AWS Big Data Blog
Category: Developer Tools
Managing Amazon OpenSearch UI infrastructure as code with AWS CDK
As organizations scale their observability and analytics capabilities across multiple AWS Regions and environments, maintaining consistent dashboards becomes increasingly complex. Teams often spend hours manually recreating dashboards, creating workspaces, linking data sources, and validating configurations across deployments—a repetitive and error-prone process that slows down operational visibility. The next generation OpenSearch UI in Amazon OpenSearch Service […]

Streamline Spark application development on Amazon EMR with the Data Solutions Framework on AWS
In this post, we explore how to use Amazon EMR, the AWS Cloud Development Kit (AWS CDK), and the Data Solutions Framework (DSF) on AWS to streamline the development process, from setting up a local development environment to deploying serverless Spark infrastructure, and implementing a CI/CD pipeline for automated testing and deployment.

Streamline your data governance by deploying Amazon DataZone with the AWS CDK
Managing data across diverse environments can be a complex and daunting task. Amazon DataZone simplifies this so you can catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. Many organizations manage vast amounts of data assets owned by various teams, creating a complex landscape that poses challenges for scalable data […]

How Swisscom automated Amazon Redshift as part of their One Data Platform solution using AWS CDK – Part 2
In this series, we talk about Swisscom’s journey of automating Amazon Redshift provisioning as part of the Swisscom One Data Platform (ODP) solution using the AWS Cloud Development Kit (AWS CDK), and we provide code snippets and the other useful references. In Part 1, we did a deep dive on provisioning a secure and compliant […]

How Swisscom automated Amazon Redshift as part of their One Data Platform solution using AWS CDK – Part 1
In this post, we deep dive into provisioning a secure and compliant Redshift cluster using the AWS CDK and discuss the best practices of secret rotation. We also explain how Swisscom used AWS CDK custom resources in automating the creation of dynamic user groups that are relevant for the AWS Identity and Access management (IAM) roles matching different job functions.

How Huron built an Amazon QuickSight Asset Catalogue with AWS CDK Based Deployment Pipeline
This is a guest blog post co-written with Corey Johnson from Huron. Having an accurate and up-to-date inventory of all technical assets helps an organization ensure it can keep track of all its resources with metadata information such as their assigned owners, last updated date, used by whom, how frequently, and more. It helps engineers, […]

Automate deployment and version updates for Amazon Kinesis Data Analytics applications with AWS CodePipeline
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics is the easiest way to transform and analyze streaming data in real time using Apache Flink. Customers are already using Kinesis Data Analytics […]

Automate Amazon Redshift Serverless data warehouse management using AWS CloudFormation and the AWS CLI
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage the instance type, instance size, lifecycle management, pausing, resuming, and so on. It automatically provisions and intelligently scales data warehouse compute capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what […]

Build, Test and Deploy ETL solutions using AWS Glue and AWS CDK based CI/CD pipelines
April 2025: After careful consideration, we have made the decision to close new customer access to AWS CodeCommit, effective July 25, 2024. AWS CodeCommit existing customers can continue to use the service as normal. AWS continues to invest in security, availability, and performance improvements for AWS CodeCommit, but we do not plan to introduce new […]
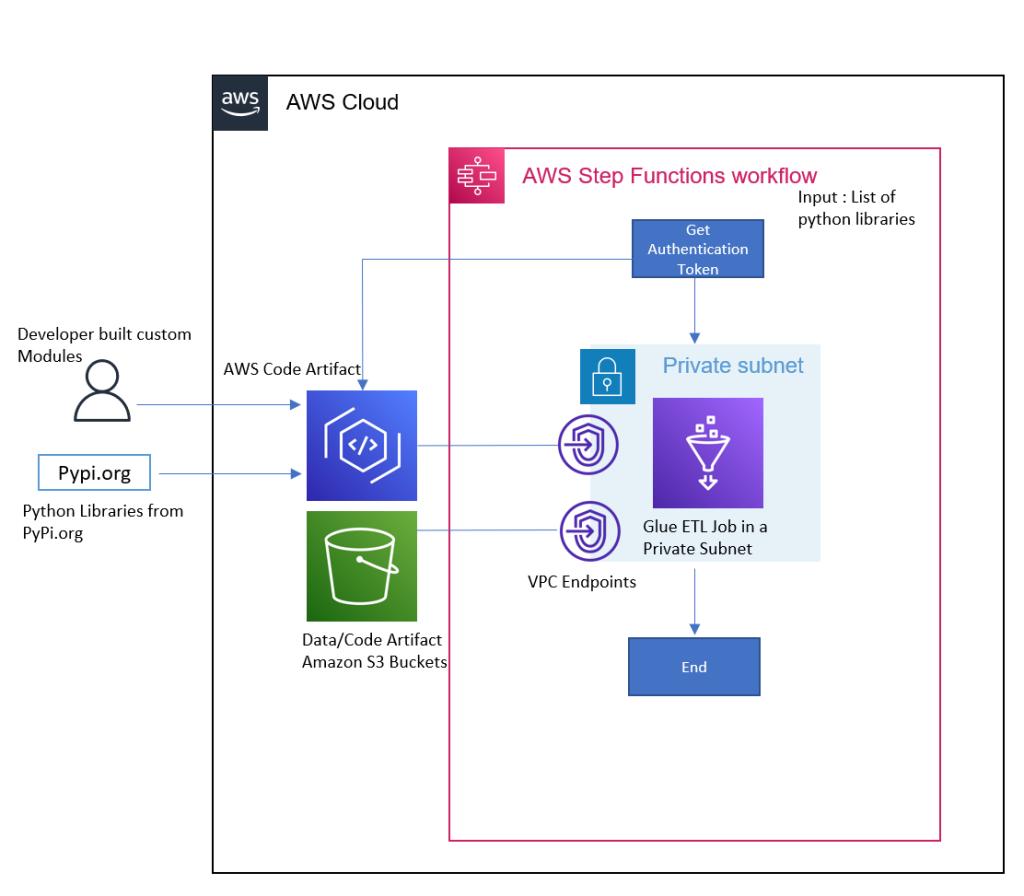
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]