AWS Big Data Blog
Tag: Amazon Redshift

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.
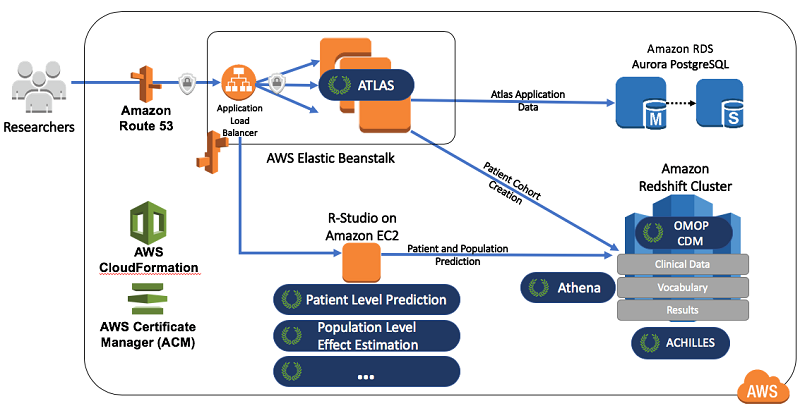
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.

Amazon Redshift – 2017 Recap
We have been busy adding new features and capabilities to Amazon Redshift, and we wanted to give you a glimpse of what we’ve been doing over the past year. In this article, we recap a few of our enhancements and provide a set of resources that you can use to learn more and get the most out of your Amazon Redshift implementation.

How I built a data warehouse using Amazon Redshift and AWS services in record time
Over the years, I have developed and created a number of data warehouses from scratch. Recently, I built a data warehouse for the iGaming industry single-handedly. To do it, I used the power and flexibility of Amazon Redshift and the wider AWS data management ecosystem. In this post, I explain how I was able to build a robust and scalable data warehouse without the large team of experts typically needed.

Top 9 Best Practices for High-Performance ETL Processing Using Amazon Redshift
When migrating from a legacy data warehouse to Amazon Redshift, it is tempting to adopt a lift-and-shift approach, but this can result in performance and scale issues long term. This post guides you through the following best practices for ensuring optimal, consistent runtimes for your ETL processes.
Combine Transactional and Analytical Data Using Amazon Aurora and Amazon Redshift
A few months ago, we published a blog post about capturing data changes in an Amazon Aurora database and sending it to Amazon Athena and Amazon QuickSight for fast analysis and visualization. In this post, I want to demonstrate how easy it can be to take the data in Aurora and combine it with data in Amazon Redshift using Amazon Redshift Spectrum.

Collect Data Statistics Up to 5x Faster by Analyzing Only Predicate Columns with Amazon Redshift
After loading new data into an Amazon Redshift cluster, statistics need to be re-computed to guarantee performant query plans. By learning which column statistics are actually being used by the customer’s workload and collecting statistics only on those columns, Amazon Redshift is able to significantly reduce the amount of time needed for table maintenance during data loading workflows.

Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production
This is a guest post by Rafi Ton, founder and CEO of NUVIAD. The ability to provide fresh, up-to-the-minute data to our customers and partners was always a main goal with our platform. We saw other solutions provide data that was a few hours old, but this was not good enough for us. We insisted on providing the freshest data possible. For us, that meant loading Amazon Redshift in frequent micro batches and allowing our customers to query Amazon Redshift directly to get results in near real time. The benefits were immediately evident. Our customers could see how their campaigns performed faster than with other solutions, and react sooner to the ever-changing media supply pricing and availability. They were very happy.
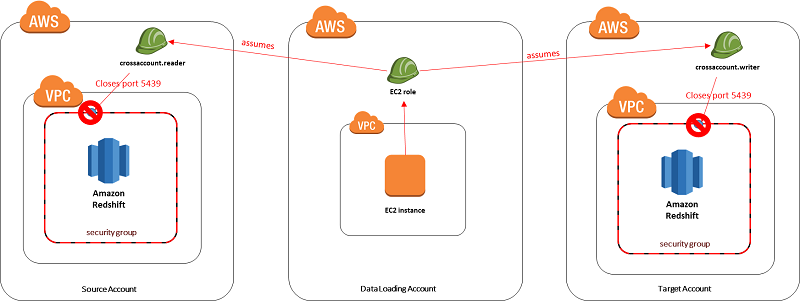
Create an Amazon Redshift Data Warehouse That Can Be Securely Accessed Across Accounts
Data security is paramount in many industries. Organizations that shift their IT infrastructure to the cloud must ensure that their data is protected and that the attack surface is minimized. This post focuses on a method of securely loading a subset of data from one Amazon Redshift cluster to another Amazon Redshift cluster that is located in a different AWS account.

Federate Database User Authentication Easily with IAM and Amazon Redshift
Managing database users though federation allows you to manage authentication and authorization procedures centrally. Amazon Redshift now supports database authentication with IAM, enabling user authentication though enterprise federation. In this post, I demonstrate how you can extend the federation to enable single sign-on (SSO) to the Amazon Redshift data warehouse.