AWS Big Data Blog
Amazon Redshift Engineering’s Advanced Table Design Playbook: Compression Encodings
Part 1: Preamble, Prerequisites, and Prioritization
Part 2: Distribution Styles and Distribution Keys
Part 3: Compound and Interleaved Sort Keys
Part 4: Compression Encodings (Translated into Japanese)
Part 5: Table Data Durability
In part 4 of this blog series, I’ll be discussing when and when not to apply column encoding for compression, methods for determining ideal column encodings, and automatic compression behaviors in Amazon Redshift.
Data compression in database systems isn’t new. However, historically it was used to reduce data footprint, rather than boost performance, because of its expensive decompression overhead. In Amazon Redshift, using column encodings translates to both a data footprint reduction and a performance gain, because the cost of decompression is negligible relative to the reduction of disk I/O.
Within a Amazon Redshift table, each column can be specified with an encoding that is used to compress the values within each block. In general, compression should be used for almost every column within an Amazon Redshift cluster – but there are a few scenarios where it is better to avoid encoding columns.
The method I use for prioritizing compression related optimizations is a bit different than the prioritization method we used in the preceding parts, largely because you might already have implemented automatic or manual compression for many of your important tables. The approach we use to determine which tables to review for compression is based on measuring the size of uncompressed storage per table:
SELECT
ti.schema||'.'||ti."table" tablename,
uncompressed_size.size uncompressed_size,
ti.size total_size
FROM svv_table_info ti
LEFT JOIN (
SELECT tbl,COUNT(*) size
FROM stv_blocklist
WHERE (tbl,col) IN (
SELECT attrelid, attnum-1
FROM pg_attribute
WHERE attencodingtype=0 AND attnum>0)
GROUP BY 1) uncompressed_size ON ti.table_id = uncompressed_size.tbl
ORDER BY 2 DESC NULLS LAST;Using the results of the query preceding to prioritize efforts, we can work through this simple flowchart to determine whether to compress or not:
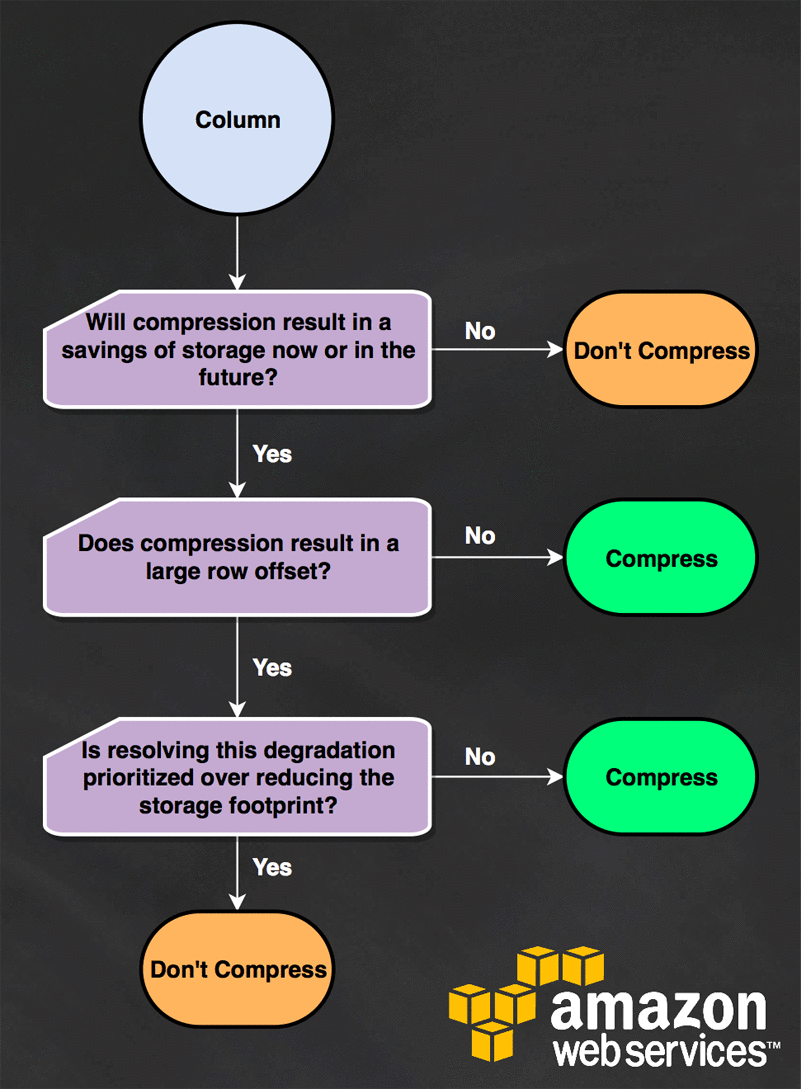
Will compression reduce your storage footprint now or in the future?
If adding compression encoding to your column doesn’t result in storage reduction, there’s no value in introducing compression. You are now only incurring a decompression cost when that data is accessed. Although this decompression cost is largely negligible, it’s still best to only use compression encoding when you benefit.
If your table is already at its minimum table size, compression won’t reduce the size of the data on disk. You can use the v_extended_table_info view we defined in an earlier post to identify which tables show uncompressed columns, how much storage those columns are consuming, and which of these tables are at minimum size:
SELECT eti.tablename, eti.columns,
uncompressed_size.size uncompressed_size, eti.size total_size
FROM admin.v_extended_table_info eti
LEFT JOIN (
SELECT tbl,COUNT(*) size
FROM stv_blocklist
JOIN pg_attribute ON tbl=attrelid
AND col = attnum-1
AND attencodingtype=0
AND attnum>0
GROUP BY 1) uncompressed_size
ON eti.table_id = uncompressed_size.tbl
WHERE uncompressed_size.size IS NOT NULL
ORDER BY uncompressed_size.size DESC;
tablename | columns | uncompressed_size | total_size
-----------------+---------+-------------------+--------------------
public.lineitem | 15/16 | 2298 | 26695/114 (4.6677)
public.partsupp | 4/5 | 306 | 4224/48 (0.7385)
public.nation | 0/4 | 24 | 42/42 (0.0073)
public.region | 0/3 | 15 | 30/36 (0.0052)
(4 rows)
The following explains the query result set:
- columns: X/Y where:
- X is the number of compressed columns
- Y is the total number of columns
- uncompressed_size: Total number of 1 MB blocks consumed by the uncompressed columns in the table
- total_size: T/M (P) where:
- T is the total size of the table, in 1 MB blocks
- M is the minimum size of the table, assuming all slices in the cluster are populated with at least one row
- P is the percentage of total cluster storage consumed by the table
An interpretation of the results from the example preceding is as follows:
- There is an uncompressed column in lineitem consuming 2298 MB.
- There is an uncompressed column in partsupp consuming 306 MB.
- All four columns in nation are uncompressed, but the table is at the minimum table size so compressing these columns results in no gain.
- All three columns in region are uncompressed, but the table is at the minimum table size so compressing these columns results in no gain.
If the tables with uncompressed columns are reporting as at or below the minimum table size, and you expect that table size not to significantly change in the future, you can conclude that compression won’t result in a storage footprint reduction or performance improvement. Thus, you shouldn’t implement compression.
Does compression result in a large row offset?
The performance benefits of compressing a column are realized as disk I/O reduction. This I/O reduction benefits the read workload most significantly, because the tables are accessed for scans during query processing.
It’s important to be aware of one edge case triggered by excessive compression that can result in a performance degradation. A rare performance degradation can arise in situations that meet the following criteria:
- Your query patterns apply range restricted scans to a column that is very well compressed.
- The well compressed column’s blocks each contain a large number of values per block, typically many more values than the actual count of values your query is interested in.
- The other columns necessary for the query pattern are large or don’t compress well. These columns are > 10x the size of the well compressed column.
The details of this edge case go deep into the Amazon Redshift internals, and I find it most effective to provide a detailed explanation elsewhere.
If you are not encountering query patterns such as this, compression should be implemented.
Is resolving this degradation, from a large row offset, prioritized over reducing storage footprint?
If you observe this degradation, it can be easily mitigated by reducing the compression effectiveness for that column—which can be achieved by changing encoding types or removing encoding altogether for that column. Alternatively, if your large columns are not optimally compressed, then you can also resolve the issue by defining those with ideal compression encodings.
In some cases, the only solution to resolve the performance issue is to modify the compression on the column, degrading the efficiency of the compression. In these cases, you need to determine if increasing the size of the column is an acceptable trade-off. If your cluster is constrained on storage, this option might not work for you until you resize to a larger cluster.
If you have storage to spare, then you can resolve the issue immediately by changing the encoding or not using encoding.
Automatic encoding methods
If you find that a number of your tables are compressed, but you don’t remember choosing compression encodings, then your tables benefitted from one of the automatic encoding optimizations in Amazon Redshift. This effect can occur in two different ways:
CTAS: You’ve recently created the table using a CTAS statement. In a recent optimization, we applied default LZO compression to all columns that are not part of a sort key and are not of data types Boolean, float, or double precision.
COPY’s COMPUPDATE: If you create an empty table without any encoding on any columns, and then populate that table using a COPY command without explicitly changing the COMPUPDATE option, then the table undergoes automatic compression analysis.
When these criteria are met, the COPY command automatically performs automatic compression analysis before data ingestion. This process first samples a subset of the data from Amazon S3 and then performs a brute-force compression comparison. To do so, it compresses a small set of the data in each possible way, one column at a time. After all possible encodings are performed, COPY makes a comparison. Then whatever encoding results in the most significant compression is defined as the column encoding for that table. After this process, COPY begins the standard ingestion portion of its operation.
This functionality promotes ease of use. The overhead of frequently performing this compression analysis is costly, and this analysis can take longer to complete than data load. COPY doesn’t perform automatic compression analysis if the table is not empty, if the table has any columns with compression encodings defined, or if the COMPUPDATE option is set to OFF in the COPY command.
Compression analysis methods
Now that you’ve found columns that aren’t compressed but should be, you have a few options for how to determine the compression encoding for those columns, as follows.
ANALYZE COMPRESSION: The ANALYZE COMPRESSION SQL command samples data from an existing table and does a brute force compression comparison, similar to the process carried out by COPY’s automatic compression analysis. These are the key differences of ANALYZE COMPRESSION’s version:
- An exclusive lock is necessary and is held for the duration
- The table is not rebuilt; only a recommendation is returned
ColumnEncodingUtility: This utility, available in our amazon-redshift-utils project, relies on the ANALYZE COMPRESSION statement. However, rather than just returning a recommendation, it generates all the necessary SQL code to rebuild your tables with the recommended encodings. It can even be configured to automatically execute that SQL on your behalf.
Intrinsic knowledge: The methods that leverage ANALYZE COMPRESSION or COPY’s automatic compression analysis both depend on data sampling and comparisons to arrive at a recommendation. For this reason, if you have intrinsic knowledge of a data profile for a column and how it might change or remain the same in the future, you might be able to choose an encoding that is more optimal than our algorithm could predict.
Next steps
As discussed, you can almost always use compression encodings to reduce storage footprint reduction and boost performance. After you know how to identify the columns needing compression and what encodings to apply, simply rebuild the table to apply these optimizations.
In part 5, the final component of our table design playbook, I’ll describe how to use table data durability for another performance gain.
Amazon Redshift Engineering’s Advanced Table Design Playbook
Part 1: Preamble, Prerequisites, and Prioritization
Part 2: Distribution Styles and Distribution Keys
Part 3: Compound and Interleaved Sort Keys
Part 4: Compression Encodings
Part 5: Table Data Durability
About the author
 Zach Christopherson is a Palo Alto based Senior Database Engineer at AWS.
He assists Amazon Redshift users from all industries in fine-tuning their workloads for optimal performance. As a member of the Amazon Redshift service team, he also influences and contributes to the development of new and existing service features. In his spare time, he enjoys trying new restaurants with his wife, Mary, and caring for his newborn daughter, Sophia.
Zach Christopherson is a Palo Alto based Senior Database Engineer at AWS.
He assists Amazon Redshift users from all industries in fine-tuning their workloads for optimal performance. As a member of the Amazon Redshift service team, he also influences and contributes to the development of new and existing service features. In his spare time, he enjoys trying new restaurants with his wife, Mary, and caring for his newborn daughter, Sophia.
Related
Top 10 Performance Tuning Techniques for Amazon Redshift (Updated Nov. 28, 2016)