AWS Big Data Blog
How I built a data warehouse using Amazon Redshift and AWS services in record time
April 2024: The content of this post is no longer relevant as AWS Data Pipeline is no longer available.
| February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that AWS Data Pipeline service is in maintenance mode and we are not planning to expand the service to new regions. For information about migrating from AWS Data Pipeline, please refer to the AWS Data Pipeline migration documentation. |
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
 This is a customer post by Stephen Borg, the Head of Big Data and BI at Cerberus Technologies.
This is a customer post by Stephen Borg, the Head of Big Data and BI at Cerberus Technologies.
Cerberus Technologies, in their own words: Cerberus is a company founded in 2017 by a team of visionary iGaming veterans. Our mission is simple – to offer the best tech solutions through a data-driven and a customer-first approach, delivering innovative solutions that go against traditional forms of working and process. This mission is based on the solid foundations of reliability, flexibility and security, and we intend to fundamentally change the way iGaming and other industries interact with technology.
Over the years, I have developed and created a number of data warehouses from scratch. Recently, I built a data warehouse for the iGaming industry single-handedly. To do it, I used the power and flexibility of Amazon Redshift and the wider AWS data management ecosystem. In this post, I explain how I was able to build a robust and scalable data warehouse without the large team of experts typically needed.
In two of my recent projects, I ran into challenges when scaling our data warehouse using on-premises infrastructure. Data was growing at many tens of gigabytes per day, and query performance was suffering. Scaling required major capital investment for hardware and software licenses, and also significant operational costs for maintenance and technical staff to keep it running and performing well. Unfortunately, I couldn’t get the resources needed to scale the infrastructure with data growth, and these projects were abandoned. Thanks to cloud data warehousing, the bottleneck of infrastructure resources, capital expense, and operational costs have been significantly reduced or have totally gone away. There is no more excuse for allowing obstacles of the past to delay delivering timely insights to decision makers, no matter how much data you have.
With Amazon Redshift and AWS, I delivered a cloud data warehouse to the business very quickly, and with a small team: me. I didn’t have to order hardware or software, and I no longer needed to install, configure, tune, or keep up with patches and version updates. Instead, I easily set up a robust data processing pipeline and we were quickly ingesting and analyzing data. Now, my data warehouse team can be extremely lean, and focus more time on bringing in new data and delivering insights. In this post, I show you the AWS services and the architecture that I used.
Handling data feeds
I have several different data sources that provide everything needed to run the business. The data includes activity from our iGaming platform, social media posts, clickstream data, marketing and campaign performance, and customer support engagements.
To handle the diversity of data feeds, I developed abstract integration applications using Docker that run on Amazon EC2 Container Service (Amazon ECS) and feed data to Amazon Kinesis Data Streams. These data streams can be used for real time analytics. In my system, each record in Kinesis is preprocessed by an AWS Lambda function to cleanse and aggregate information. My system then routes it to be stored where I need on Amazon S3 by Amazon Kinesis Data Firehose. Suppose that you used an on-premises architecture to accomplish the same task. A team of data engineers would be required to maintain and monitor a Kafka cluster, develop applications to stream data, and maintain a Hadoop cluster and the infrastructure underneath it for data storage. With my stream processing architecture, there are no servers to manage, no disk drives to replace, and no service monitoring to write.
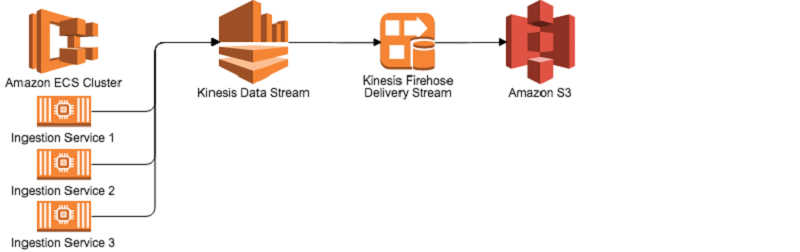
Setting up a Kinesis stream can be done with a few clicks, and the same for Kinesis Firehose. Firehose can be configured to automatically consume data from a Kinesis Data Stream, and then write compressed data every N minutes to Amazon S3. When I want to process a Kinesis data stream, it’s very easy to set up a Lambda function to be executed on each message received. I can just set a trigger from the AWS Lambda Management Console, as shown following.
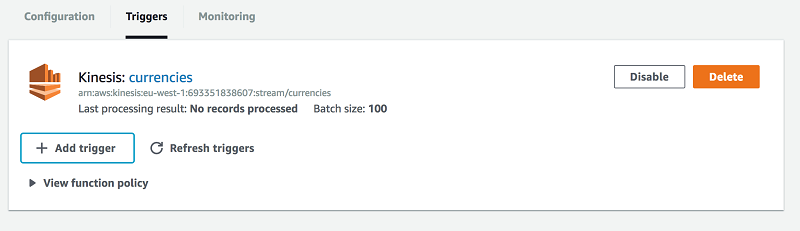
I also monitor the duration of function execution using Amazon CloudWatch and AWS X-Ray.
Regardless of the format I receive the data from our partners, I can send it to Kinesis as JSON data using my own formatters. After Firehose writes this to Amazon S3, I have everything in nearly the same structure I received but compressed, encrypted, and optimized for reading.
This data is automatically crawled by AWS Glue and placed into the AWS Glue Data Catalog. This means that I can immediately query the data directly on S3 using Amazon Athena or through Amazon Redshift Spectrum. Previously, I used Amazon EMR and an Amazon RDS–based metastore in Apache Hive for catalog management. Now I can avoid the complexity of maintaining Hive Metastore catalogs. Glue takes care of high availability and the operations side so that I know that end users can always be productive.
Working with Amazon Athena and Amazon Redshift for analysis
I found Amazon Athena extremely useful out of the box for ad hoc analysis. Our engineers (me) use Athena to understand new datasets that we receive and to understand what transformations will be needed for long-term query efficiency.
For our data analysts and data scientists, we’ve selected Amazon Redshift. Amazon Redshift has proven to be the right tool for us over and over again. It easily processes 20+ million transactions per day, regardless of the footprint of the tables and the type of analytics required by the business. Latency is low and query performance expectations have been more than met. We use Redshift Spectrum for long-term data retention, which enables me to extend the analytic power of Amazon Redshift beyond local data to anything stored in S3, and without requiring me to load any data. Redshift Spectrum gives me the freedom to store data where I want, in the format I want, and have it available for processing when I need it.
To load data directly into Amazon Redshift, I use AWS Data Pipeline to orchestrate data workflows. I create Amazon EMR clusters on an intra-day basis, which I can easily adjust to run more or less frequently as needed throughout the day. EMR clusters are used together with Amazon RDS, Apache Spark 2.0, and S3 storage. The data pipeline application loads ETL configurations from Spring RESTful services hosted on AWS Elastic Beanstalk. The application then loads data from S3 into memory, aggregates and cleans the data, and then writes the final version of the data to Amazon Redshift. This data is then ready to use for analysis. Spark on EMR also helps with recommendations and personalization use cases for various business users, and I find this easy to set up and deliver what users want. Finally, business users use Amazon QuickSight for self-service BI to slice, dice, and visualize the data depending on their requirements.
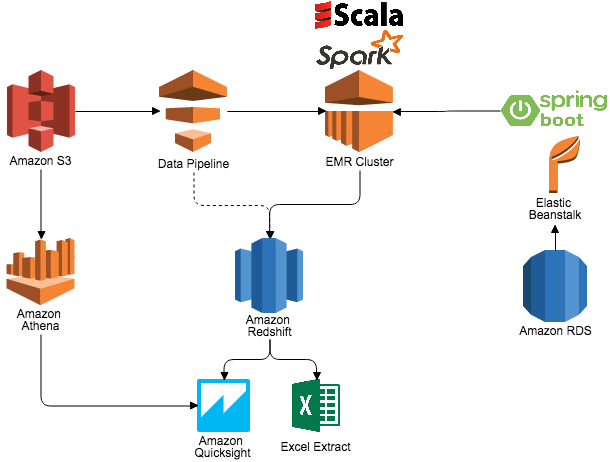
Each AWS service in this architecture plays its part in saving precious time that’s crucial for delivery and getting different departments in the business on board. I found the services easy to set up and use, and all have proven to be highly reliable for our use as our production environments. When the architecture was in place, scaling out was either completely handled by the service, or a matter of a simple API call, and crucially doesn’t require me to change one line of code. Increasing shards for Kinesis can be done in a minute by editing a stream. Increasing capacity for Lambda functions can be accomplished by editing the megabytes allocated for processing, and concurrency is handled automatically. EMR cluster capacity can easily be increased by changing the master and slave node types in Data Pipeline, or by using Auto Scaling. Lastly, RDS and Amazon Redshift can be easily upgraded without any major tasks to be performed by our team (again, me).
In the end, using AWS services including Kinesis, Lambda, Data Pipeline, and Amazon Redshift allows me to keep my team lean and highly productive. I eliminated the cost and delays of capital infrastructure, as well as the late night and weekend calls for support. I can now give maximum value to the business while keeping operational costs down. My team pushed out an agile and highly responsive data warehouse solution in record time and we can handle changing business requirements rapidly, and quickly adapt to new data and new user requests.
Additional Reading
If you found this post useful, be sure to check out Deploy a Data Warehouse Quickly with Amazon Redshift, Amazon RDS for PostgreSQL and Tableau Server and Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift.

About the Author
 Stephen Borg is the Head of Big Data and BI at Cerberus Technologies. He has a background in platform software engineering, and first became involved in data warehousing using the typical RDBMS, SQL, ETL, and BI tools. He quickly became passionate about providing insight to help others optimize the business and add personalization to products. He is now the Head of Big Data and BI at Cerberus Technologies.
Stephen Borg is the Head of Big Data and BI at Cerberus Technologies. He has a background in platform software engineering, and first became involved in data warehousing using the typical RDBMS, SQL, ETL, and BI tools. He quickly became passionate about providing insight to help others optimize the business and add personalization to products. He is now the Head of Big Data and BI at Cerberus Technologies.
Audit History
Last reviewed and updated in April 2024 by John Felix | Associate Solutions Architect