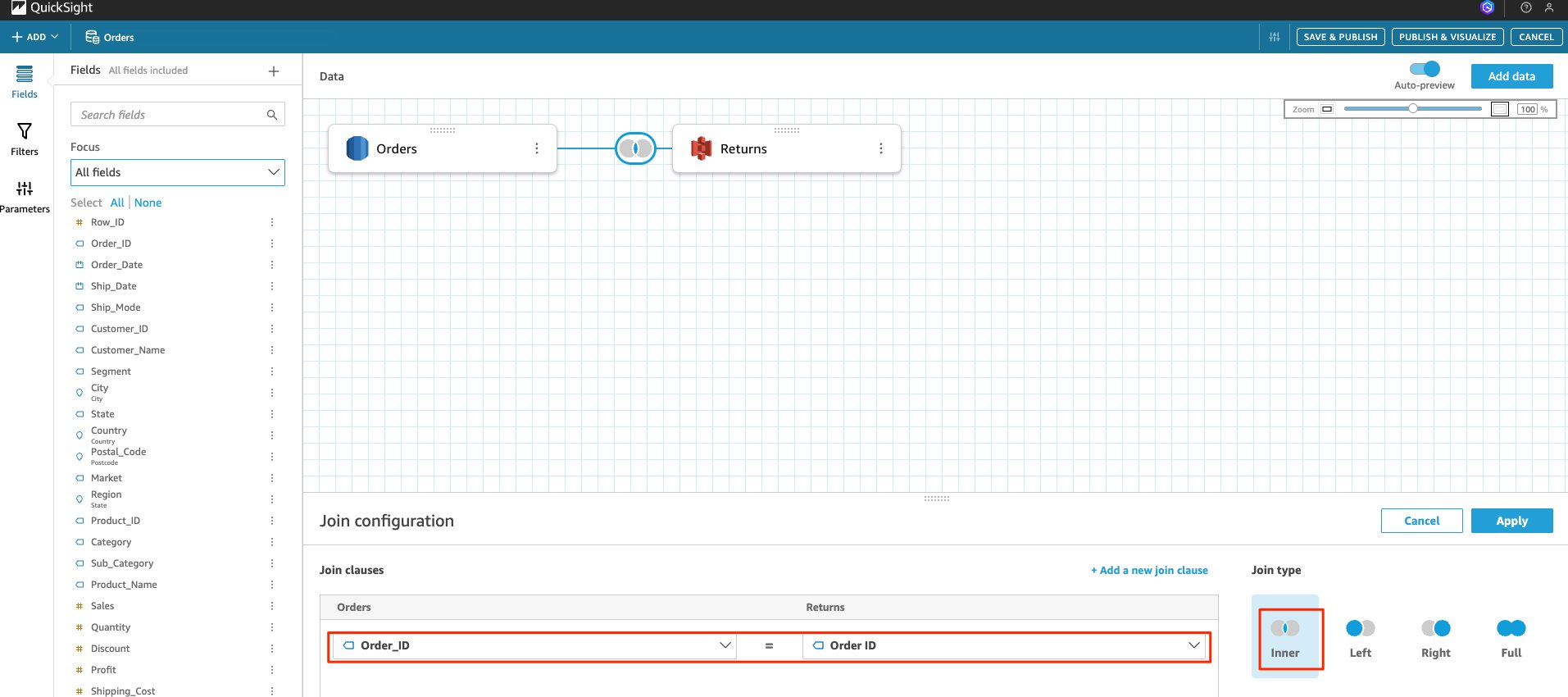
- Choose Apply.
Your new data set contains both orders and returns data from two different CSVs. You can save your data set, provide an appropriate name for the joined dataset and continue to create your analysis.
Conclusion
This post showed you how to join data from two files in CSV, and join tables from RDS and S3. You can join data from any two data sources on Amazon QuickSight with this method. Please see facts and consideration while considering joining data in QuickSight.
About the authors
 Rakshith Dayananda is an IT app dev engineer at AWS.
Rakshith Dayananda is an IT app dev engineer at AWS.
 Deepak Sahi is a Solutions Architect at AWS based out of Zurich, Switzerland. He has close to two decades of experience in the field of Data Analytics, primarily in Business intelligence and data warehousing. He has worked worldwide as a consultant in domains such as Telcom, Finance, Insurance, Healthcare etc. for many Fortune 500 Companies. He is currently focusing on manufacturing companies in Switzerland at the same time he is a member of SME for Amazon QuickSight. He helps them build secure and innovative cloud solutions, enable data-driven decisions and solve their business challenges.
Deepak Sahi is a Solutions Architect at AWS based out of Zurich, Switzerland. He has close to two decades of experience in the field of Data Analytics, primarily in Business intelligence and data warehousing. He has worked worldwide as a consultant in domains such as Telcom, Finance, Insurance, Healthcare etc. for many Fortune 500 Companies. He is currently focusing on manufacturing companies in Switzerland at the same time he is a member of SME for Amazon QuickSight. He helps them build secure and innovative cloud solutions, enable data-driven decisions and solve their business challenges.