AWS Big Data Blog

Meet the Amazon EMR Team this Friday at a Tech Talk & Networking Event in Mountain View
Want to change the world with Big Data and Analytics? Come join us on the Amazon EMR team in Amazon Web Services! Meet the Amazon EMR team this Friday April 7th from 5:00 – 7:30 PM at Michael’s at Shoreline in Mountain View. We’ll feature short tech talks by EMR leadership who will talk about the past, […]
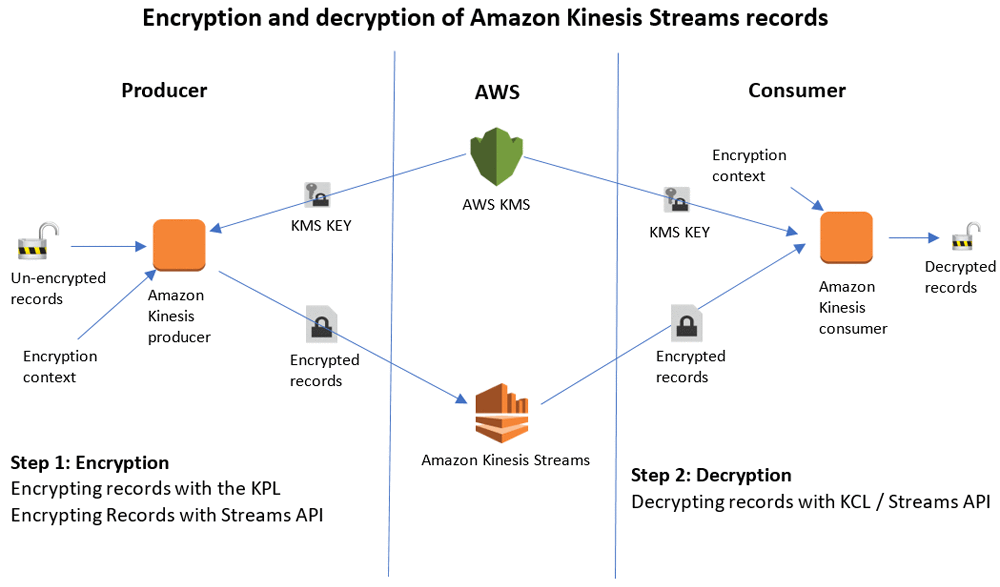
Encrypt and Decrypt Amazon Kinesis Records Using AWS KMS
Customers with strict compliance or data security requirements often require data to be encrypted at all times, including at rest or in transit within the AWS cloud. This post shows you how to build a real-time streaming application using Kinesis in which your records are encrypted while at rest or in transit. Amazon Kinesis overview […]

Big Data Resources on the AWS Knowledge Center
The AWS Knowledge Center answers the questions we receive most frequently from AWS customers. It is a resource for you that is distinct from AWS Documentation, the AWS Discussion Forums, and the AWS Support Center. It covers questions from across every AWS service. Specific big data services covered on the Knowledge Center include Amazon EMR, Amazon Athena, […]

Top 10 Performance Tuning Tips for Amazon Athena
February 2024: This post was reviewed and updated to reflect changes in Amazon Athena engine version 3, including cost-based optimization and query result reuse. Amazon Athena is an interactive analytics service built on open source frameworks that make it straightforward to analyze data stored using open table and file formats in Amazon Simple Storage Service […]
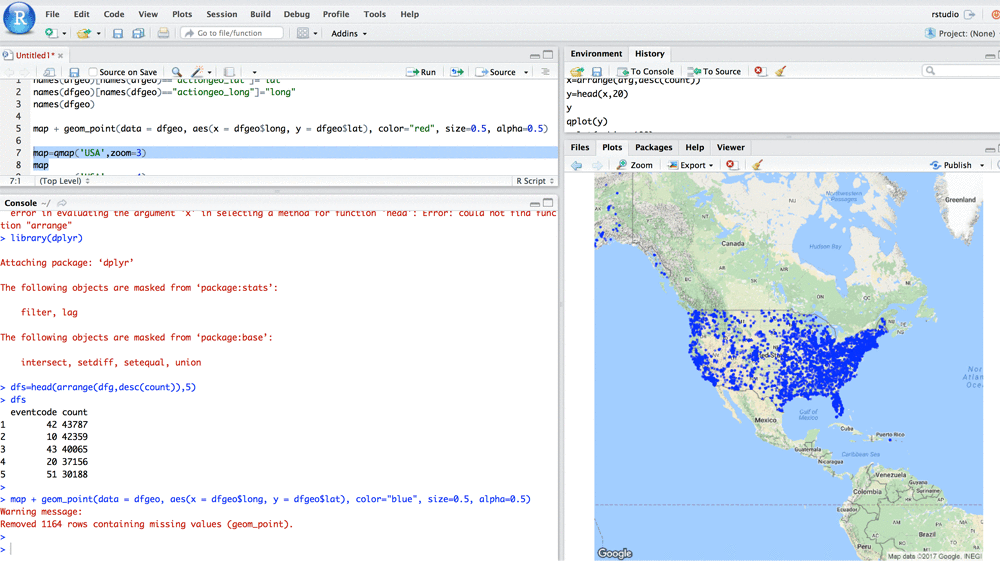
Running R on Amazon Athena
This blog post has been translated into Japanese. Data scientists are often concerned about managing the infrastructure behind big data platforms while running SQL on R. Amazon Athena is an interactive query service that works directly with data stored in S3 and makes it easy to analyze data using standard SQL without the need to […]

Amazon Redshift Monitoring Now Supports End User Queries and Canaries
Ian Meyers is a Solutions Architecture Senior Manager with AWS The serverless Amazon Redshift Monitoring utility lets you gather important performance metrics from your Redshift cluster’s system tables and persists the results in Amazon CloudWatch. This serverless solution leverages AWS Lambda to schedule custom SQL queries and process the results. With this utility, you can use […]

Month in Review: February 2017
Another month of big data solutions on the Big Data Blog! Take a look at our summaries below and learn, comment, and share. Thank you for reading! NEW POSTS Implement Serverless Log Analytics Using Amazon Kinesis Analytics In this post, learn how how to implement a solution that analyzes streaming Apache access log data from an […]

Join us next week at Strata + Hadoop World in San Jose, CA
We’re back in San Jose for the Strata conference, March 13-16, 2017, to talk all things big data at AWS and show you some of our latest innovations. Come meet the AWS Big Data team at booth #928, where big data experts will be happy to answer your questions, hear about your requirements, and help […]
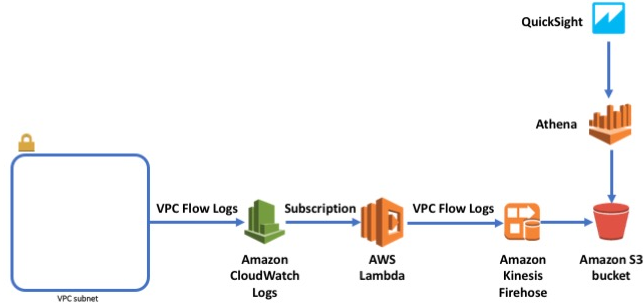
Analyzing VPC Flow Logs using Amazon Athena, and Amazon QuickSight
February 2, 2022: Blog updated by Chaitanya Shah. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Organizations of different size who migrate their applications in cloud or applications born in cloud makes use of various cloud services to innovate and […]

Big Updates to the Big Data on AWS Training Course!
AWS offers a range of training resources to help you advance your knowledge with practical skills so you can get more out of the cloud. We’ve updated Big Data on AWS, a three-day, instructor-led training course to keep pace with the latest AWS big data innovations. This course allows you to hear big data best […]