AWS Big Data Blog
Seamless integration of data lake and data warehouse using Amazon Redshift Spectrum and Amazon DataZone
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate data lakes or warehouses—hinders visibility and cross-functional analysis. A data mesh framework empowers business units with data ownership and facilitates seamless sharing.
However, integrating datasets from different business units can present several challenges. Each business unit exposes data assets with varying formats and granularity levels, and applies different data validation checks. Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate data warehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
In this post, we explore a robust architecture pattern of a data sharing mechanism by bridging the gap between data lake and data warehouse using Amazon DataZone and Amazon Redshift.
Solution overview
Amazon DataZone is a data management service that makes it straightforward for business units to catalog, discover, share, and govern their data assets. Business units can curate and expose their readily available domain-specific data products through Amazon DataZone, providing discoverability and controlled access.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Thousands of customers use Amazon Redshift data sharing to enable instant, granular, and fast data access across Amazon Redshift provisioned clusters and serverless workgroups. This allows you to scale your read and write workloads to thousands of concurrent users without having to move or copy the data. Amazon DataZone natively supports data sharing for Amazon Redshift data assets. With Amazon Redshift Spectrum, you can query the data in your Amazon Simple Storage Service (Amazon S3) data lake using a central AWS Glue metastore from your Redshift data warehouse. This capability extends your petabyte-scale Redshift data warehouse to unbounded data storage limits, which allows you to scale to exabytes of data cost-effectively.
The following figure shows a typical distributed and collaborative architectural pattern implemented using Amazon DataZone. Business units can simply share data and collaborate by publishing and subscribing to the data assets.
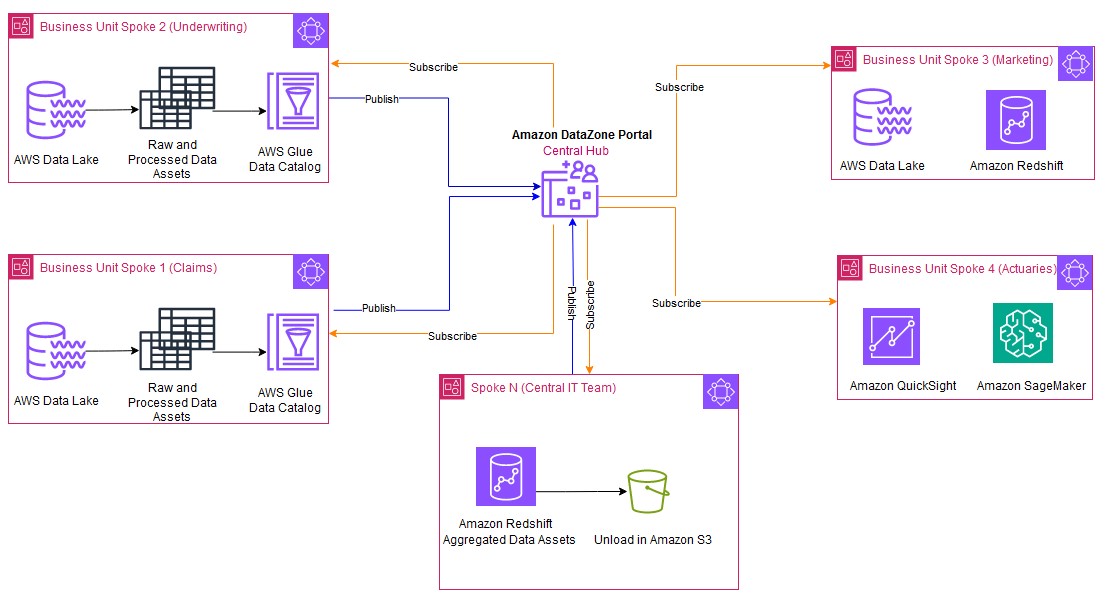
The Central IT team (Spoke N) subscribes the data from individual business units and consumes this data using Redshift Spectrum. The Central IT team applies standardization and performs the tasks on the subscribed data such as schema alignment, data validation checks, collating the data, and enrichment by adding additional context or derived attributes to the final data asset. This processed unified data can then persist as a new data asset in Amazon Redshift managed storage to meet the SLA requirements of the business units. The new processed data asset produced by the Central IT team is then published back to Amazon DataZone. With Amazon DataZone, individual business units can discover and directly consume these new data assets, gaining insights to a holistic view of the data (360-degree insights) across the organization.
The Central IT team manages a unified Redshift data warehouse, handling all data integration, processing, and maintenance. Business units access clean, standardized data. To consume the data, they can choose between a provisioned Redshift cluster for consistent high-volume needs or Amazon Redshift Serverless for variable, on-demand analysis. This model enables the units to focus on insights, with costs aligned to actual consumption. This allows the business units to derive value from data without the burden of data management tasks.
This streamlined architecture approach offers several advantages:
- Single source of truth – The Central IT team acts as the custodian of the combined and curated data from all business units, thereby providing a unified and consistent dataset. The Central IT team implements data governance practices, providing data quality, security, and compliance with established policies. A centralized data warehouse for processing is often more cost-efficient, and its scalability allows organizations to dynamically adjust their storage needs. Similarly, individual business units produce their own domain-specific data. There are no duplicate data products created by business units or the Central IT team.
- Eliminating dependency on business units – Redshift Spectrum uses a metadata layer to directly query the data residing in S3 data lakes, eliminating the need for data copying or relying on individual business units to initiate the copy jobs. This significantly reduces the risk of errors associated with data transfer or movement and data copies.
- Eliminating stale data – Avoiding duplication of data also eliminates the risk of stale data existing in multiple locations.
- Incremental loading – Because the Central IT team can directly query the data on the data lakes using Redshift Spectrum, they have the flexibility to query only the relevant columns needed for the unified analysis and aggregations. This can be done using mechanisms to detect the incremental data from the data lakes and process only the new or updated data, further optimizing resource utilization.
- Federated governance – Amazon DataZone facilitates centralized governance policies, providing consistent data access and security across all business units. Sharing and access controls remain confined within Amazon DataZone.
- Enhanced cost appropriation and efficiency – This method confines the cost overhead of processing and integrating the data with the Central IT team. Individual business units can provision the Redshift Serverless data warehouse to solely consume the data. This way, each unit can clearly demarcate the consumption costs and impose limits. Additionally, the Central IT team can choose to apply chargeback mechanisms to each of these units.
In this post, we use a simplified use case, as shown in the following figure, to bridge the gap between data lakes and data warehouses using Redshift Spectrum and Amazon DataZone.

The underwriting business unit curates the data asset using AWS Glue and publishes the data asset Policies in Amazon DataZone. The Central IT team subscribes to the data asset from the underwriting business unit.
We focus on how the Central IT team consumes the subscribed data lake asset from business units using Redshift Spectrum and creates a new unified data asset.
Prerequisites
The following prerequisites must be in place:
- AWS accounts – You should have active AWS accounts before you proceed. If you don’t have one, refer to How do I create and activate a new AWS account? In this post, we use three AWS accounts. If you’re new to Amazon DataZone, refer to Getting started.
- A Redshift data warehouse – You can create a provisioned cluster following the instructions in Create a sample Amazon Redshift cluster, or provision a serverless workgroup following the instructions in Get started with Amazon Redshift Serverless data warehouses.
- Amazon Data Zone resources – You need a domain for Amazon DataZone, an Amazon DataZone project, and a new Amazon DataZone environment (with a custom AWS service blueprint).
- Data lake asset – The data lake asset
Policiesfrom the business units was already onboarded to Amazon DataZone and subscribed by the Central IT team. To understand how to associate multiple accounts and consume the subscribed assets using Amazon Athena, refer to Working with associated accounts to publish and consume data. - Central IT environment – The Central IT team has created an environment called
env_central_teamand uses an existing AWS Identity and Access Management (IAM) role calledcustom_role, which grants Amazon DataZone access to AWS services and resources, such as Athena, AWS Glue, and Amazon Redshift, in this environment. To add all the subscribed data assets to a common AWS Glue database, the Central IT team configures a subscription target and usescentral_dbas the AWS Glue database. - IAM role – Make sure that the IAM role that you want to enable in the Amazon DataZone environment has necessary permissions to your AWS services and resources. The following example policy provides sufficient AWS Lake Formation and AWS Glue permissions to access Redshift Spectrum:
As shown in the following screenshot, the Central IT team has subscribed to the data Policies. The data asset is added to the env_central_team environment. Amazon DataZone will assume the custom_role to help federate the environment user (central_user) to the action link in Athena. The subscribed asset Policies is added to the central_db database. This asset is then queried and consumed using Athena.

The goal of the Central IT team is to consume the subscribed data lake asset Policies with Redshift Spectrum. This data is further processed and curated into the central data warehouse using the Amazon Redshift Query Editor v2 and stored as a single source of truth in Amazon Redshift managed storage. In the following sections, we illustrate how to consume the subscribed data lake asset Policies from Redshift Spectrum without copying the data.
Automatically mount access grants to the Amazon DataZone environment role
Amazon Redshift automatically mounts the AWS Glue Data Catalog in the Central IT Team account as a database and allows it to query the data lake tables with three-part notation. This is available by default with the Admin role.
To grant the required access to the mounted Data Catalog tables for the environment role (custom_role), complete the following steps:
- Log in to the Amazon Redshift Query Editor v2 using the Amazon DataZone deep link.
- In the Query Editor v2, choose your Redshift Serverless endpoint and choose Edit Connection.
- For Authentication, select Federated user.
- For Database, enter the database you want to connect to.
- Get the current user IAM role as illustrated in the following screenshot.

- Connect to Redshift Query Editor v2 using the database user name and password authentication method. For example, connect to
devdatabase using the admin user name and password. Grant usage on theawsdatacatalogdatabase to the environment user rolecustom_role(replace the value of current_user with the value you copied):
Query using Redshift Spectrum
Using the federated user authentication method, log in to Amazon Redshift. The Central IT team will be able to query the subscribed data asset Policies (table: policy) that was automatically mounted under awsdatacatalog.

Aggregate tables and unify products
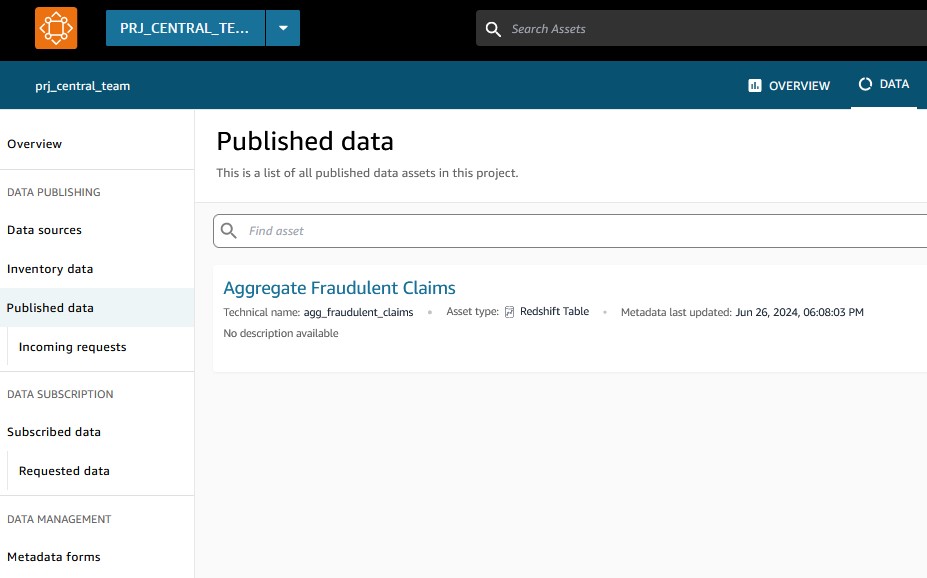
The Central IT team applies the necessary checks and standardization to aggregate and unify the data assets from all business units, bringing them at the same granularity. As shown in the following screenshot, both the Policies and Claims data assets are combined to form a unified aggregate data asset called agg_fraudulent_claims.

These unified data assets are then published back to the Amazon DataZone central hub for business units to consume them.
The Central IT team also unloads the data assets to Amazon S3 so that each business unit has the flexibility to use either a Redshift Serverless data warehouse or Athena to consume the data. Each business unit can now isolate and put limits to the consumption costs on their individual data warehouses.
Because the intention of the Central IT team was to consume data lake assets within a data warehouse, the recommended solution would be to use custom AWS service blueprints and deploy them as part of one environment. In this case, we created one environment (env_central_team) to consume the asset using Athena or Amazon Redshift. This accelerates the development of the data sharing process because the same environment role is used to manage the permissions across multiple analytical engines.
Clean up
To clean up your resources, complete the following steps:
- Delete any S3 buckets you created.
- On the Amazon DataZone console, delete the projects used in this post. This will delete most project-related objects like data assets and environments.
- Delete the Amazon DataZone domain.
- On the Lake Formation console, delete the Lake Formation admins registered by Amazon DataZone along with the tables and databases created by Amazon DataZone.
- If you used a provisioned Redshift cluster, delete the cluster. If you used Redshift Serverless, delete any tables created as part of this post.
Conclusion
In this post, we explored a pattern of seamless data sharing with data lakes and data warehouses with Amazon DataZone and Redshift Spectrum. We discussed the challenges associated with traditional data management approaches, data silos, and the burden of maintaining individual data warehouses for business units.
In order to curb operating and maintenance costs, we proposed a solution that uses Amazon DataZone as a central hub for data discovery and access control, where business units can readily share their domain-specific data. To consolidate and unify the data from these business units and provide a 360-degree insight, the Central IT team uses Redshift Spectrum to directly query and analyze the data residing in their respective data lakes. This eliminates the need for creating separate data copy jobs and duplication of data residing in multiple places.
The team also takes on the responsibility of bringing all the data assets to the same granularity and process a unified data asset. These combined data products can then be shared through Amazon DataZone to these business units. Business units can only focus on consuming the unified data assets that aren’t specific to their domain. This way, the processing costs can be controlled and tightly monitored across all business units. The Central IT team can also implement chargeback mechanisms based on the consumption of the unified products for each business unit.
To learn more about Amazon DataZone and how to get started, refer to Getting started. Check out the YouTube playlist for some of the latest demos of Amazon DataZone and more information about the capabilities available.
About the Authors
 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.