AWS Big Data Blog

Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).

Viewing Amazon OpenSearch Service Error Logs
Today, Amazon OpenSearch Service announces support for publishing error logs to Amazon CloudWatch Logs. This new feature provides you with the ability to capture error logs so you can access information about errors and warnings raised during the operation of the service. These details can be useful for troubleshooting. You can then use this information […]
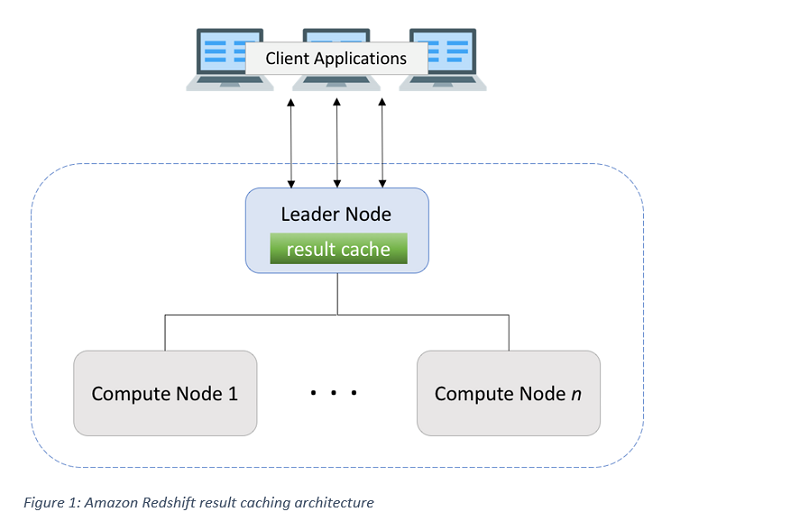
Get sub-second query response times with Amazon Redshift result caching
In this post, we take a look at query result caching in Amazon Redshift. Result caching does exactly what its name implies—it caches the results of a query.

Build a Concurrent Data Orchestration Pipeline Using Amazon EMR and Apache Livy
In this post, we explore orchestrating a Spark data pipeline on Amazon EMR using Apache Livy and Apache Airflow, we create a simple Airflow DAG to demonstrate how to run spark jobs concurrently, and we see how Livy helps to hide the complexity to submit spark jobs via REST by using optimal EMR resources.
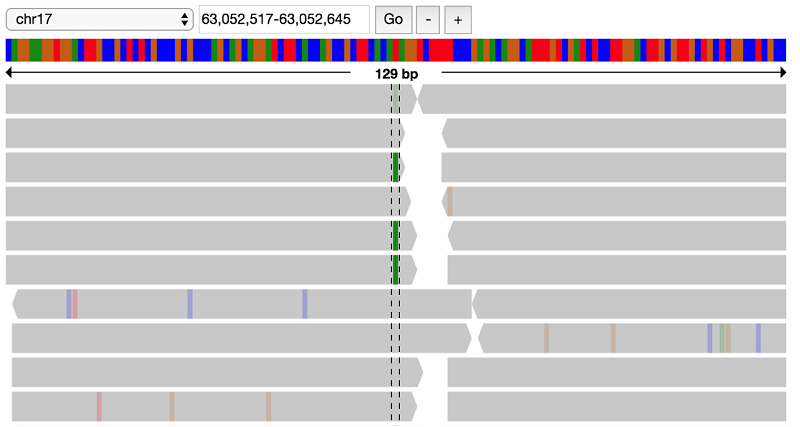
Exploratory data analysis of genomic datasets using ADAM and Mango with Apache Spark on Amazon EMR
In this post, we describe how to set up and run ADAM and Mango on Amazon EMR. We demonstrate how you can use these tools in an interactive notebook environment to explore the 1000 Genomes dataset, which is publicly available in Amazon S3 as a public dataset.

How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena
In this post, we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB.

Get started with Amazon OpenSearch Service: T-shirt-size your domain
Welcome to this introductory series on Amazon OpenSearch Service. In this and future blog posts, we provide the basic information that you need to get started with Amazon OpenSearch Service. Introduction When you’re spinning up your first Amazon OpenSearch Service domain, you need to configure the instance types and count, decide whether to use dedicated […]

Encrypt data in transit using a TLS custom certificate provider with Amazon EMR
Many enterprises have highly regulated policies around cloud security. Those policies might be even more restrictive for Amazon EMR where sensitive data is processed. EMR provides security configurations that allow you to set up encryption for data at rest stored on Amazon S3 and local Amazon EBS volumes. It also allows the setup of Transport […]
Best practices for resizing and automatic scaling in Amazon EMR
In this post, I detail how EMR clusters resize, and I present some best practices for getting the maximum benefit and resulting cost savings for your own cluster through this feature.

Orchestrate multiple ETL jobs using AWS Step Functions and AWS Lambda
In this post, I show you how to use AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs involving a diverse set of technologies in an arbitrarily-complex ETL workflow.