AWS Big Data Blog

Analyze and visualize your VPC network traffic using Amazon Kinesis and Amazon Athena
In this blog post, we describe the complete solution for collecting, analyzing, and visualizing VPC flow log data. In addition, we created a single AWS CloudFormation template that lets you efficiently deploy this solution into your own account.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

Narrativ is helping producers monetize their digital content with Amazon Redshift
Narrativ, in their own words: Narrativ is building monetization technology for the next generation of digital content producers. Our product portfolio includes a real-time bidding platform and visual storytelling tools that together generate millions of dollars of advertiser value and billions of data points each month. At Narrativ, we have seen massive growth in our […]
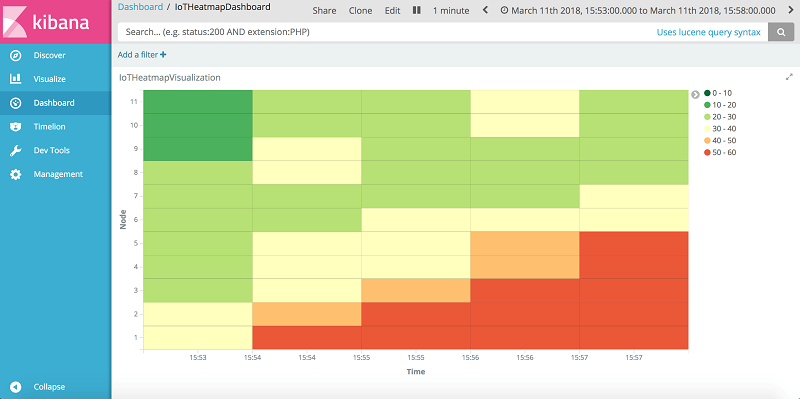
Real-time bushfire alerting with Complex Event Processing in Apache Flink on Amazon EMR and IoT sensor network
In this blog post, we discuss how to build a real-time IoT stream processing, visualization, and alerting pipeline using various AWS services. We took advantage of the Complex Event Processing feature provided by Apache Flink to detect patterns within a network from the incoming events.

Using QuickSight parameters and controls to drive interactivity in your dashboards
Amazon QuickSight added support for parameters, on-screen controls, and URL actions earlier this year. In this blog post, we walk through several examples to show how you can use these capabilities within interactive dashboards for your audience.
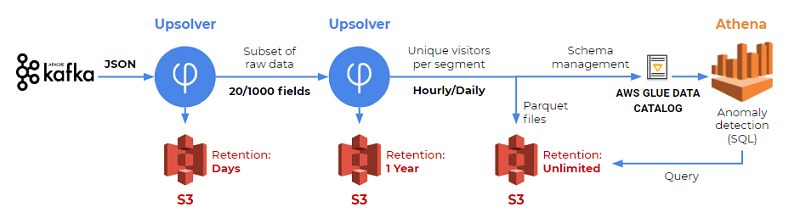
How SimilarWeb analyze hundreds of terabytes of data every month with Amazon Athena and Upsolver
This is a guest post by Yossi Wasserman, a data collection & innovation team leader at Similar Web. SimilarWeb, in their own words: SimilarWeb is the pioneer of market intelligence and the standard for understanding the digital world. SimilarWeb provides granular insights about any website or mobile app across all industries in every region. SimilarWeb […]
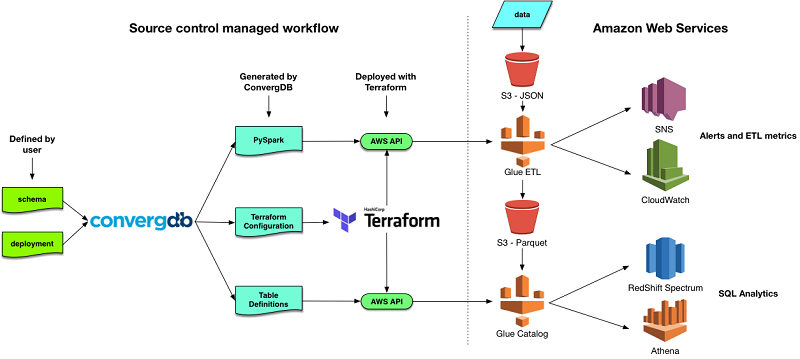
How Pagely implemented a serverless data lake in AWS to facilitate customer support analytics
In this post, we discuss how Pagely worked with Beyondsoft, an AWS Advanced Consulting Partner, to use ConvergDB, an open-source tool developed by Beyondsoft, to build a DevOps-centric data pipeline. This pipeline uses AWS Glue to transform application logs into optimized tables that can be queried quickly and cost effectively using Amazon Athena.
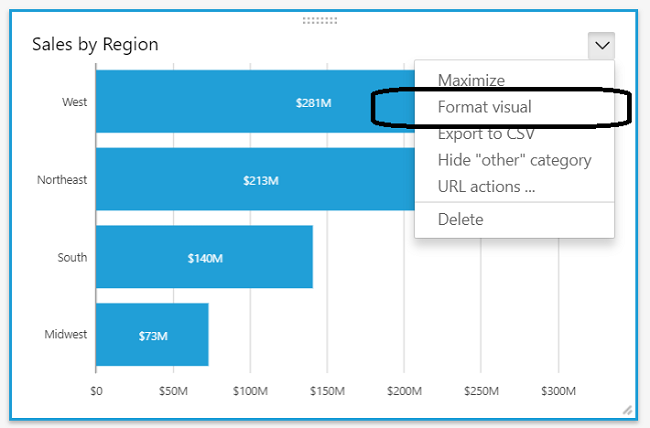
Amazon QuickSight now supports Email Reports and Data Labels
Today, we are excited to announce the availability of email reports and data labels in Amazon QuickSight. Email reports With email reports in Amazon QuickSight, you can receive scheduled and one-off reports delivered directly to your email inbox. Using email reports, you have access to the latest information without logging in to your Amazon QuickSight […]
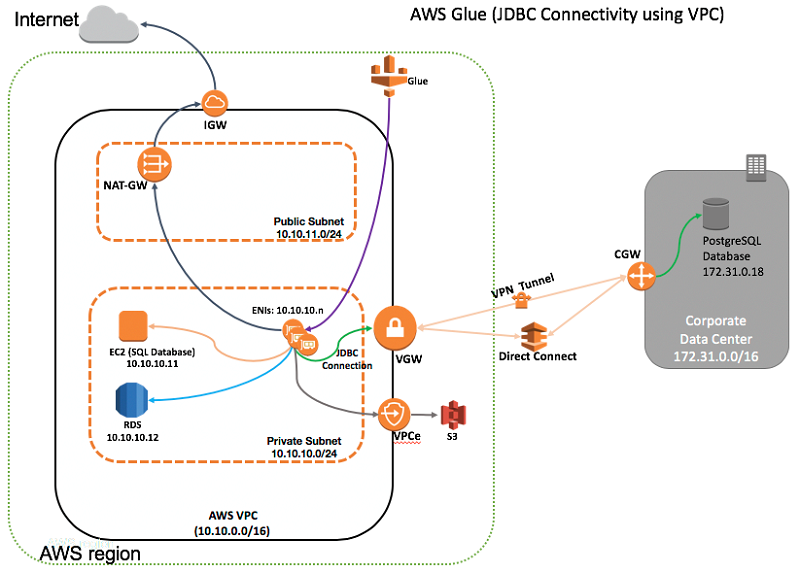
How to access and analyze on-premises data stores using AWS Glue
This post demonstrates how to set up AWS Glue in a hybrid environment. While using AWS Glue as a managed ETL service in the cloud, you can use existing connectivity between your VPC and data centers to reach an existing database service without significant migration effort. This provides you with an immediate benefit.