AWS Big Data Blog
How to access and analyze on-premises data stores using AWS Glue
May 2022: This post was reviewed for accuracy.
AWS Glue is a fully managed ETL (extract, transform, and load) service to catalog your data, clean it, enrich it, and move it reliably between various data stores. AWS Glue ETL jobs can interact with a variety of data sources inside and outside of the AWS environment. For optimal operation in a hybrid environment, AWS Glue might require additional network, firewall, or DNS configuration.
In this post, I describe a solution for transforming and moving data from an on-premises data store to Amazon S3 using AWS Glue that simulates a common data lake ingestion pipeline. AWS Glue can connect to Amazon S3 and data stores in a virtual private cloud (VPC) such as Amazon RDS, Amazon Redshift, or a database running on Amazon EC2. For more information, see Adding a Connection to Your Data Store. AWS Glue can also connect to a variety of on-premises JDBC data stores such as PostgreSQL, MySQL, Oracle, Microsoft SQL Server, and MariaDB.
AWS Glue ETL jobs can use Amazon S3, data stores in a VPC, or on-premises JDBC data stores as a source. AWS Glue jobs extract data, transform it, and load the resulting data back to S3, data stores in a VPC, or on-premises JDBC data stores as a target.
The following diagram shows the architecture of using AWS Glue in a hybrid environment, as described in this post. The solution uses JDBC connectivity using the elastic network interfaces (ENIs) in the Amazon VPC. The ENIs in the VPC help connect to the on-premises database server over a virtual private network (VPN) or AWS Direct Connect (DX).
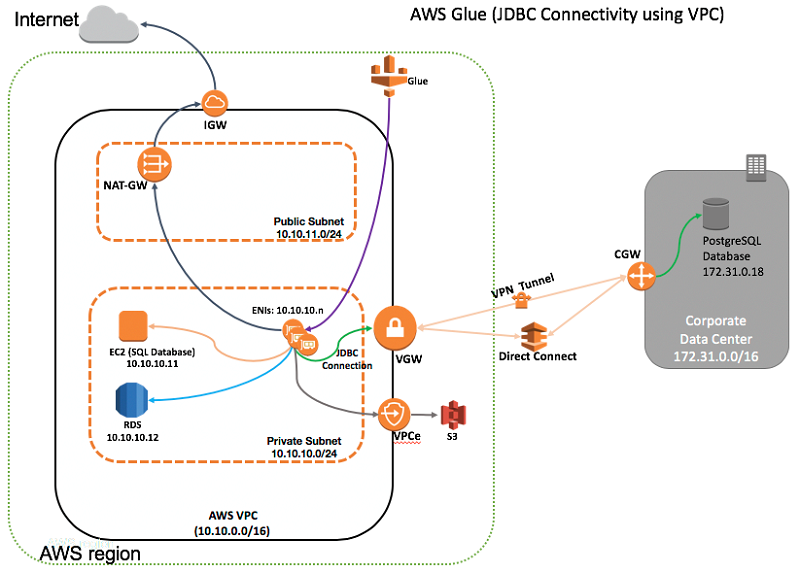
The solution architecture illustrated in the diagram works as follows:
- Network connectivity exists between the Amazon VPC and the on-premises network using a virtual private network (VPN) or AWS Direct Connect (DX).
- The JDBC connection defines parameters for a data store—for example, the JDBC connection to the PostgreSQL server running on an on-premises network.
- AWS Glue creates elastic network interfaces (ENIs) in a VPC/private subnet. These network interfaces then provide network connectivity for AWS Glue through your VPC.
- Security groups attached to ENIs are configured by the selected JDBC connection.
- The number of ENIs depends on the number of data processing units (DPUs) selected for an AWS Glue ETL job. AWS Glue DPU instances communicate with each other and with your JDBC-compliant database using ENIs.
- AWS Glue can communicate with an on-premises data store over VPN or DX connectivity. Elastic network interfaces can access an EC2 database instance or an RDS instance in the same or different subnet using VPC-level routing. ENIs can also access a database instance in a different VPC within the same AWS Region or another Region using VPC peering.
- AWS Glue uses Amazon S3 to store ETL scripts and temporary files. S3 can also be a source and a target for the transformed data. Amazon S3 VPC endpoints (VPCe) provide access to S3, as described in Amazon VPC Endpoints for Amazon S3.
- Optionally, a NAT gateway or NAT instance setup in a public subnet provides access to the internet if an AWS Glue ETL job requires either access to AWS services using a public API or outgoing internet access.
- An AWS Glue crawler uses an S3 or JDBC connection to catalog the data source, and the AWS Glue ETL job uses S3 or JDBC connections as a source or target data store.
The following walkthrough first demonstrates the steps to prepare a JDBC connection for an on-premises data store. Then it shows how to perform ETL operations on sample data by using a JDBC connection with AWS Glue.
Prepare the JDBC connection for an on-premises data store
Follow these steps to set up the JDBC connection.
Step 1: Create a security group for AWS Glue ENIs in your VPC
To allow AWS Glue to communicate with its components, specify a security group with a self-referencing inbound rule for all TCP ports. In this example, we call this security group glue-security-group. The security group attaches to AWS Glue elastic network interfaces in a specified VPC/subnet. It enables unfettered communication between the ENIs within a VPC/subnet and prevents incoming network access from other, unspecified sources.

By default, the security group allows all outbound traffic and is sufficient for AWS Glue requirements.
Optionally, if you prefer, you can tighten up outbound access to selected network traffic that is required for a specific AWS Glue ETL job. For example, the following security group setup enables the minimum amount of outgoing network traffic required for an AWS Glue ETL job using a JDBC connection to an on-premises PostgreSQL database. Your configuration might differ, so edit the outbound rules as per your specific setup.

In this example, the following outbound traffic is allowed. Edit these rules as per your setup.
- To allow AWS Glue to communicate with its components, specify a security group with a self-referencing outbound rule for all TCP ports. It enables unfettered communication between AWS Glue ENIs within a VPC/subnet.
- Port 5432/tcp: To access the on-premises PostgreSQL database server.
- Ports 53/udp, 53/tcp: Required for DNS resolution when using custom DNS servers, such as on-premises DNS servers or a DNS server running on an EC2 instance. Change the destination field as per your setup.
- Port 443/tcp: Allows traffic to all S3 IP address ranges for the AWS Region where the ETL job is running. In this example, outbound traffic is allowed to all S3 IP prefixes via VPCe for the us-east-1 Region. Edit these rules accordingly if your S3 bucket resides in a different Region.
AWS publishes IP ranges in JSON format for S3 and other services. The IP range data changes from time to time. Subscribe to change notifications as described in AWS IP Address Ranges, and update your security group accordingly.
The following example command uses curl and the jq tool to parse JSON data and list all current S3 IP prefixes for the us-east-1 Region. Use these in the security group for S3 outbound access whether you’re using an S3 VPC endpoint or accessing S3 public endpoints via a NAT gateway setup.
Step 2: Create an IAM role for AWS Glue
Create an IAM role for the AWS Glue service. For the role type, choose AWS Service, and then choose Glue. For more information, see Create an IAM Role for AWS Glue.
Add IAM policies to allow access to the AWS Glue service and the S3 bucket. In this example, the IAM role is glue_access_s3_full.
Step 3: Add a JDBC connection
To add a JDBC connection, choose Add connection in the navigation pane of the AWS Glue console. Enter the connection name, choose JDBC as the connection type, and choose Next.

On the next screen, provide the following information:
- Enter the JDBC URL for your data store. For most database engines, this field is in the following format:
For more information, see Working with Connections on the AWS Glue Console. This example uses a JDBC URL jdbc:postgresql://172.31.0.18:5432/glue_demo for an on-premises PostgreSQL server with an IP address 172.31.0.18. The PostgreSQL server is listening at a default port 5432 and serving the glue_demo database.
- Enter the database user name and password. Follow the principle of least privilege and grant only the required permission to the database user.
- Choose the VPC, private subnet, and the security group glue-security-group that you created earlier. AWS Glue creates multiple ENIs in the private subnet and associates security groups to communicate over the network.
- Complete the remaining setup by reviewing the information, as shown following.

Step 4: Open appropriate firewall ports in the on-premises data center
Edit your on-premises firewall settings and allow incoming connections from the private subnet that you selected for the JDBC connection in the previous step. AWS Glue can choose any available IP address of your private subnet when creating ENIs. The example shown here requires the on-premises firewall to allow incoming connections from the network block 10.10.10.0/24 to the PostgreSQL database server running at port 5432/tcp.
You might also need to edit your database-specific file (such as pg_hba.conf) for PostgreSQL and add a line to allow incoming connections from the remote network block. Follow your database engine-specific documentation to enable such incoming connections.
Step 5: Test the JDBC connection
Select the JDBC connection in the AWS Glue console, and choose Test connection. Choose the IAM role that you created in the previous step, and choose Test connection. It might take few moments to show the result. If you receive an error, check the following:
- The correct JDBC URL is provided.
- The correct user name and password are provided for the database with the required privileges.
- The correct network routing paths are set up and the database port access from the subnet is selected for AWS Glue ENIs
- Security groups for ENIs allow the required incoming and outgoing traffic between them, outgoing access to the database, access to custom DNS servers if in use, and network access to Amazon S3.
You are now ready to use the JDBC connection with your AWS Glue jobs.
Perform ETL in AWS Glue using the JDBC connection
This section demonstrates ETL operations using a JDBC connection and sample CSV data from the Commodity Flow Survey (CFS) open dataset published on the United States Census Bureau site. The example uses sample data to demonstrate two ETL jobs as follows:
- Part 1: An AWS Glue ETL job loads the sample CSV data file from an S3 bucket to an on-premises PostgreSQL database using a JDBC connection. The dataset then acts as a data source in your on-premises PostgreSQL database server for Part 2.
- Part 2: An AWS Glue ETL job transforms the source data from the on-premises PostgreSQL database to a target S3 bucket in Apache Parquet format.
In each part, AWS Glue crawls the existing data stored in an S3 bucket or in a JDBC-compliant database, as described in Cataloging Tables with a Crawler. The crawler samples the source data and builds the metadata in the AWS Glue Data Catalog. You then develop an ETL job referencing the Data Catalog metadata information, as described in Adding Jobs in AWS Glue.
Optionally, you can use other methods to build the metadata in the Data Catalog directly using the AWS Glue API. You can populate the Data Catalog manually by using the AWS Glue console, AWS CloudFormation templates, or the AWS CLI. You can also build and update the Data Catalog metadata within your pySpark ETL job script by using the Boto 3 Python library. The Data Catalog is Hive Metastore-compatible, and you can migrate an existing Hive Metastore to AWS Glue as described in this README file on the GitHub website.
Part 1: An AWS Glue ETL job loads CSV data from an S3 bucket to an on-premises PostgreSQL database
Start by downloading the sample CSV data file to your computer, and unzip the file. Upload the uncompressed CSV file cfs_2012_pumf_csv.txt into an S3 bucket. The CSV data file is available as a data source in an S3 bucket for AWS Glue ETL jobs. The sample CSV data file contains a header line and a few lines of data, as shown here.

First, set up the crawler and populate the table metadata in the AWS Glue Data Catalog for the S3 data source. Start by choosing Crawlers in the navigation pane on the AWS Glue console. Then choose Add crawler. Specify the crawler name.
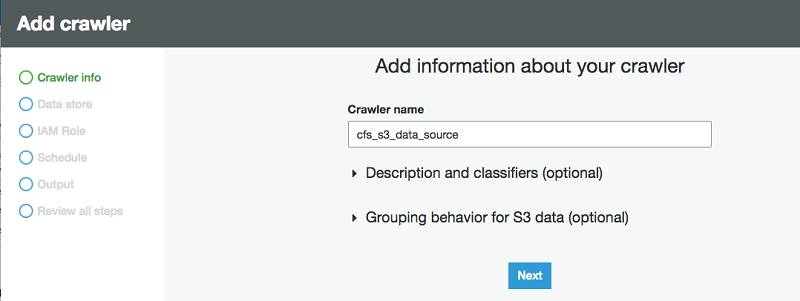
When asked for the data source, choose S3 and specify the S3 bucket prefix with the CSV sample data files. You can have one or multiple CSV files under the S3 prefix. The AWS Glue crawler crawls the sample data and generates a table schema.

Next, choose the IAM role that you created earlier. The IAM role must allow access to the AWS Glue service and the S3 bucket.

Next, choose an existing database in the Data Catalog, or create a new database entry. In this example, cfs is the database name in the Data Catalog.

Finish the remaining setup, and run your crawler at least once to create a catalog entry for the source CSV data in the S3 bucket.

Review the table that was generated in the Data Catalog after completion. The crawler creates the table with the name cfs_full and correctly identifies the data type as CSV.

Choose the table name cfs_full and review the schema created for the data source. It picked up the header row from the source CSV data file and used it for column names.

Now you can use the S3 data as a source and the on-premises PostgreSQL database as a destination, and set up an AWS Glue ETL job. The demonstration shown here is fairly simple. It loads the data from S3 to a single table in the target PostgreSQL database via the JDBC connection.
To create an ETL job, choose Jobs in the navigation pane, and then choose Add job. Specify the name for the ETL job as cfs_full_s3_to_onprem_postgres.
Choose the IAM role and S3 locations for saving the ETL script and a temporary directory area. The IAM role must allow access to the specified S3 bucket prefixes that are used in your ETL job. Optionally, you can enable Job bookmark for an ETL job. This option lets you rerun the same ETL job and skip the previously processed data from the source S3 bucket.

For your data source, choose the table cfs_full from the AWS Glue Data Catalog tables.

Next, for the data target, choose Create tables in your data target. Then choose JDBC in the drop-down list. For Connection, choose the JDBC connection my-jdbc-connection that you created earlier for the on-premises PostgreSQL database server running with the database name glue_demo.

Follow the remaining setup with the default mappings, and finish creating the ETL job.
Finally, it shows an autogenerated ETL script screen. Review the script and make any additional ETL changes, if required. When you’re ready, choose Run job to execute your ETL job.

The ETL job takes several minutes to finish. A new table is created with the name cfs_full in the PostgreSQL database with data loaded from CSV files in the S3 bucket. Verify the table and data using your favorite SQL client by querying the database. For example, run the following SQL query to show the results:
SELECT * FROM cfs_full ORDER BY shipmt_id LIMIT 10;

The table data in the on-premises PostgreSQL database now acts as source data for Part 2 described next.
Part 2: An AWS Glue ETL job transforms the data from an on-premises PostgreSQL database to Parquet format
In this section, you configure the on-premises PostgreSQL database table as a source for the ETL job. It transforms the data into Apache Parquet format and saves it to the destination S3 bucket.
Set up another crawler that points to the PostgreSQL database table and creates a table metadata in the AWS Glue Data Catalog as a data source. Optionally, you can build the metadata in the Data Catalog directly using other methods, as described previously.

Next, select the JDBC connection my-jdbc-connection that you created earlier for the on-premises PostgreSQL database server. For Include path, provide the table name path as glue_demo/public/cfs_full. It refers to the PostgreSQL table name cfs_full in a public schema with a database name of glue_demo.

Follow the remaining setup steps, provide the IAM role, and create an AWS Glue Data Catalog table in the existing database cfs that you created before. Optionally, provide a prefix for a table name onprem_postgres_ created in the Data Catalog, representing on-premises PostgreSQL table data.
Run the crawler and view the table created with the name onprem_postgres_glue_demo_public_cfs_full in the AWS Glue Data Catalog. Verify the table schema and confirm that the crawler captured the schema details.

(Optional) Tuning for JDBC read parallelism
In some cases, running an AWS Glue ETL job over a large database table results in out-of-memory (OOM) errors because all the data is read into a single executor. To avoid this situation, you can optimize the number of Apache Spark partitions and parallel JDBC connections that are opened during the job execution.
After crawling a database table, follow these steps to tune the parameters.
- In the Data Catalog, edit the table and add the partitioning parameters hashexpression or hashfield. The job partitions the data for a large table along with the column selected for these parameters, as described following.
- hashexpression: If your database table contains a column with numeric values such as a unique ID or similar data, choose the column name for a parameter hashexpression. In this example, shipmt_id is a monotonically increasing column and a good candidate for hashexpression
- hashfield: If no suitable numeric column is available, find a column containing string values with a good even distribution (high cardinality), and choose the column name for a parameter hashfield.
- hashpartitions: Provide a value of hashpartition as a number. By default, this value is set to 7. This parameter determines the number of Spark partitions and the resulting number of JDBC connections opened to the target database.
In this example, hashexpression is selected as shipmt_id with the hashpartition value as 15.

Next, create another ETL job with the name cfs_onprem_postgres_to_s3_parquet. Choose the IAM role and S3 bucket locations for the ETL script, and so on.
On the next screen, choose the data source onprem_postgres_glue_demo_public_cfs_full from the AWS Glue Data Catalog that points to the on-premises PostgreSQL data table. Next, choose Create tables in your data target. For Format, choose Parquet, and set the data target path to the S3 bucket prefix.

Follow the prompts until you get to the ETL script screen. The autogenerated pySpark script is set to fetch the data from the on-premises PostgreSQL database table and write multiple Parquet files in the target S3 bucket. By default, all Parquet files are written at the same S3 prefix level.

Optionally, if you prefer to partition data when writing to S3, you can edit the ETL script and add partitionKeys parameters as described in the AWS Glue documentation. For this example, edit the pySpark script and search for a line to add an option “partitionKeys“: [“quarter“], as shown here.
Choose Save and run job. The job executes and outputs data in multiple partitions when writing Parquet files to the S3 bucket. Each output partition corresponds to the distinct value in the column name quarter in the PostgreSQL database table.
The ETL job transforms the CFS data into Parquet format and separates it under four S3 bucket prefixes, one for each quarter of the year. The S3 bucket output listings shown following are using the S3 CLI.

Notice that AWS Glue opens several database connections in parallel during an ETL job execution based on the value of the hashpartitions parameters set before. For PostgreSQL, you can verify the number of active database connections by using the following SQL command:
The transformed data is now available in S3, and it can act as a data lake. Data is ready to be consumed by other services, such as upload to an Amazon Redshift based data warehouse or perform analysis by using Amazon Athena and Amazon QuickSight.
To demonstrate, create and run a new crawler over the partitioned Parquet data generated in the preceding step. Go to the new table created in the Data Catalog and choose Action, View data. You can then run an SQL query over the partitioned Parquet data in the Athena Query Editor, as shown here.

The following is an example SQL query with Athena. Note the use of the partition key quarter with the WHERE clause in the SQL query, to limit the amount of data scanned in the S3 bucket with the Athena query.

Other considerations for a hybrid setup
In some scenarios, your environment might require some additional configuration. This section describes the setup considerations when you are using custom DNS servers, as well as some considerations for VPC/subnet routing and security groups when using multiple JDBC connections.
Custom DNS servers
For a VPC, make sure that the network attributes enableDnsHostnames and enableDnsSupport are set to true. For more information, see Setting Up DNS in Your VPC.
When you use a custom DNS server for the name resolution, both forward DNS lookup and reverse DNS lookup must be implemented for the whole VPC/subnet used for AWS Glue elastic network interfaces. ENIs are ephemeral and can use any available IP address in the subnet. ETL jobs might receive a DNS error when both forward and reverse DNS lookup don’t succeed for an ENI IP address.
For example, assume that an AWS Glue ENI obtains an IP address 10.10.10.14 in a VPC/subnet. When you use a default VPC DNS resolver, it correctly resolves a reverse DNS for an IP address 10.10.10.14 as ip-10-10-10-14.ec2.internal. It resolves a forward DNS for a name ip-10-10-10-14.ec2.internal. as 10.10.10.14. The ETL job doesn’t throw a DNS error.
When you use a custom DNS server such as on-premises DNS servers connecting over VPN or DX, be sure to implement the similar DNS resolution setup. Refer to your DNS server documentation. For example, if you are using BIND, you can use the $GENERATE directive to create a series of records easily.
Another option is to implement a DNS forwarder in your VPC and set up hybrid DNS resolution to resolve using both on-premises DNS servers and the VPC DNS resolver. For implementation details, see the following AWS Security Blog posts:
- How to Set Up DNS Resolution Between On-Premises Networks and AWS by Using Unbound
- How to Set Up DNS Resolution Between On-Premises Networks and AWS Using AWS Directory Service and Microsoft Active Directory
AWS Glue ETL jobs with more than one JDBC connection
When you test a single JDBC connection or run a crawler using a single JDBC connection, AWS Glue obtains the VPC/subnet and security group parameters for ENIs from the selected JDBC connection configuration. AWS Glue then creates ENIs and accesses the JDBC data store over the network. Also, this works well for an AWS Glue ETL job that is set up with a single JDBC connection.
Additional setup considerations might apply when a job is configured to use more than one JDBC connection. For example, the first JDBC connection is used as a source to connect a PostgreSQL database, and the second JDBC connection is used as a target to connect an Amazon Aurora database. In this scenario, AWS Glue picks up the JDBC driver (JDBC URL) and credentials (user name and password) information from the respective JDBC connections.
However, for ENIs, it picks up the network parameter (VPC/subnet and security groups) information from only one of the JDBC connections out of the two that are configured for the ETL job. AWS Glue then creates ENIs in the VPC/subnet and associate security groups as defined with only one JDBC connection. It then tries to access both JDBC data stores over the network using the same set of ENIs.
In some cases, this can lead to a job error if the ENIs that are created with the chosen VPC/subnet and security group parameters from one JDBC connection prohibit access to the second JDBC data store.
The following table explains several scenarios and additional setup considerations for AWS Glue ETL jobs to work with more than one JDBC connection.
|
ETL job with two JDBC connections scenario |
Additional setup considerations | How it works |
| Both JDBC connections use the same VPC/subnet and security group parameters. | No additional setup required. |
AWS Glue creates ENIs with the same parameters for the VPC/subnet and security group, chosen from either of the JDBC connections. In this case, the ETL job works well with two JDBC connections. |
| Both JDBC connections use the same VPC/subnet, but use different security group parameters. |
Option 1: Consolidate the security groups (SG) applied to both JDBC connections by merging all SG rules. Create a new common security group with all consolidated rules. Apply the new common security group to both JDBC connections. Option 2: Have a combined list containing all security groups applied to both JDBC connections. Apply all security groups from the combined list to both JDBC connections. |
AWS Glue creates ENIs with the same parameters for the VPC/subnet and security group, chosen from either of the JDBC connections. In this case, the ETL job works well with two JDBC connections after you apply additional setup steps. |
| Both JDBC connections use different VPC/subnet and different security group parameters. |
For the security group, apply a setup similar to Option 1 or Option 2 in the previous scenario. For VPC/subnet, make sure that the routing table and network paths are configured to access both JDBC data stores from either of the VPC/subnets. |
AWS Glue creates ENIs with the same security group parameters chosen from either of the JDBC connection. The VPC/subnet routing level setup ensures that the AWS Glue ENIs can access both JDBC data stores from either of the selected VPC/subnets. In this case, the ETL job works well with two JDBC connections after you apply additional setup steps. |
Summary
This post demonstrated how to set up AWS Glue in a hybrid environment. While using AWS Glue as a managed ETL service in the cloud, you can use existing connectivity between your VPC and data centers to reach an existing database service without significant migration effort. This provides you with an immediate benefit.
You can also use a similar setup when running workloads in two different VPCs. You can set up a JDBC connection over a VPC peering link between two VPCs within an AWS Region or across different Regions and by using inter-region VPC peering.
You can create a data lake setup using Amazon S3 and periodically move the data from a data source into the data lake. AWS Glue and other cloud services such as Amazon Athena, Amazon Redshift Spectrum, and Amazon QuickSight can interact with the data lake in a very cost-effective manner. To learn more, see Build a Data Lake Foundation with AWS Glue and Amazon S3.
Additional Reading
If you found this post useful, be sure to check out Orchestrate multiple ETL jobs using AWS Step Functions and AWS Lambda, as well as AWS Glue Developer Resources.
About the Author
 Rajeev Meharwal is a Solutions Architect for AWS Public Sector Team. Rajeev loves to interact and help customers to implement state of the art architecture in the Cloud. His core focus is in the area of Networking, Serverless Computing and Data Analytics in the Cloud. He enjoys hiking with his family, playing badminton and chasing around his playful dog.
Rajeev Meharwal is a Solutions Architect for AWS Public Sector Team. Rajeev loves to interact and help customers to implement state of the art architecture in the Cloud. His core focus is in the area of Networking, Serverless Computing and Data Analytics in the Cloud. He enjoys hiking with his family, playing badminton and chasing around his playful dog.