AWS Big Data Blog
Top 10 performance tuning techniques for Amazon Redshift
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks.
Customers use Amazon Redshift for everything from accelerating existing database environments, to ingesting weblogs for big data analytics. Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. Amazon Redshift provides an open standard JDBC/ODBC driver interface, which allows you to connect your existing business intelligence (BI) tools and reuse existing analytics queries.
Amazon Redshift can run any type of data model, from a production transaction system third-normal-form model to star and snowflake schemas, data vault, or simple flat tables.
This post takes you through the most common performance-related opportunities when adopting Amazon Redshift and gives you concrete guidance on how to optimize each one.
What’s new
This post refreshes the Top 10 post from early 2019. We’re pleased to share the advances we’ve made since then, and want to highlight a few key points.
Query throughput is more important than query concurrency.
Configuring concurrency, like memory management, can be relegated to Amazon Redshift’s internal ML models through Automatic WLM with Query Priorities. On production clusters across the fleet, we see the automated process assigning a much higher number of active statements for certain workloads, while a lower number for other types of use-cases. This is done to maximize throughput, a measure of how much work the Amazon Redshift cluster can do over a period of time. Examples are 300 queries a minute, or 1,500 SQL statements an hour. It’s recommended to focus on increasing throughput over concurrency, because throughput is the metric with much more direct impact on the cluster’s users.
In addition to the optimized Automatic WLM settings to maximize throughput, the concurrency scaling functionality in Amazon Redshift extends the throughput capability of the cluster to up to 10 times greater than what’s delivered with the original cluster. The tenfold increase is a current soft limit, you can reach out to your account team to increase it.
Investing in the Amazon Redshift driver.
AWS now recommends the Amazon Redshift JDBC or ODBC driver for improved performance. Each driver has optional configurations to further tune it for higher or lower number of statements, with either fewer or greater row counts in the result set.
Ease of use by automating all the common DBA tasks.
In 2018, the SET DW “backronym” summarized the key considerations to drive performance (sort key, encoding, table maintenance, distribution, and workload management). Since then, Amazon Redshift has added automation to inform 100% of SET DW, absorbed table maintenance into the service’s (and no longer the user’s) responsibility, and enhanced out-of-the-box performance with smarter default settings. Amazon Redshift Advisor continuously monitors the cluster for additional optimization opportunities, even if the mission of a table changes over time. AWS publishes the benchmark used to quantify Amazon Redshift performance, so anyone can reproduce the results.
Scaling compute separately from storage with RA3 nodes and Amazon Redshift Spectrum.
Although the convenient cluster building blocks of the Dense Compute and Dense Storage nodes continue to be available, you now have a variety of tools to further scale compute and storage separately. Amazon Redshift Managed Storage (the RA3 node family) allows for focusing on using the right amount of compute, without worrying about sizing for storage. Concurrency scaling lets you specify entire additional clusters of compute to be applied dynamically as-needed. Amazon Redshift Spectrum uses the functionally-infinite capacity of Amazon Simple Storage Service (Amazon S3) to support an on-demand compute layer up to 10 times the power of the main cluster, and is now bolstered with materialized view support.
Pause and resume feature to optimize cost of environments
All Amazon Redshift clusters can use the pause and resume feature. For clusters created using On Demand, the per-second grain billing is stopped when the cluster is paused. Reserved Instance clusters can use the pause and resume feature to define access times or freeze a dataset at a point in time.
Tip #1: Precomputing results with Amazon Redshift materialized views
Materialized views can significantly boost query performance for repeated and predictable analytical workloads such as dash-boarding, queries from BI tools, and extract, load, transform (ELT) data processing. Data engineers can easily create and maintain efficient data-processing pipelines with materialized views while seamlessly extending the performance benefits to data analysts and BI tools.
Materialized views are especially useful for queries that are predictable and repeated over and over. Instead of performing resource-intensive queries on large tables, applications can query the pre-computed data stored in the materialized view.
When the data in the base tables changes, you refresh the materialized view by issuing the Amazon Redshift SQL statement “refresh materialized view“. After issuing a refresh statement, your materialized view contains the same data as a regular view. Refreshes can be incremental or full refreshes (recompute). When possible, Amazon Redshift incrementally refreshes data that changed in the base tables since the materialized view was last refreshed.
To demonstrate how it works, we can create an example schema to store sales information, each sale transaction and details about the store where the sales took place.
To view the total amount of sales per city, we create a materialized view with the create materialized view SQL statement (city_sales) joining records from two tables and aggregating sales amount (sum(sales.amount)) per city (group by city):
Now we can query the materialized view just like a regular view or table and issue statements like “SELECT city, total_sales FROM city_sales” to get the following results. The join between the two tables and the aggregate (sum and group by) are already computed, resulting in significantly less data to scan.
When the data in the underlying base tables changes, the materialized view doesn’t automatically reflect those changes. You can refresh the data stored in the materialized view on demand with the latest changes from the base tables using the SQL refresh materialized view command. For example, see the following code:
The full code for this use case is available as a gist in GitHub.
You can also extend the benefits of materialized views to external data in your Amazon S3 data lake and federated data sources. With materialized views, you can easily store and manage the pre-computed results of a SELECT statement referencing both external tables and Amazon Redshift tables. Subsequent queries referencing the materialized views run much faster because they use the pre-computed results stored in Amazon Redshift, instead of accessing the external tables. This also helps you reduce the associated costs of repeatedly accessing the external data sources, because you can only access them when you explicitly refresh the materialized views.
Tip #2: Handling bursts of workload with concurrency scaling and elastic resize
The legacy, on-premises model requires you to estimate what the system will need 3-4 years in the future to make sure you’re leasing enough horsepower at the time of purchase. But the ability to resize a cluster allows for right-sizing your resources as you go. Amazon Redshift extends this ability with elastic resize and concurrency scaling.
Elastic resize lets you quickly increase or decrease the number of compute nodes, doubling or halving the original cluster’s node count, or even change the node type. You can expand the cluster to provide additional processing power to accommodate an expected increase in workload, such as Black Friday for internet shopping, or a championship game for a team’s web business. Choose classic resize when you’re resizing to a configuration that isn’t available through elastic resize. Classic resize is slower but allows you to change the node type or expand beyond the doubling or halving size limitations of an elastic resize.
Elastic resize completes in minutes and doesn’t require a cluster restart. For anticipated workload spikes that occur on a predictable schedule, you can automate the resize operation using the elastic resize scheduler feature on the Amazon Redshift console, the AWS Command Line Interface (AWS CLI), or API.
Concurrency scaling allows your Amazon Redshift cluster to add capacity dynamically in response to the workload arriving at the cluster.
By default, concurrency scaling is disabled, and you can enable it for any workload management (WLM) queue to scale to a virtually unlimited number of concurrent queries, with consistently fast query performance. You can control the maximum number of concurrency scaling clusters allowed by setting the “max_concurrency_scaling_clusters” parameter value from 1 (default) to 10 (contact support to raise this soft limit). The free billing credits provided for concurrency scaling is often enough and the majority of customers using this feature don’t end up paying extra for it. For more information about the concurrency scaling billing model see Concurrency Scaling pricing.
You can monitor and control the concurrency scaling usage and cost by creating daily, weekly, or monthly usage limits and instruct Amazon Redshift to automatically take action (such as logging, alerting or disabling further usage) if those limits are reached. For more information, see Managing usage limits in Amazon Redshift.
Together, these options open up new ways to right-size the platform to meet demand. Before these options, you needed to size your WLM queue, or even an entire Amazon Redshift cluster, beforehand in anticipation of upcoming peaks.
Tip #3: Using the Amazon Redshift Advisor to minimize administrative work
Amazon Redshift Advisor offers recommendations specific to your Amazon Redshift cluster to help you improve its performance and decrease operating costs.
Advisor bases its recommendations on observations regarding performance statistics or operations data. Advisor develops observations by running tests on your clusters to determine if a test value is within a specified range. If the test result is outside of that range, Advisor generates an observation for your cluster. At the same time, Advisor creates a recommendation about how to bring the observed value back into the best-practice range. Advisor only displays recommendations that can have a significant impact on performance and operations. When Advisor determines that a recommendation has been addressed, it removes it from your recommendation list. In this section, we share some examples of Advisor recommendations:
Distribution key recommendation
Advisor analyzes your cluster’s workload to identify the most appropriate distribution key for the tables that can significantly benefit from a KEY distribution style. Advisor provides ALTER TABLE statements that alter the DISTSTYLE and DISTKEY of a table based on its analysis. To realize a significant performance benefit, make sure to implement all SQL statements within a recommendation group.
The following screenshot shows recommendations regarding distribution keys.

If you don’t see a recommendation, that doesn’t necessarily mean that the current distribution styles are the most appropriate. Advisor doesn’t provide recommendations when there isn’t enough data or the expected benefit of redistribution is small.
Sort key recommendation
Sorting a table on an appropriate sort key can accelerate query performance, especially queries with range-restricted predicates, by requiring fewer table blocks to be read from disk.
Advisor analyzes your cluster’s workload over several days to identify a beneficial sort key for your tables. See the following screenshot.

If you don’t see a recommendation for a table, that doesn’t necessarily mean that the current configuration is the best. Advisor doesn’t provide recommendations when there isn’t enough data or the expected benefit of sorting is small.
Table compression recommendation
Amazon Redshift is optimized to reduce your storage footprint and improve query performance by using compression encodings. When you don’t use compression, data consumes additional space and requires additional disk I/O. Applying compression to large uncompressed columns can have a big impact on your cluster.
The compression analysis in Advisor tracks uncompressed storage allocated to permanent user tables. It reviews storage metadata associated with large uncompressed columns that aren’t sort key columns.
The following screenshot shows an example of table compression recommendation.
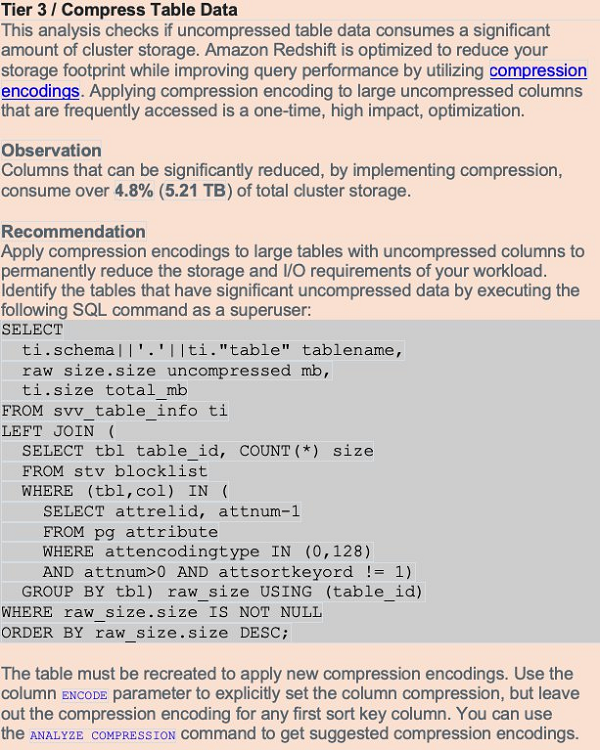
Table statistics recommendation
Maintaining current statistics helps complex queries run in the shortest possible time. The Advisor analysis tracks tables whose statistics are out-of-date or missing. It reviews table access metadata associated with complex queries. If tables that are frequently accessed with complex patterns are missing statistics, Amazon Redshift Advisor creates a critical recommendation to run ANALYZE. If tables that are frequently accessed with complex patterns have out-of-date statistics, Advisor creates a suggested recommendation to run ANALYZE.
The following screenshot shows a table statistics recommendation.

Tip #4: Using Auto WLM with priorities to increase throughput
Auto WLM simplifies workload management and maximizes query throughput by using ML to dynamically manage memory and concurrency, which ensures optimal utilization of the cluster resources
Amazon Redshift runs queries using the queuing system (WLM). You can define up to eight queues to separate workloads from each other.
Amazon Redshift Advisor automatically analyzes the current WLM usage and can make recommendations to get more throughput from your cluster. Periodically reviewing the suggestions from Advisor helps you get the best performance.
Query priorities is a feature of Auto WLM that lets you assign priority ranks to different user groups or query groups, to ensure that higher priority workloads get more resources for consistent query performance, even during busy times. It is a good practice to set up query monitoring rules (QMR) to monitor and manage resource intensive or runaway queries. QMR also enables you to dynamically change a query’s priority based on its runtime performance and metrics-based rules you define.
For more information on migrating from manual to automatic WLM with query priorities, see Modifying the WLM configuration.
It’s recommended to take advantage of Amazon Redshift’s short query acceleration (SQA). SQA uses ML to run short-running jobs in their own queue. This keeps small jobs processing, rather than waiting behind longer-running SQL statements. SQA is enabled by default in the default parameter group and for all new parameter groups. You can enable and disable SQA via a check box on the Amazon Redshift console, or by using the Amazon Redshift CLI.
If you enable concurrency scaling, Amazon Redshift can automatically and quickly provision additional clusters should your workload begin to back up. This is an important consideration when deciding the cluster’s WLM configuration.
A common pattern is to optimize the WLM configuration to run most SQL statements without the assistance of supplemental memory, reserving additional processing power for short jobs. Some queueing is acceptable because additional clusters spin up if your needs suddenly expand. To enable concurrency scaling on a WLM queue, set the concurrency scaling mode value to AUTO. You can best inform your decisions by reviewing the concurrency scaling billing model. You can also monitor and control the concurrency scaling usage and cost by using the Amazon Redshift usage limit feature.
In some cases, unless you enable concurrency scaling for the queue, the user or query’s assigned queue may be busy, and you must wait for a queue slot to open. During this time, the system isn’t running the query at all. If this becomes a frequent problem, you may have to increase concurrency.
First, determine if any queries are queuing, using the queuing_queries.sql admin script. Review the maximum concurrency that your cluster needed in the past with wlm_apex.sql, or get an hour-by-hour historical analysis with wlm_apex_hourly.sql. Keep in mind that increasing concurrency allows more queries to run, but each query gets a smaller share of the memory. You may find that by increasing concurrency, some queries must use temporary disk storage to complete, which is also sub-optimal.
Tip #5: Taking advantage of Amazon Redshift data lake integration
Amazon Redshift is tightly integrated with other AWS-native services such as Amazon S3 which let’s the Amazon Redshift cluster interact with the data lake in several useful ways.
Amazon Redshift Spectrum lets you query data directly from files on Amazon S3 through an independent, elastically sized compute layer. Use these patterns independently or apply them together to offload work to the Amazon Redshift Spectrum compute layer, quickly create a transformed or aggregated dataset, or eliminate entire steps in a traditional ETL process.
- Use the Amazon Redshift Spectrum compute layer to offload workloads from the main cluster, and apply more processing power to the specific SQL statement. Amazon Redshift Spectrum automatically assigns compute power up to approximately 10 times the processing power of the main cluster. This may be an effective way to quickly process large transform or aggregate jobs.
- Skip the load in an ELT process and run the transform directly against data on Amazon S3. You can run transform logic against partitioned, columnar data on Amazon S3 with an INSERT … SELECT statement. It’s easier than going through the extra work of loading a staging dataset, joining it to other tables, and running a transform against it.
- Use Amazon Redshift Spectrum to run queries as the data lands in Amazon S3, rather than adding a step to load the data onto the main cluster. This allows for real-time analytics.
- Land the output of a staging or transformation cluster on Amazon S3 in a partitioned, columnar format. The main or reporting cluster can either query from that Amazon S3 dataset directly or load it via an INSERT … SELECT statement.
Within Amazon Redshift itself, you can export the data into the data lake with the UNLOAD command, or by writing to external tables. Both options export SQL statement output to Amazon S3 in a massively parallel fashion. You can do the following:
- Using familiar CREATE EXTERNAL TABLE AS SELECT and INSERT INTO SQL commands, create and populate external tables on Amazon S3 for subsequent use by Amazon Redshift or other services participating in the data lake without the need to manually maintain partitions. Materialized views can also cover external tables, further enhancing the accessibility and utility of the data lake.
- Using the UNLOAD command, Amazon Redshift can export SQL statement output to Amazon S3 in a massively parallel fashion. This technique greatly improves the export performance and lessens the impact of running the data through the leader node. You can compress the exported data on its way off the Amazon Redshift cluster. As the size of the output grows, so does the benefit of using this feature. For writing columnar data to the data lake, UNLOAD can write partition-aware Parquet data.
Tip #6: Improving the efficiency of temporary tables
Amazon Redshift provides temporary tables, which act like normal tables but have a lifetime of a single SQL session. The proper use of temporary tables can significantly improve performance of some ETL operations. Unlike regular permanent tables, data changes made to temporary tables don’t trigger automatic incremental backups to Amazon S3, and they don’t require synchronous block mirroring to store a redundant copy of data on a different compute node. Due to these reasons, data ingestion on temporary tables involves reduced overhead and performs much faster. For transient storage needs like staging tables, temporary tables are ideal.
You can create temporary tables using the CREATE TEMPORARY TABLE syntax, or by issuing a SELECT … INTO #TEMP_TABLE query. The CREATE TABLE statement gives you complete control over the definition of the temporary table. The SELECT … INTO and C(T)TAS commands use the input data to determine column names, sizes and data types, and use default storage properties. Consider default storage properties carefully, because they may cause problems. By default, for temporary tables, Amazon Redshift applies EVEN table distribution with no column encoding (such as RAW compression) for all columns. This data structure is sub-optimal for many types of queries.
If you employ the SELECT…INTO syntax, you can’t set the column encoding, column distribution, or sort keys. The CREATE TABLE AS (CTAS) syntax instead lets you specify a distribution style and sort keys, and Amazon Redshift automatically applies LZO encoding for everything other than sort keys, Booleans, reals, and doubles. You can exert additional control by using the CREATE TABLE syntax rather than CTAS.
If you create temporary tables, remember to convert all SELECT…INTO syntax into the CREATE statement. This ensures that your temporary tables have column encodings and don’t cause distribution errors within your workflow. For example, you may want to convert a statement using this syntax:
You need to analyze the temporary table for optimal column encoding:
You can then convert the SELECT INTO a statement to the following:
If you create a temporary staging table by using a CREATE TABLE LIKE statement, the staging table inherits the distribution key, sort keys, and column encodings from the parent target table. In this case, merge operations that join the staging and target tables on the same distribution key performs faster because the joining rows are collocated. To verify that the query uses a collocated join, run the query with EXPLAIN and check for DS_DIST_NONE on all the joins.
You may also want to analyze statistics on the temporary table, especially when you use it as a join table for subsequent queries. See the following code:
With this trick, you retain the functionality of temporary tables but control data placement on the cluster through distribution key assignment. You also take advantage of the columnar nature of Amazon Redshift by using column encoding.
Tip #7: Using QMR and Amazon CloudWatch metrics to drive additional performance improvements
In addition to the Amazon Redshift Advisor recommendations, you can get performance insights through other channels.
The Amazon Redshift cluster continuously and automatically collects query monitoring rules metrics, whether you institute any rules on the cluster or not. This convenient mechanism lets you view attributes like the following:
- The CPU time for a SQL statement (query_cpu_time)
- The amount of temporary space a job might ‘spill to disk’ (query_temp_blocks_to_disk)
- The ratio of the highest number of blocks read over the average (io_skew)
It also makes Amazon Redshift Spectrum metrics available, such as the number of Amazon Redshift Spectrum rows and MBs scanned by a query (spectrum_scan_row_count and spectrum_scan_size_mb, respectively). The Amazon Redshift system view SVL_QUERY_METRICS_SUMMARY shows the maximum values of metrics for completed queries, and STL_QUERY_METRICS and STV_QUERY_METRICS carry the information at 1-second intervals for the completed and running queries respectively.
The Amazon Redshift CloudWatch metrics are data points for use with Amazon CloudWatch monitoring. These can be cluster-wide metrics, such as health status or read/write, IOPS, latency, or throughput. It also offers compute node–level data, such as network transmit/receive throughput and read/write latency. At the WLM queue grain, there are the number of queries completed per second, queue length, and others. CloudWatch facilitates monitoring concurrency scaling usage with the metrics ConcurrencyScalingSeconds and ConcurrencyScalingActiveClusters.
It’s recommended to consider the CloudWatch metrics (and the existing notification infrastructure built around them) before investing time in creating something new. Similarly, the QMR metrics cover most metric use cases and likely eliminate the need to write custom metrics.
Tip #8: Federated queries connect the OLAP, OLTP and data lake worlds
The new Federated Query feature in Amazon Redshift allows you to run analytics directly against live data residing on your OLTP source system databases and Amazon S3 data lake, without the overhead of performing ETL and ingesting source data into Amazon Redshift tables. This feature gives you a convenient and efficient option for providing realtime data visibility on operational reports, as an alternative to micro-ETL batch ingestion of realtime data into the data warehouse. By combining historical trend data from the data warehouse with live developing trends from the source systems, you can gather valuable insights to drive real-time business decision making.
For example, consider sales data residing in three different data stores:
- Live sales order data stored on an Amazon RDS for PostgreSQL database (represented as “ext_postgres” in the following external schema)
- Historical sales data warehoused in a local Amazon Redshift database (represented as “local_dwh”)
- Archived, “cold” sales data older than 5 years stored on Amazon S3 (represented as “ext_spectrum”)
We can create a late binding view in Amazon Redshift that allows you to merge and query data from all three sources. See the following code:
Currently, direct federated querying is supported for data stored in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL databases, with support for other major RDS engines coming soon. You can also use the federated query feature to simplify the ETL and data-ingestion process. Instead of staging data on Amazon S3, and performing a COPY operation, federated queries allow you to ingest data directly into an Amazon Redshift table in one step, as part of a federated CTAS/INSERT SQL query.
For example, the following code shows an upsert/merge operation in which the COPY operation from Amazon S3 to Amazon Redshift is replaced with a federated query sourced directly from PostgreSQL:
For more information about setting up the preceding federated queries, see Build a Simplified ETL and Live Data Query Solution using Redshift Federated Query. For additional tips and best practices on federated queries, see Best practices for Amazon Redshift Federated Query.
Tip #9: Maintaining efficient data loads
Amazon Redshift best practices suggest using the COPY command to perform data loads of file-based data. Single-row INSERTs are an anti-pattern. The COPY operation uses all the compute nodes in your cluster to load data in parallel, from sources such as Amazon S3, Amazon DynamoDB, Amazon EMR HDFS file systems, or any SSH connection.
When performing data loads, compress the data files whenever possible. For row-oriented (CSV) data, Amazon Redshift supports both GZIP and LZO compression. It’s more efficient to load a large number of small files than one large one, and the ideal file count is a multiple of the cluster’s total slice count. Columnar data, such as Parquet and ORC, is also supported. You can achieve best performance when the compressed files are between 1MB-1GB each.
The number of slices per node depends on the cluster’s node size (and potentially elastic resize history). By ensuring an equal number of files per slice, you know that the COPY command evenly uses cluster resources and complete as quickly as possible. Query for the cluster’s current slice count with SELECT COUNT(*) AS number_of_slices FROM stv_slices;.
Another script in the amazon-redshift-utils GitHub repo, CopyPerformance, calculates statistics for each load. Amazon Redshift Advisor also warns of missing compression or too few files based on the number of slices (see the following screenshot):
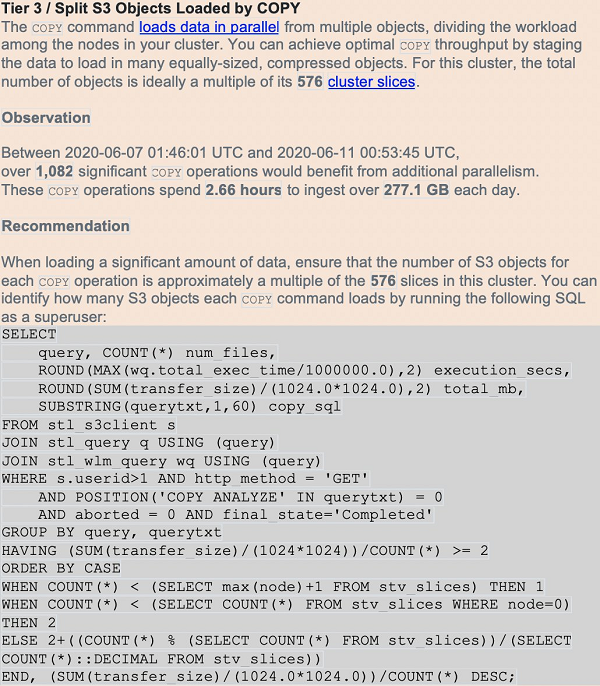
Conducting COPY operations efficiently reduces the time to results for downstream users, and minimizes the cluster resources utilized to perform the load.
Tip #10: Using the latest Amazon Redshift drivers from AWS
Because Amazon Redshift is based on PostgreSQL, we previously recommended using JDBC4 PostgreSQL driver version 8.4.703 and psql ODBC version 9.x drivers. If you’re currently using those drivers, we recommend moving to the new Amazon Redshift–specific drivers. For more information about drivers and configuring connections, see JDBC and ODBC drivers for Amazon Redshift in the Amazon Redshift Cluster Management Guide.
While rarely necessary, the Amazon Redshift drivers do permit some parameter tuning that may be useful in some circumstances. Downstream third-party applications often have their own best practices for driver tuning that may lead to additional performance gains.
For JDBC, consider the following:
- To avoid client-side out-of-memory errors when retrieving large data sets using JDBC, you can enable your client to fetch data in batches by setting the JDBC fetch size parameter or BlockingRowsMode.
- Amazon Redshift doesn’t recognize the JDBC maxRows parameter. Instead, specify a LIMIT clause to restrict the result set. You can also use an OFFSET clause to skip to a specific starting point in the result set.
For ODBC, consider the following:
- A cursor is enabled on the cluster’s leader node when useDelareFecth is enabled. The cursor fetches up to fetchsize/cursorsize and then waits to fetch more rows when the application request more rows.
- The CURSOR command is an explicit directive that the application uses to manipulate cursor behavior on the leader node. Unlike the JDBC driver, the ODBC driver doesn’t have a BlockingRowsMode mechanism.
It’s recommended that you do not undertake driver tuning unless you have a clear need. AWS Support is available to help on this topic as well.
Conclusion
Amazon Redshift is a powerful, fully managed data warehouse that can offer increased performance and lower cost in the cloud. As Amazon Redshift grows based on the feedback from its tens of thousands of active customers world-wide, it continues to become easier to use and extend its price-for-performance value proposition. Staying abreast of these improvements can help you get more value (with less effort) from this core AWS service.
We hope you learned a great deal about making the most of your Amazon Redshift account with the resources in this post.
If you have questions or suggestions, please leave a comment.
About the Authors
 Matt Scaer is a Principal Data Warehousing Specialist Solution Architect, with over 20 years of data warehousing experience, with 11+ years at both AWS and Amazon.com.
Matt Scaer is a Principal Data Warehousing Specialist Solution Architect, with over 20 years of data warehousing experience, with 11+ years at both AWS and Amazon.com.
 Manish Vazirani is an Analytics Specialist Solutions Architect at Amazon Web Services.
Manish Vazirani is an Analytics Specialist Solutions Architect at Amazon Web Services.
 Tarun Chaudhary is an Analytics Specialist Solutions Architect at AWS.
Tarun Chaudhary is an Analytics Specialist Solutions Architect at AWS.