AWS Big Data Blog
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
Customers migrating from on-premises Oracle databases to AWS face a challenge: efficiently relocating large object data types (LOBs) to object storage while maintaining data integrity and performance. This challenge originates from the traditional enterprise database design where LOBs are stored alongside structured data, leading to storage capacity constraints, backup complexity, and performance bottlenecks during data retrieval and processing. LOBs, which can include images, videos, and other large files, often cause traditional data migrations to suffer from slow speeds and LOB truncation issues. These issues are particularly problematic for long-running migrations that can span several years.
In this post, we present a scalable solution that uses Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Aurora PostgreSQL-Compatible Edition, and Amazon MSK Connect. The data streaming enables data replication where modifications are sent and received in a continuous flow, allowing the target database to access and apply the changes in real time. This solution generates events for database actions such as insert, update, and delete, triggering AWS Lambda functions to download LOBs from the source Oracle database and upload them to Amazon Simple Storage Service (Amazon S3) buckets. Simultaneously, the streaming events migrate the structured data from the Oracle database to the target database while maintaining proper linking with their respective LOBs.
The complete implementation is available on GitHub, including AWS Cloud Development Kit (AWS CDK) deployment code, configuration files, and setup instructions.
Solution overview
Although traditional Oracle database migrations handle structured data effectively, they struggle with LOBs that can include images, videos, and documents. These migrations often fail due to size limitations and truncation issues, creating significant business risks, including data loss, extended downtime, and project delays that can force you to delay your cloud transformation initiatives. The problem becomes more acute during long-running migrations spanning several years, where maintaining operational continuity is critical. This solution addresses the key challenges of LOB migration, enabling continuous, long-term operations without compromising performance or reliability.
By removing the size limitations associated with traditional migration technologies, our solution provides a robust framework that helps you seamlessly relocate LOBs while facilitating data integrity throughout the process.
Our approach uses a modern streaming architecture to alleviate the traditional constraints of Oracle LOB migration. The solution includes the following core components:
- Amazon MSK – Provides the streaming infrastructure.
- Amazon MSK Connect – Using two connectors:
- Debezium Connector for Oracle as a source connector to capture row-level changes that occur in Oracle database. The connector emits change events and publishes to a Kafka source topic.
- Debezium Connector for JDBC as a sink connector to consume events from Kafka source topic and then write those events to Aurora PostgreSQL-Compatible by using a JDBC driver.
- Lambda function – Triggered by an event source mapping to Amazon MSK. The function processes events from the Kafka source topic, extracting the Oracle row primary key from each event payload. It uses this key to download the corresponding BLOB data from the source Oracle database and uploads it to Amazon S3, organizing files by primary key folders to maintain simple linking with the relational database records.
- Amazon RDS for Oracle – Amazon Relational Database Service (Amazon RDS) for Oracle is used as the source database to simulate an on-premises Oracle database.
- Aurora PostgreSQL-Compatible – Used as the target database for migrated data.
- Amazon S3 – Used as object storage for storing the BLOB data from source database.
The following diagram shows the Oracle LOB data migration architecture solution.
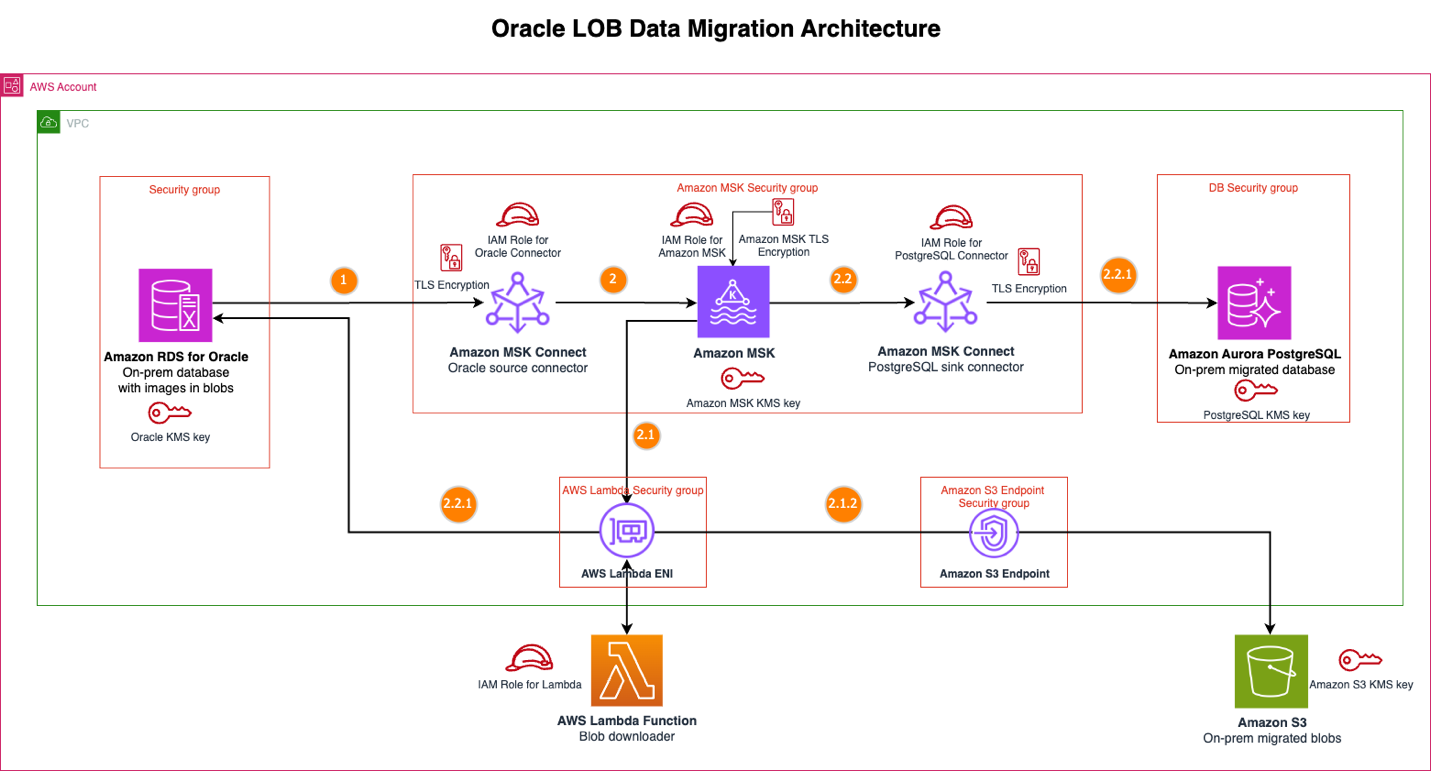
Message flow
When data changes occur in the source Amazon RDS for Oracle database, the solution executes the following sequence, moving through event detection and publication, BLOB processing with Lambda, and structured data processing:
- The Oracle source connector captures the change data capture (CDC) events, including the change to BLOB data column. This connector configures the BLOB data column to exclude from the Kafka event to optimize the Kafka payload.
- The connector publishes this event to an MSK topic.
- The MSK event triggers the BLOB Downloader Lambda function for the CDC events.
- The Lambda function examines two key conditions: the Debezium event code (specifically checking for create (c) or update(u)) and the configured list of Oracle BLOB table names along with their column names. When a Kafka message matches both the configured table list and valid Debezium events, the Lambda function initiates the BLOB data download from the Oracle source using the primary key and table name; otherwise, the function bypasses the BLOB download process. This selective approach makes sure the Lambda function only executes SQL queries when processing Kafka messages for tables containing BLOB data, optimizing database interactions.
- The Lambda function uploads the BLOB to Amazon S3, organizing by primary key folders with unique object names, which enables linking between structured database records and their corresponding BLOB data in Amazon S3.
- The PostgreSQL sink connector receives the event from the MSK topic.
- The connector applies these changes to the Aurora PostgreSQL database for the Oracle database changes except the BLOB data column. The BLOB data column is excluded by the Oracle source connector.
- The MSK event triggers the BLOB Downloader Lambda function for the CDC events.
Key benefits
The solution offers the following key advantages:
- Cost optimization and licensing – Our approach offers significant cost optimization benefits by reducing the overall size of your database and alleviating your need for expensive licenses associated with traditional databases and replication technologies. By decoupling LOB storage from the database and using Amazon S3, you can reduce your overall database footprint and reduce costs associated with traditional licensing and replication technologies. The streaming architecture also minimizes your infrastructure overhead during long-running migrations.
- Avoids size constraints and migration failures – Traditional migration tools often impose size limitations on LOB transfers, leading to truncation issues and failed migrations. This solution removes those constraints entirely, so you can migrate LOBs of different sizes while maintaining data integrity. The event-driven architecture enables near real-time data replication, allowing your source systems to remain operational during migration.
- Business continuity and operational excellence – Changes flow continuously to your target environment, allowing for business continuity. The solution preserves relationships between structured database records and their corresponding LOBs through primary key-based organization in Amazon S3, allowing for referential integrity while providing the flexibility of object storage for large files.
- Architectural advantages – Storing LOBs in Amazon S3 while maintaining structured data in Aurora PostgreSQL-Compatible creates a clear separation. This architecture simplifies your backup and recovery operations, improves query performance on structured data, and provides flexible access patterns for binary objects through Amazon S3.
Implementation best practices
Consider the following best practices when implementing this solution:
- Start small and scale gradually – To implement this solution, start with a pilot project using non-production data to validate your approach before committing to full-scale migration. This gives you a chance to work out issues in a controlled environment and refine your configuration without impacting production systems.
- Monitoring – Set up comprehensive monitoring through Amazon CloudWatch to track key metrics like Kafka lag, Lambda function errors, and replication latency. Establish alerting thresholds early so you can catch and resolve issues quickly before they impact your migration timeline. Size your MSK cluster based on expected CDC volume and configure Lambda reserved concurrency to handle peak loads during initial data synchronization.
- Security – For security, use encryption in transit and at rest for both structured data and LOBs, and follow the principle of least privilege when setting up AWS Identity and Access Management (IAM) roles and policies for your MSK cluster, Lambda functions, S3 buckets, and database instances. Document your schema mappings between Oracle and Aurora PostgreSQL-Compatible, including how database records link to their corresponding LOBs in Amazon S3.
- Testing and preparation – Before you go live, test your failover and recovery procedures thoroughly. Validate scenarios like Lambda function failures, MSK cluster issues, and network connectivity problems to ensure you’re prepared for potential issues. Finally, remember that this streaming architecture maintains eventual consistency between your source and target systems, so there might be brief lag times during high-volume periods. Plan your cutover strategy with this in mind.
Limitations and considerations
Although this solution provides a robust approach for migrating Oracle databases with LOBs to AWS, there are several inherent constraints to understand before implementation.
This solution requires network connectivity between your source Oracle database and AWS environment. For on-premises Oracle databases, you must establish AWS Direct Connect or VPN connectivity before deployment. Network bandwidth directly impacts replication speed and overall migration performance, so your connection must be able to handle the expected volume of CDC events and LOB transfers.
The solution uses Debezium Connector for Oracle as the source connector and Debezium Connector for JDBC as the sink connector. This architecture is specifically designed for your Oracle-to-PostgreSQL migrations. Other database combinations require different connector configurations or might not be supported by the current implementation. Migration throughput is also constrained by your MSK cluster capacity and Lambda concurrency limits. You can also exceed AWS service quotas for large-scale migrations and you might need to request quota increases through AWS Enterprise Support.
Conclusion
In this post, we presented a solution that addresses the critical challenge of migrating your large binary objects from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.
Ready to transform your Oracle migration strategy? Visit the GitHub repository, where you will find the complete AWS CDK deployment code, configuration files, and step-by-step instructions to get started.